

科学饮食是健康基石。不健康饮食结构是心血管疾病、糖尿病、神经退行性疾病、炎症性肠病等多种慢性代谢疾病的罪魁祸首,严重危害人民健康,降低人民生活质量[1-4]。研究显示:2017年全球约1 100万人的死亡归因于膳食风险因素,其中钠摄入量高、全谷物摄入量低和水果摄入量低是导致死亡的主要膳食风险因素。中国因饮食问题造成的死亡人数位居榜首[5]。膳食调查是开展营养监测与评估、膳食指导和干预、个体营养需要量研究以及膳食指南制订等的重要基础。准确、高效地收集膳食摄入信息,科学、客观、全面地评价膳食整体质量,明确影响膳食质量水平的各种因素,对于进一步有针对性地开展精准膳食指导和个性化干预、促进全民体质健康具有重要意义[6-9]。
传统营养流行病学开展人群膳食营养监测,研究食物摄入量与疾病的关系,主要依靠食物频率问卷、24 h膳食回顾法、膳食记录法等自我报告工具进行评估[10]。尽管大量研究已经证实这些膳食调查方法之间存在较强的一致性,但由于人为主观判断、回忆偏差等引起的系统和随机测量误差的存在,使得这些工具的可靠性和有效性受到质疑[11-13],并在一定程度上降低了食物摄入评估的准确性,不能真实反映居民膳食质量水平[14-15]。
除了用于能量代谢的双重标记水和用于蛋白质摄入的24 h尿氮等生物标志物以外,在大健康和大数据时代背景下,高通量代谢组学技术的飞速发展为解决食品营养健康科学问题带来机遇。越来越多的研究采用代谢组学技术分析短期或长期习惯性饮食引起的人体血液、尿液等生物样本中代谢物组的变化,筛选、鉴定能够表征特定食物或营养素摄入量的膳食生物标志物,用于膳食营养的量化[16]。膳食生物标志物是一类能够反映膳食摄入或营养状况、可测量且可量化的生物学指标[9]。合理运用这些膳食生物标志物评估特定的食物摄入和饮食暴露,不仅可以提升传统自我报告式膳食计量手段对食物估量的准确性和精确度[9,17 -19],还能够在一定程度上客观描述食物摄入与机体反应之间的量效关系,有助于理解膳食摄入对人体营养和健康状况的影响机制[20-24],是挖掘膳食因子功能特性和实现精准营养的重要手段[25]。
然而,高通量代谢组学技术产生的多元、高维、复杂数据也为膳食生物标志物的发现和验证工作带来巨大挑战。液相或气相连用质谱、核磁共振是常用的营养代谢组学分析平台,在营养与疾病研究领域应用广泛。高效且科学地开展针对代谢组学数据的统计分析,获得可在现实环境中应用的稳健结果,是推动膳食生物标志物研究及应用的必要条件[26],对明确可用于公共卫生和临床研究、涵盖更广泛食物成分、标准化程度高、重复性强的膳食生物标志物至关重要。
本文总结近10年基于大规模人群队列研究和随机对照饮食干预研究得到的有关谷物、果蔬类、肉类、鱼类、乳制品、坚果类摄入的膳食生物标志物的研究结果(表1),梳理了特定膳食生物标志物与35种代谢疾病(心血管疾病、冠心病、缺血性中风、心力衰竭、心肌梗死、溃疡性结肠炎、阿尔兹海默症、前列腺癌、多囊卵巢综合征、燃煤性骨骼氟中毒、黄斑病变、注意力缺失症、乳糜泻、代谢性心肌病、2型糖尿病、创伤性脑损伤、髋部骨折、外周动脉疾病、心脏性猝死、非酒精性脂肪性肝炎、高血压、失能性痴呆症、多发性硬化症、肥胖症、帕金森病、心肌肥厚及纤维化、1型糖尿病、急性呼吸道感染、慢性肾脏病、结肠癌、先天性痴呆症、乳腺早衰、房颤、冠状动脉粥样硬化、牙周炎)发病风险的相关关系,综述了当前基于代谢组学发现生物标志物的现状及挑战,着重强调了膳食生物标志物揭秘饮食与健康关系的巨大潜力和研究前景。
表1 膳食生物标志物总结Tab.1 Summary of dietary biomarkers |
| 食物种类 | 生物样本 | 鉴定方法 | 生物标志物 |
|---|---|---|---|
| 全谷物 | 血液、尿液、 脂肪组织 | LC-MS/MS、 GC-MS、LC-MS、 UPLC-MS、HPLC、 HPLC-MS、 HPLC-CEAD、 LC-QTOF-MS | alkylresorcinols (ARs)[27-36] 3-(3,5-dihydroxyphenyl)-1-propanoicacid (DHPPA)[36-40] 3,5-dihydroxycinnamic acid (DHCA)[41-42] 3,5-dihydroxy-benzoic acid (DHBA)[38] 2-(3,5-dihydroxybenzamido) acetic acid[41] 5-(3,5-dihydroxyphenyl) pentanoic acid (DHPPTA)[41-42] pipecolic acid betaine[43-44] tetradecanedioic acid[43] avenanthramides (AVNs)[45-46] avenacosides (AVEs)[47] |
| 果蔬类 | 血液、尿液 | UPLC-MS/MS、HPLC-MS/MS、HPLC-DAD-MS、UPLC-QTOF、 UPLC-ESI-MS-MS、 NMR、MSI-CE-MS、 LC-MS/MS、UHPLC-QTOF-MS、HPLC-DAD、 GC-MS、HPLC、 CE-TOF-MS | aalliin[48-50] aS-allylcysteine[50-51] aN-acetylalliin[50] dhesperetin[52-54] dnaringenin[52-54] dhesperidin[52-54] dnarringin[52-54] dstachydrine[50] dproline betaine[52,55 -56] ephloretin[54,57 -58] ephloretin glucuronide[58] ephloretin glucuronide sulfate[58] gdes-amino arginine pentenol ester[59] gD/L-malic acid ester of cis-p-coumarate[59] gD/L-malic acid ester of trans-p-coumarate[59] bergothioneine[48,50,60] ccyanidin-3-glucoside[61] fdopamine sulfate[53,62 -63] carotenoids[64-67] threonate[68] galactarate[68] hippurate[69] hippuric acid[56] 3-carboxy-4-methyl-5-propyl-2-furanpropanoic acid (CMPF)[60] |
| 肉类 | 血液、尿液 | MSI-CE-MS、 FIA-MS/MS、 CE-TOF-MS、 UPLC-MS/MS、 UHPLC-QTOF-MS、 LC-MS/MS、 NMR、MS、LC-MS | hsyringol sulfate[70] jpiperine[71] ianserine[70,72] i3-methylhistidine (3-MH)[56,73] iguanidoacetate[74] carnosine[70] acetylcarnitine[73] vanillylmandelate[69] 4-hydroxyproline propionylcarnitine (PPC)[60,68,73] |
| 鱼类及贝类 | 血液、尿液 | MSI-CE-MS、 CE-TOF-MS、 UHPLC、HPLC、 UPLC-MS/MS、 GC-MS、LC-MS/MS、 MS/MS、 HPLC-ICP-MS | trimetlylamine-N-oxide (TMAO)[56,68,72,75 -76] 3-carboxy-4-methyl-5-propyl-2-furanpropanoic acid (CMPF)[50,77 -78] docosahexaenoic (DHA)[35,50,78] eicosapentaenoic (EPA)[35,50,60,79] docosapentaenoic acid (DPA)[35] acetylcarnitine[72] arsenobetaine[80] 2-hydroxybutyrate[78] erythrocyte mercury[80] 1-methylhistidine[76] |
| 乳制品 | 血液、尿液、 脂肪组织、粪便 | MS/MS、GC-MS、HILIC、GC、LC-MS、CE-TOF-MS、 1H NMR | pentadecanoacid[60,81 -85] heptadecanoic acid[82,84 -85] trans-palmitoleic acid[82,85 -86] galactonic acid[87] threonate[68] phenylalanine[68] myristic acid[60,84] kgalactonate[68,88] klactose[88] kgalactonate[88] kLewis A trisaccharide (LeA)[87] kblood group H disaccharide (BGH)[87] lpantothenate[84] lproline[84,88 -89] l3-phenyllactic acid[88-89] |
| 豆类 | 血液、尿液 | GC-MS、1H NMR、LC-MS、UPLC- MS/MS、MSI-CE-MS、ELISA | genistein[90-91] daidzein[90-91] S-methylcysteine[48,92] pipecolic acid[92] tryptophan betaine[56] |
| 坚果 | 血液、尿液、粪便 | LC-MS、HPLC- MS、GC-MS、 HPLC-DAD-MS、 HPLC、ELISA、LC-ESI-QTOF-MS、 LC-MS/MS | mα-linolenic acid[93-94] mγ-tocopherol[95] selenium[96] α-tocopherol[97] murolithins[95] murolithin A glucuronide[98] lutein-zeaxanthin[99-100] m5-hydroxyindoleacetic acid (5-HIAA)[101] tryptophan betaine[56,78] 5-hydroxyindole-3acetic acid[102] |
注:a.大蒜及葱属类;b.蘑菇;c.浆果类;d.柑橘类;e.苹果;f.香蕉;g.菠菜;h.熏肉;i.鸡肉;j.香肠;k.牛奶;l.奶酪;m.核桃。 |
1 不同种类食物的膳食生物标志物
1.1 全谷物生物标志物
烷基间苯二酚(alkylresorcinols,ARs)是一种特殊的两亲性酚类酯类化合物,是1,3-间苯二酚苯环5位被含奇数碳原子的烷基取代的一类衍生物的总称。烷基间苯二酚特异性地存在于全谷物小麦、黑麦、黑小麦的麸皮中[103],可作为全谷物小麦和黑麦摄入的膳食生物标志物应用于人群队列研究[104]。丹麦DCH队列、冰岛PREWICE Ⅱ队列、芬兰KIHD队列以及美国postmenopausal women with coronary stenosis队列的前瞻性研究表明,血浆烷基间苯二酚浓度与全谷物摄入之间存在显著关联,且两者之间呈剂量依赖性[27-29,43]。Biskup等[30]基于斯堪的纳维亚人群建立的巢式病例对照研究表明,血浆ARs中C17∶0与C21∶0的比例可以表征全谷物黑麦与小麦的摄入比例,证明不同链长烷基间苯二酚可特异性地反映不同种类全谷物的摄入。基于瑞典COSM-C和SMCC队列的横断面研究结果,脂肪组织中烷基间苯二酚含量可以表征全谷物黑麦的长期摄入量[31]。目前,烷基间苯二酚已经被广泛应用于随机对照研究中受试者对全谷物干预食物的依从性检验,不同人群对照组和干预组的空腹血浆中烷基间苯二酚浓度存在显著差异,证实受试者对全谷物食物(如全谷面包、早餐麦片、全谷面食、蒸粗麦粉和谷物什锦早餐能量棒)摄入具有良好依从性[32-35]。此外,3,5-二羟基苯甲酸(3,5-dihydroxy-benzoic acid,DHBA)、3,5-二羟基苯丙酸(3-(3,5-dihydroxyphenyl)-1-propanoicacid,DHPPA)、5-(3,5-二羟基苯基)戊酸(5-(3,5-dihydroxyphenyl) pentanoic acid,DHPPTA)等多种烷基间苯二酚代谢物以及哌啶酸甜菜碱(pipecolic acid betaine)也可作为全谷物小麦和黑麦的膳食生物标志物[37-44]。
燕麦的特有膳食生物标志物主要有燕麦蒽酰胺(avenanthramides,AVNs)和燕麦皂苷(avenacosides,AVEs)。燕麦蒽酰胺是一系列由羟基肉桂酸及其衍生物和邻氨基苯甲酸及其衍生物通过酰胺键相连接而成的酚类化合物[105],其中较常见的有燕麦蒽酰胺A(avenacoside A)、燕麦蒽酰胺B(avenacoside B)和燕麦蒽酰胺C(avenacoside C)。Zhang等[45]发现16名参与者在食用不同燕麦蒽酰胺含量的燕麦饼干后,血浆燕麦蒽酰胺含量显著升高。Schar等[46]利用超高液相色谱对7名食用了60 g燕麦麸的受试者进行定时尿样分析,发现受试者8 h内的尿液中主要代谢物包括香草酸、4-羟基和3-羟基硫嘌呤酸、苯甲酸和阿魏酸的硫酸盐结合体,且含量显著高于对照组。Wang等[47]研究发现,12名志愿者在短期内摄入燕麦后,其尿液中燕麦特有的2种甾体糖苷AVE-A和AVE-B浓度显著升高,且在5 h内二者同时达到最大排泄率。
1.2 果蔬类生物标志物
类胡萝卜素(carotenoids)是表征果蔬类摄入水平的典型生物标志物[106],主要包括β-胡萝卜素、β-隐黄素、α-胡萝卜素、番茄红素、叶黄素和玉米黄质。Bacchetti等[64]研究发现,果蔬摄入量与血浆类胡萝卜素浓度高度相关(n=83),女性血浆叶黄素和β-胡萝卜素含量平均值显著高于男性,其果蔬摄入量也显著高于男性。Burrows等[65]发现,类胡萝卜素摄入量与血浆α-胡萝卜素、β-胡萝卜素、叶黄素和玉米黄质浓度显著相关(n=38)。随机对照研究结果同样表明,果蔬摄入量较高组的血浆α-胡萝卜素、β-胡萝卜素、叶黄素和玉米黄质含量显著增加[66]。Lampe等[67]基于美国WHI队列(n=153)开展干预研究,发现血清α-胡萝卜素、β-胡萝卜素、叶黄素、玉米黄质以及番茄红素含量也可表征果蔬摄入水平,其中α-胡萝卜素含量与果蔬摄入水平相关性最强,两者具有剂量依赖性。
黄酮类化合物,如橙皮素(hesperetin)、橙皮苷(hesperidin)、柚皮素(naringenin)和柚皮苷(naringin),是柑橘类水果中主要的生物活性物质。血液和尿液中柑橘类黄酮化合物含量与柑橘类水果摄入量高度相关,但由于其半衰期较短,只能作为定性类短期生物标志物[52-54]。Saenger等[52]发现32名志愿者摄入橙汁后,尿液中的脯氨酸甜菜碱(proline betaine)含量与橙汁摄入量显著正相关,且其脯氨酸甜菜碱浓度在干预24~48 h后仍显著高于对照组,表明其或可作为表征橙汁摄入的长期生物标志物。Gibbons等[55]基于爱尔兰NANS队列的研究结果显示,尿液中的脯氨酸甜菜碱含量可预测柑橘类摄入量,且预测量与膳食问卷结果一致性强。目前,脯氨酸甜菜碱也被确定为柑橘类水果、橙汁和果汁中最常见的生物标志物[50,60,78,107-108]。Desouza等[56]基于3个孕妇前瞻性出生队列(START队列、FAMILY队列和CHILD队列)开展横断面研究,同样证实了血清脯氨酸甜菜碱含量与柑橘类水果、果汁摄入量的相关性。
此外,硫酸多巴胺(dopamine sulfate)在不同人群血液和尿液中的浓度与香蕉摄入量高度相关,可作为香蕉的特异性生物标志物[53,62 -63]。Zamora等[54]基于欧洲EPIC队列研究发现,血清中根皮素(phloretin)含量可有效反映苹果摄入量(n=475)。干预研究中也发现,摄入苹果后尿液中根皮素[57]、根皮素葡萄糖醛酸苷(phloretin glucuronide)和根皮素葡萄糖醛酸苷硫酸酯(phloretin glucuronide sulfate)的含量[58]与苹果摄入量显著正相关。基于美国DAS队列、英国TwinsUK队列和美国CPS-Ⅱ队列的研究发现,麦角硫因(ergothioneine)是蘑菇的可靠生物标志物[48,50,60];蒜氨酸(alliin)和S-烯丙基半胱氨酸(S-allylcysteine)是葱属类蔬菜的特异性生物标志物[48-51]。
1.3 肉类和鱼类生物标志物
肽、氨基酸及其衍生物,如乙酰肉碱(acetylcarnitine)、4-羟脯氨酸(4-hydroxyproline)、肌肽(carnosine)、鹅肌肽(anserine)、3-甲基组氨酸(3-methylhistidine,3-MH)和胍基乙酸酯(guanidoacetate),或可作为肉类摄入的膳食生物标志物[60,68,70,73-74]。Pallister等[60]分析3 500多名女性双胞胎受试者的空腹血样,结果显示血浆4-羟脯氨酸浓度与红肉(主要包括猪肉、羊肉、牛肉)摄入显著相关。肌肽、鹅肌肽、Ⅱ-甲基组氨酸以及Ⅱ-甲基组氨酸与T-甲基组氨酸的比率可表征不同肉类的摄入量[73]。食用鸡肉或加工肉类的人群血浆鹅肌肽浓度最高,且3-甲基组氨酸特异性表征家禽类摄入量,鹅肌肽和3-甲基组氨酸可能是鸡肉类摄入的特异性生物标志物[72]。红肉、鸡肉和鸡蛋摄入量与血清3-甲基组氨酸含量正相关[56,68]。Yin等[74]对10名志愿者进行3周的饮食干预,发现胍基乙酸酯含量随着鸡肉摄入量的增加而显著增加。
二十二碳六烯酸(docosahexaenoic,DHA)、二十碳五烯酸(eicosapentaenoic,EPA)和二十二碳五烯酸(docosapentaenoic acid,DPA)是鱼油中含量最丰富的ω-3多不饱和脂肪酸。二十二碳六烯酸和二十碳五烯酸可作为鱼类摄入的膳食生物标志物[50,78-79]。不仅如此,鱼类呋喃脂肪酸含量较高[109-110],3-羧基-4-甲基-5-丙基-2-呋喃丙酸(3-carboxy-4-methyl-5-propyl-2-furanpropanoic acid,CMPF)是呋喃脂肪酸在人体中形成的代谢产物。Hanhineva等[77]对106名代谢综合征患者进行鱼类饮食干预,干预组血液CMPF含量与鱼类摄入量密切相关,但与其他食物的摄入量无关,说明CMPF是鱼类摄入的高度特异性生物标志物。三甲胺-N-氧化物(trimetlylamine-N-oxide,TMAO)是一类胆碱代谢物,广泛分布在海产动物体内,在软骨鱼类的肌肉和体液内含量较高。TMAO可以直接从鱼类等膳食来源进入血液循环,也可以通过肠道细菌的活动和肝脏的新陈代谢从膳食前体(如红肉中富含的肉碱和胆碱)进入血液循环。基于瑞典NICE队列(n=549)、加拿大NutriGen Birth队列(n=900)、欧洲EPIC队列(n=37 000)和日本TMCS队列(n=7 012)的人群研究证明,血浆或尿液中的TMAO浓度与鱼类摄入量正相关[56,68,72,80]。
1.4 乳制品生物标志物
血液中奇数链饱和脂肪酸(15∶0、17∶0)和反式棕榈油酸(trans-palmitoleic acid)的浓度与总乳制品、总脂肪乳制品和奶酪制品的摄入量显著相关[81-83]。基于德国、希腊、爱尔兰、荷兰、波兰、西班牙和英国1 180名志愿者的横断面研究显示,十五烷酸(pentadecanoacid)对高脂乳制品具有特异性,且与高脂乳制品摄入量显著正相关,可用于区分高脂乳制品在人群中的消费水平[83]。Mozaffarian等[111]基于CHS队列的研究结果表明,血浆反式棕榈油酸与乳制品摄入中度相关。Pimentel等[87]在开展的乳制品短期干预研究中发现,血清血型H二糖(blood group H disaccharide,BGH)和路易斯A三糖(Lewis A trisaccharide,LeA)浓度与牛奶摄入量相关。Shibutami等[68]基于TMCS队列研究发现,血浆中的半乳糖酸(galactonic acid)可以反映牛奶等乳制品的摄入。Münger等[88]对11名健康受试者开展急性干预实验,发现摄入牛奶后尿液中的乳糖(lactose)、半乳糖(galactonate)和半乳糖酸含量显著升高。3-苯基乳酸(3-phenyllactic acid)、脯氨酸(proline)和泛酸(pantothenate)的循环水平可表征奶酪摄入量[84,88-89,112]。
1.5 坚果和豆类生物标志物
坚果富含多不饱和脂肪酸,其中α-亚麻酸(α-linolenic acid,ALA)是ω-3必需脂肪酸, 主要经肠道吸收进入人体,经血液运送至身体各个部位,是细胞膜结构物质。在碳链延长酶和脱氢酶的作用下,α-亚麻酸可以代谢产生具有生理活性的二十碳五烯酸、二十二碳六烯酸和二十二碳五烯酸[113]。Burns等[93]给自由生活人群(n=20)补充核桃8周(6 个/周)后,干预组红细胞膜α-亚麻酸含量显著高于对照组。Segovia等[94]开展核桃干预实验发现,干预组的血浆α-亚麻酸浓度与核桃摄入量正相关。此外,核桃富含鞣花单宁,经胃和小肠水解成鞣花酸,再由戈登氏菌属放线菌、埃拉氏菌、双歧杆菌等肠道菌群转化为尿石素(urolithins)[114] 。Haddad等[95]开展短期干预研究发现,16名志愿者摄入核桃24 h内,尿液尿石素A(urolithins A)含量显著升高。Mora等[98]分析50名代谢综合征患者摄入混合坚果(核桃、杏仁、榛子)12周后的血浆代谢物含量,发现尿石素A葡萄糖醛酸苷(urolithin A glucuronide)含量与坚果摄入量正相关。
2 利用膳食生物标志物探索饮食与代谢疾病的关系
2.1 全谷物生物标志物与代谢疾病的关系
全谷物摄入可降低罹患几种主要慢性疾病(包括心血管疾病、肥胖症、某些类型的癌症等)的风险[117]。烷基间苯二酚是全谷物食物的膳食生物标志物,具有多种生理活性,在体内的作用与其吸收和代谢密切相关。基于NSHDS队列和DCH队列的巢式病例对照研究表明,血浆中的烷基间苯二酚浓度与2型糖尿病(diabetes mellitus type 2,T2DM)无显著相关性,但血浆中的C17∶0/C21∶0特异性表征全谷物黑麦/小麦的摄入,与2型糖尿病发病风险显著负相关[30]。Kyrϕ等[118]纳入1 372例结直肠癌病例患者开展病例对照研究,并根据病例的人口学特征和其他外部特征匹配了1 372例对照受试者,发现血浆烷基间苯二酚浓度与远端结肠癌的发病率负相关,这与基于北欧HELGA队列开展的病例对照研究(n=1 044)结果一致[119]。烷基间苯二酚代谢物3,5-二羟基苯甲酸、3,5-二羟基苯丙酸也与多种疾病发病风险相关。基于瑞典MDC队列(1 016例病例,1 817例对照)的研究发现,血浆3,5-二羟基苯甲酸、3,5-二羟基苯丙酸与男性患前列腺癌的风险正相关[120]。Zhou等[37]基于同济-鄂州队列开展病例对照研究,结果表明血浆3,5-二羟基苯丙酸浓度与患代谢综合征的风险负相关,也与中国成年人患非酒精性脂肪肝的风险负相关[40]。Sun等[39,121]研究表明,血浆3,5-二羟基苯丙酸浓度与2型糖尿病、缺血性中风、糖代谢紊乱的发生风险负相关。哌啶酸甜菜碱是全麦的特异性生物标志物,Karkkainen等[44]开展小鼠实验和人群干预研究(n=123)发现,哌啶酸甜菜碱可通过改善胰岛素抵抗和胰岛素分泌减少2型糖尿病的发病风险。燕麦蒽酰胺是燕麦特征化合物,具有抗氧化、抗肿瘤活性,可抑制结肠癌,缓解酒精诱导的肝损伤和动脉粥样硬化[122-125],但人群研究结果非常有限[126]。
2.2 果蔬生物标志物与代谢疾病的关系
类胡萝卜素是果蔬生物标志物。Beydoun等[127]基于美国NHANES Ⅲ队列研究发现,5 252名参与者血清中的叶黄素、玉米黄质和β-隐黄质含量与全因痴呆症的发生显著负相关。Feart等[128]基于3C队列研究发现,血浆叶黄素含量与痴呆症、注意力缺失症的发生风险显著负相关。基于Rush MAP队列的研究表明,总类胡萝卜素摄入对阿尔兹海默症具有抵御作用,其中叶黄素和玉米黄质可抑制脑β-淀粉样蛋白沉积和原纤维形成,减缓阿尔兹海默症发病[129]。Sugiura等[130]基于日本Mikkabi队列开展跟踪纵向研究,结果表明血清α-胡萝卜素、β-隐黄素和维生素A原类胡萝卜素与2型糖尿病的发病率负相关。基于NHANES横断面研究发现,α-胡萝卜素、β-胡萝卜素、β-隐黄质、叶黄素和玉米黄质的摄入量与非酒精性脂肪肝患病率显著负相关[131]。Cohen等[132]基于巢式病例对照研究发现,50岁及以下女性(n=3 537)血浆类胡萝卜素含量与乳腺早衰发生风险负相关。血浆类胡萝卜素含量与生物体内的氧化应激水平和结核病发生风险负相关[133-134]。番茄红素作为番茄和其他红色水果的生物标志物,与慢性肾脏病死亡、急性呼吸道感染、癌症和心血管疾病死亡、全因死亡负相关[135-138]。叶黄素-玉米黄质(lutein-zeaxanthin)则与黄斑色素光密度、视网膜敏感性正相关,与痴呆症、燃煤性骨骼氟中毒发病负相关[128,139-141]。
柑橘类水果中富含的橙皮素、柚皮苷等黄酮类化合物与心血管代谢疾病、缺血性中风、痴呆症、高血压、炎症性疾病等存在紧密关联[142-147]。基于IWHS前瞻性队列(n=34 489)研究发现,黄烷酮和富含类黄酮食物的摄入与心脏病、心血管疾病发生风险及死亡风险负相关[146]。Cassidy等[144]基于Health Professionals Follow-Up Study前瞻性队列(n=43 880)研究发现,水果类黄烷酮摄入量与男性非致命性心肌梗死和缺血性中风的发生风险负相关。基于NHS队列(n=80 336)和HPFS队列(n=49 281)的研究表明,总类黄酮摄入与帕金森患病风险负相关[142]。橙皮甙可减轻高血糖诱发的氧化应激和炎症,抑制晚期糖基化终产物积累,减轻视网膜异常,并能有效预防糖尿病引起的神经血管并发症[148-150]。根皮素是表征苹果摄入的特异性生物标志物,动物实验结果表明其具有抗炎、抗氧化功效,可通过调控NF-κB、TLR4、PPARγ等信号通路改善2型糖尿病、肾病、肥胖症和帕金森病的症状[151-154]。
2.3 肉类及鱼类生物标志物与代谢疾病的关系
大量人群研究发现三甲胺-N-氧化物(TMAO)水平与鱼类摄入显著相关,但TMAO却是心血管疾病、肾脏疾病、胰岛素抵抗、动脉粥样硬化、2型糖尿病、认知功能障碍等多种慢性代谢疾病的风险因子[164-171]。除了来源于摄入的鱼和其他海鲜中游离的TMAO以外,人体中产生三甲胺裂解酶的肠道微生物(主要是拟杆菌门和厚壁菌门细菌)会将肉、蛋、奶制品中的胆碱、肉碱、甜菜碱等代谢,产生三甲胺,三甲胺在肝脏经黄素单加氧酶3(FMO3)氧化生成TMAO,也是人体中TMAO的来源。通过鱼类摄入体内的TMAO含量显著高于机体肠道微生物通过红肉、鸡蛋中胆碱和肉碱产生的TMAO含量[172]。尽管机制尚未明确,TMAO转化代谢相关肠道微生物和FMO3活性(如单核苷酸多态性E158K和E308G遗传变异影响FMO3活性)的个体差异与癌症、心血管疾病等多种疾病的发生存在关联[173],或可解释TMAO在疾病发生发展中的重要作用。因此,明确膳食生物标志物的来源及化合物的产生机制对探究食物摄入与疾病的关系非常重要。
2.4 膳食脂肪酸生物标志物与代谢疾病的关系
作为健康饮食模式的一部分,增加坚果摄入可以降低人群患慢性疾病的风险[174]。基于PREvención con DIeta MEDiterránea(PREDIMED,n=7 202)研究发现,表征坚果摄入量的生物标志物α-亚麻酸的摄入量达到每日能量摄入的0.7%及以上时,全因死亡风险降低28%[175]。Jiao等[176]基于NHS队列和HPFS队列的11 264名2型糖尿病患者开展研究,发现α-亚麻酸摄入可降低心血管疾病死亡率和总死亡率,同样的结果在SCHS队列(n=60 298)研究中也被证实[177]。此外,α-亚麻酸循环水平与失能性痴呆症发生风险[178]、年龄增长引起的体重增加负相关[179]。Edel等[180]用亚麻籽干预347名外周动脉疾病患者,发现α-亚麻酸可降低患者的总胆固醇水平和低密度脂蛋白胆固醇水平。α-亚麻酸摄入还可以减少中风造成的脑损伤[181],改善2型糖尿病患者的血清脂联素水平和胰岛素敏感性[182]。
α-亚麻酸的重要衍生代谢物二十碳五烯酸、二十二碳六烯酸和二十二碳五烯酸同样具有改善心血管疾病、促进饱和脂肪酸代谢、降低炎症反应等健康功效。大规模人群队列研究结果表明,二十二碳六烯酸和二十碳五烯酸的摄入与炎症水平、全因死亡率、心血管死亡率和冠心病死亡率均呈显著负相关[177,183-184]。Perez等[185]基于EPIC前瞻性队列(n=142 239)研究发现,二十碳五烯酸摄入量与前列腺癌发生风险正相关。随机对照研究发现,二十二碳六烯酸干预后,121名健康受试者的甘油三酯水平显著降低20%,空腹和餐后低密度脂蛋白胆固醇显著增加18.4%[186]。值得注意的是,尽管二十二碳六烯酸、二十碳五烯酸和二十二碳五烯酸的结构具有相似性,二十二碳六烯酸较二十碳五烯酸能更有效地降低腹部肥胖和低度全身炎症受试者(n=154)的血脂、白细胞介素-6、白细胞介素-18等特定炎症指标水平[187]。二十二碳五烯酸在调节脂类代谢、抑制动脉硬化和降低2型糖尿病风险等方面比二十碳五烯酸、二十二碳六烯酸具有更好的功效[188]。
亚油酸(主要膳食中的ω-6脂肪酸及其主要代谢产物花生四烯酸)的全球饮食建议和心血管保护效应仍存在争议。Marklund等[189]对来自13个国家的30项前瞻性观察研究(n=68 659)进行分析发现,较高循环水平的亚油酸与总心血管疾病发生、心血管死亡和缺血性卒中风险显著负相关,该结果支持亚油酸在心血管疾病预防中的有利作用。
2.5 其他膳食生物标志物与代谢疾病的关系
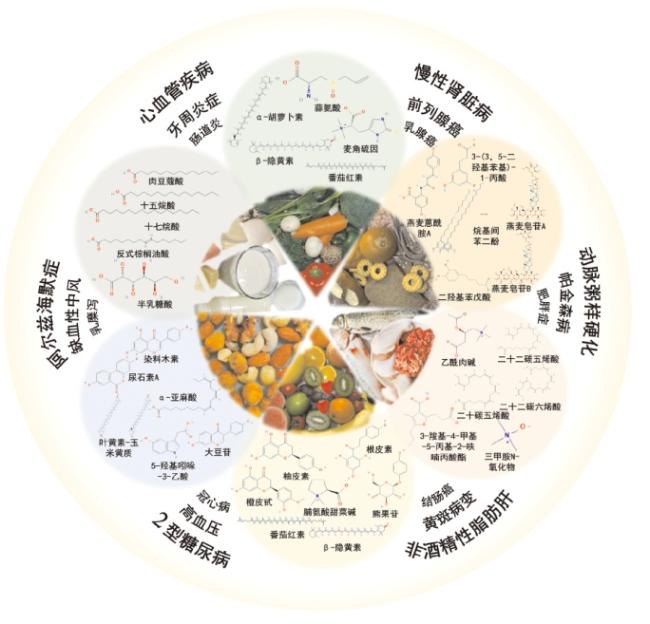
{kind=link}
{kind=link}
3 膳食生物标志物研究及应用挑战
3.1 研究设计
膳食生物标志物从发现到验证再到应用依赖于良好的研究设计。队列研究设计,包括前瞻性研究和横断面研究,受试者处于自由生活状态,筛选的体内特征化合物水平不仅可以捕捉饮食变化,同时具有长期稳定性,对膳食生物标志物的发现和验证有极大帮助[16]。然而,采用FFQ等常见自我报告饮食评估工具收集的饮食数据有测量误差,加之食物成分表的局限性(如不能反映前处理、储存、制备和加工过程对食物化合物成分的影响),导致在人群研究中的饮食摄入与代谢物水平相关性减弱[10-12],增加了假阴性结果的概率。不仅如此,大多数报道的候选饮食生物标志物来源于参与者经常食用并可能更准确回忆的食物,而很少食用的食物通常很难通过回忆或FFQ来捕捉,在这种情况下队列研究可能无法识别此类生物标志物。因此,在不同人群中验证候选膳食生物标志物是非常必要的。现有的大型队列,比如Women’s Health Initiative、the Framingham Health Study、the Nurses’ Health Study、EPIC、中国慢性病前瞻性队列(CKB)、英国生物银行(UKB)等通常被用于生物标志物的发现和验证。
随机对照干预研究不仅可以用于评估饮食对机体生理过程的影响,也可以评估饮食暴露生物标志物的有效性。通过精准控制受试者的饮食摄入,减少营养摄入差异、食物类型差异及食物储存加工带来的差异,干预研究可以提供营养动力学特性的丰富数据,建立食物剂量反应体系,验证候选膳食生物标志物的特异性和敏感性。值得注意的是,队列研究和干预研究对膳食生物标志物的研究结果并不完全一致。比如,Cheung等[72]开展随机干预实验,发现摄入肉类或鱼类后,尿液和血浆中的3-甲基组氨酸、鹅肌肽、肌肽、丙酰肉碱、2-甲基丁酰肉碱和三甲胺-N-氧化物等代谢物浓度显著增加,且不同肉类摄入表现出不同的特异性。而在基于EPIC队列的研究中,摄入鸡肉后,仅3-甲基组氨酸和鹅肌肽在尿液和血浆中浓度显著升高。在干预研究中,人体摄入食物后产生的代谢反应物缺乏稳定性,或许只能作为短期生物标志物,需要更多人群研究验证其有效性。多数干预研究持续时间较短,样本量较小,这也可能会影响最终研究结果。
因此,将观察性研究和干预性研究有效结合,避免单独某种研究的设计缺陷,证明实际摄入量和估计摄入量之间的密切对应(高灵敏度和高特异性),而不是简单地证明两者之间的正相关性,对膳食生物标志物的开发、验证和应用至关重要。
3.2 食物成分复杂且个体差异显著
人们的日常饮食复杂多样,包含成千上万种不同的食物成分,这些成分在体内的代谢途径各不相同,产生的代谢物也存在巨大差异。发现和验证高灵敏度、高特异性、高稳健性的食品特异性生物标志物,需要更多食品化学成分数据信息的支撑。目前已有公开的食品成分数据库,如GNPS(包括超过3 500种食物相关化合物指纹图谱信息,https:∥gnps.ucsd.edu/)、PhytoHub(包括超过600种植物代谢物及其衍生物信息,http:∥phytohub.eu/)、Exposome-Explorer(包括145种饮食生物标志物在不同人群和不同生物样本中的浓度、使用的分析技术以及它们与食物摄入量的相关性,http:∥exposome-explorer.iarc.fr/)、Phenol-Explorer(包括植物酚类化合物及其衍生物信息,http:∥phenol-explorer.eu/)、FooDB(包括大于720种食物原料或轻度加工食物中的大于26 000种化学成分的质谱或核磁共振图谱,https:∥foodb.ca/)。需要注意的是,这些数据库提供的食物化合物信息仍不完整,即使是最全面的食品成分数据库中的平均化合物覆盖率也低于每种食品1 000种化合物,仅占食品全部化合物总量的10%左右,而且数据质量参差不齐,缺乏食品成分的真实化学标准,缺乏真实参考光谱,严重阻碍食品特异性生物标志物的鉴定和验证。
明确食物源化学成分在体内的生物转化方式及产物也是筛选食品特异性生物标志物的重要环节。然而,个体在遗传和生理水平上的差异会影响营养物质的摄入、吸收、代谢和排泄[204];个体的健康状况可能会改变营养物质的代谢状况及其生物标志物的循环水平;饮食习惯、运动习惯及睡眠习惯等生活方式也会影响营养物质的摄入和代谢[10];不同个体的肠道菌群组成各不相同,而肠道菌群在营养素的消化吸收过程中至关重要,可直接导致代谢物的差异。以上因素都可能导致同样的食物或营养素摄入在不同的个体中产生不同的生物标志物[205]。尽管现有研究在识别食物特异性、肝脏特异性以及肠道菌群代谢物方面取得了稳步进展,但生物样本中高达数万种化合物中仅有不到5%的化合物有可参考的核磁共振或者质谱图谱。
需要非常注意的是,食物生物标志物应具有高灵敏性和高特异性,才能捕捉特定饮食暴露信息。食物生物标志物在人群中的含量范围因生理状态而异,如同一种化合物在男性和女性、老人和孩子体内的含量大不相同。然而,大多数目前发现的生物标志物在人群中的含量范围尚不清楚。明确生物标志物在不同生理状态人群体内的含量参考范围,才能利用饮食生物标志物捕捉特异性饮食暴露程度及其带给机体的生理影响,为个性化营养干预夯实基础。
3.3 代谢组学数据处理难度升级
膳食生物标志物的发现离不开高通量检测平台。液相质谱联用技术因其高灵敏度、高通量以及高覆盖范围等特点被广泛应用于代谢组学研究,是筛选病理相关潜在生物标志物和分子机制研究的有力工具。然而,由于生物样品的异质性和仪器设备的不稳定,质谱代谢组学数据在采集过程中往往存在多种干扰因素,如信号漂移、数据元素缺失等[208-209]。不同实验室和平台的操作过程存在系统或随机误差,获得的数据难以进行比较[210]。鉴定新的生物标志物需要将代谢组学分析所得的大量数据进行数据库搜索和比对,解析和标识每个检测信号,工作量巨大,且代谢物数据库尚不完整,增加了谱图解析和化合物精准标识的难度[211]。例如,在利用非靶向代谢组学探索发现生物标志物的过程中,代谢物注释能力非常有限,只有不到2%的质谱峰能被成功鉴定为特定代谢物,而再将代谢物对应为相应的生物学信息也面临挑战。现有处理代谢组学数据的免费开源工具,如MZmine 3、MS-DIAL、MS-FINDER[212-213],以及基于R语言的XCMS、XCMS-MRM、METLIN-MRM、Metabolite Automatic Identification Toolkit(MAIT)已得到广泛应用[214-217],协助科研工作者完成代谢组学数据的前处理以及海量代谢物的鉴定注释工作。最新开发的用于代谢组学数据分析的在线服务器MMEASE(https:∥idrblab.org/mmease/)整合了现有的代谢物数据库,一共提供了超过33万个代谢物和外源性注释信息,包括107 071个内源性代谢物、124 451个外源性代谢物和169 352个肽类,涵盖多种食物成分和食品添加剂、植物代谢物和农用化学品、小分子药物和药物代谢物、毒素、环境污染物和微生物代谢物、天然药物次生代谢产物等,为基于代谢组学探究稳定可靠的膳食生物标志物或营养靶点提供了有力的技术支撑。
常用的非靶向代谢组学分析可获得大量化合物信息,有高度的复杂性和多样性,每个样本可能包含数千个代谢物,而这些代谢物在不同个体之间、同一个体的不同实验条件下都可能存在显著差异[218-219]。如何从成千上万的代谢物中筛选高灵敏性、高稳健性、高特异性的膳食生物标志物是一项极具挑战性的工作。目前,膳食生物标志物筛选主要采用的统计方法是单变量分析,主要包括随机对照研究中通常采用的组间比较(ANOVA、Student’t test、Chi-square等)和队列研究中经常使用的多元线性回归(包括逻辑回归)。多因素参数及非参数检验以及多元统计分析主要包括多元线性回归分析、岭回归、套索回归、主成分分析、偏最小二乘回归分析、机器学习等。表2汇总了常见的用于生物标志物筛选的统计分析方法及其优缺点。科学合理地选用多种统计方法组合可以更好地预测饮食、健康和疾病的代谢网络,为实现基于代谢组学的精准营养提供可能。
表2 筛选膳食生物标志物的常见统计方法Tab.2 Statistical methods used for screening dietary biomarkers |
| 统计方法 | 优缺点 |
|---|---|
| T test、Mann Whitney、Chi-square、 ANOVA、Kruskal Wallis | √算法简单,结果容易解读。 ×只能分析一个因素对结果的影响,而实际问题往往是多个因素共同作用的结果。 ×不考虑代谢物之间的共线性及相关性。 |
| 多元线性回归(multiple linear regression) | √算法简单,结果容易解读。 ×样本量影响变量显著性。 ×不考虑多因素的共线性及相关性。 ×实际应用过程中模型混杂因素的筛选很重要,会直接影响生物标志物与饮食暴露之间的相关性。 |
| 岭回归(ridge regression)和套索回归(lasso regression) | √解决多重共线性数据的有偏估计回归方法。 √利用AIC准则和BIC准则精炼简化统计模型的变量集合,对多维复杂数据有效降维。 √防止过拟合,又可以实现特征变量选择。 ×算法较难,需要扎实的统计学基础。 ×模型构建和变量选择需要交互验证。 |
| 主成分分析(principle component analysis)、LDA(latent dirichlet allocation)、主坐标分析(principal co-ordinates analysis)、多维尺度分析(multidimensional scaling) | √无监督学习算法,无需先验知识。 √大规模人群数据分析中可用于检测异常样本。 √基于对象数据的方向和重要度实现有效降维。 √可视化程度高。 ×无显著性检验。 ×不能基于变量对模型构建的重要性进行特征代谢物筛选和排序。 |
| 偏最小二乘回归分析(partial least square regression analysis)、偏最小二乘判别分析(partial least square discriminant analysis)、正交偏最小二乘判别分析(orthogonal partial least square discriminant analysis)、稀疏偏最小二乘分析(sparse partial least square analysis) | √有监督学习算法,通过投影分别将预测变量和观测变量投影到新空间构建预测模型。 √对大规模复杂变量集合实施降维。 √可视化程度高。 √稀疏偏最小二乘分析可在PLS基础上实现特征变量选择。 ×高维变量小样本数据情况下模型易过拟合,须采用交互验证和置换检验手段优化模型。 ×需要评估模型预测能力。 ×注意生物标志物选择假阳性问题。 |
| 随机森林(random forest) | √基于if-then-else规则的有监督学习算法,可用于分类问题,也可解决回归问题。 √可以处理缺失值,且少量缺失值对模型效果影响不大。 √可以处理复杂数据,且对异常值稳健性强。 √可以分析代谢物之间以及代谢物与饮食暴露之间的复杂关系。 √可以判断特征变量的重要程度,进而有助于标志物筛选。 √模型不容易过拟合。 ×主要参数(决策树和节点)的选择会影响模型结果和预测效果。 ×当样本量大、决策树个数多时,训练速度较慢。 |
| 人工神经网络(artificial neural networks) | √由大量处理单元互联组成的非线性、自适应信息处理系统,适用于处理含有较多与研究问题无关噪声的复杂数据。 ד黑匣子”性质,对统计学基础要求较高。 ×模型训练速度较慢。 |
4 结论
膳食生物标志物的开发和验证有助于准确评估饮食摄入,反映特定饮食模式,根据代谢物的改变情况及其综合作用效果还可以辅助判断病情阶段、推测发病机制、进行靶向治疗,为精准营养和个性化治疗营养代谢疾病提供了理论依据。现有研究中,大量潜在生物标志物还未经过系统性评估,存在重现性差、稳定性低、时效短等问题,只有少量膳食生物标志物通过了流行病学研究的既定验证标准。膳食生物标志物的确定需要明确其生物学合理性、剂量响应、时间响应、可靠性、稳定性以及特异性。随着组学技术及数据分析方法的不断发展和完善,与饮食和疾病相关的代谢产物得到更准确、全面的表征,将大力推动饮食与疾病相互作用研究,也为根据机体代谢特征制定个性化膳食预防策略和更精确的营养建议奠定了科学基础。