

美国控制论专家Zadeh[1]提出模糊集理论是对生活中模糊现象的刻画过程。Pawlak[2]提出的粗糙集模型是通过定义两个近似算子对经典集合进行刻画的过程,因此如何将两种处理不确定性问题的理论结合起来也成为近年来研究的另一个热题,Dubois和Prade[3]在1990年提出了粗糙模糊集和粗糙模糊集模型,为两种理论的结合打开了一扇崭新的大门。
此外,粒计算也是近年来发展起来的一门新学科,粒计算的研究在国际学术上受到了众多研究者的关注,越来越多的研究成果登上了学术舞台,Qian等[4]在2010年提出来多粒度粗糙集模型,把粒计算中的多粒度引入粗糙集中,建立了乐观和悲观的多粒度粗糙集模型。在实际生活应用中还存在着某些粒度一定属于刻画的概念和某些粒度可能属于被刻画的概念这两种情况,因此我们将这两种情况引入粗糙集和模糊集理论中,建立多粒度粗糙模糊集模型[5]。
在实际生活中,数据通常是动态变化的。比如在智能推荐系统中,用户的偏好和行为会随着时间不断变化。用户可能会购买新的产品、浏览不同的网页或改变他们的购物习惯。这些变化会导致用户数据不断更新,从而影响推荐模型的准确性。传统的静态方法是在整个更新的数据上重新训练整个模型,这使得它在即时推荐等方面过于耗时。其中,增量学习是一种机器学习方法,它允许模型在接收到新数据时不断更新和改进自身,而无需从头开始重新训练。这种方法特别适用于处理随时间逐渐累积的数据,被广泛应用于动态环境下的粗糙集模型。在粗糙集的应用中,近似集计算是重要且必要的。近年来,运用增量学习方法来计算和更新多粒度粗糙集及其拓展模型的上下近似集,引起了众多研究者的广泛关注。这些研究通常根据数据集中的改变情景分为以下几类,即对象集的变化[6-7]、属性增减[8-10]、属性值改变[11]、决策属性改变[12]。
其中,矩阵是一种高效的,简单的便于知识表示和推理的工具,被广泛应用于粗糙集的近似集更新中,Zhang等[13]提出了一种基于并行矩阵的不完备信息系统逼近计算方法。Liu[14]探索了一种基于矩阵的粗糙集上下逼近运算方法。Chen等[15]提出一种决策理论粗糙集中对象和属性同时变化时的知识更新方法。Xu等[16]提出了一种基于矩阵的多粒度粗糙集快速粒度约简算法。
本文通过分析既有研究成果,发现这些矩阵方法不能直接用于多粒度粗糙模糊集模型的近似计算。因此,为了解决这一问题,提出了一种新的矩阵运算来表示多粒度粗糙模糊集的上下近似。并进一步开发了基于矩阵的增量机制。
1 预备知识
本节介绍多粒度粗糙模糊集和模糊决策信息系统的一些知识。
定义1[17] 一个模糊决策信息系统S=(U,A∪D,V,f)可被形式化定义为一个四元组,其中U={xi|i=1,2,…,n}是非空有限对象的集合,称为论域;A是条件属性的非空有限集合,D是模糊决策属性的非空有限集合,A∩D=∅;VA是条件属性的值域,VD是决策属性的值域,VD=[0,1],f是一个从U×(A∩D)到V的函数,使得f:U×A→VA,f:U×D→VD。
定义2[18] 设S=(U,A∪D,V,f)是一个模糊决策信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度。 是关于属性ak的等价关系, 的上下近似是关于等价关系 的一对模糊集,它们的隶属函数定义如下:
(x)=inf{ (y)|y∈[x },
(x)=sup{ (y)|y∈[x }。
式中,[x ={y∈U|x y}代表x的 等价类。
定义3[4] 设S=(U,A∪D,V,f)是一个信息系统,a1,a2,…,am∈A,∀X⊆U,X的乐观多粒度粗糙集下、上近似分别定义为
(X)={x∈U|[x ⊆X∨[x ⊆X∨…∨[x ⊆X},
(X)=~ (~X)。
定义4[4] 设信息系统S=(U,A∪D,V,f),∀a1,a2,…,am∈A,∀k∈{1,2,…,m},∀X⊆U,X的悲观多粒度粗糙集的下、上近似分别定义为
(X)={x∈U|[x ⊆X∧[x ⊆X∧…∧[x ⊆X},
(X)=~ (~X)。
定义5[5] 设模糊决策信息系统S=(U,A∪D,V,f),∀a1,a2,…,am∈A, , ,…, 是m个等价关系。 是D的一个模糊子集, (x)表示x关于 的隶属度,∀k∈{1,2,…,m}, 的乐观多粒度下、上近似集为 和 ,∀x∈U,x属于下、上近似集的隶属度定义如下:
(x)= {∧ (y)|y∈[x },
(x)= {∨ (y)|y∈[x }。
定义6[5] 设模糊决策信息系统S=(U,A∪D,V,f),∀a1,a2,…,am∈A, , ,…, 是m个等价关系。 是D的一个模糊子集, (x)表示x关于 的隶属度, 的悲观多粒度下、上近似集为 和 ,∀x∈U,x属于下、上近似集的隶属度定义如下:
(x)= {∧ (y)|y∈[x },
(x)= {∨ (y)|y∈[x }。
 {0,1,2},
{0,1,2},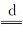 {0,1},∀a1,a2,…,a4∈A,
{0,1},∀a1,a2,…,a4∈A,U/ ={{x1,x3,x4},{x2,x5,x7,x9,x10},{x6,x8}},
U/ ={{x1,x3,x4,x6,x8},{x2,x5,x7,x9,x10}},
U/ ={{x1,x2,x3,x4,x5,x7},{x6,x8,x9,x10}},
U/ ={{x1,x2,x3,x4,x5,x7},{x6,x8,x9,x10}};
表1 模糊决策信息系统Tab.1 Fuzzy decision information system |
| U | a1 | a2 | a3 | a4 | 模糊决策属性 | |
|---|---|---|---|---|---|---|
| 流感 | 无流感 | |||||
| x1 | 2 | 1 | 0 | 1 | 0.8 | 0.3 |
| x2 | 1 | 0 | 0 | 1 | 0.3 | 0.5 |
| x3 | 2 | 1 | 0 | 1 | 1 | 0.1 |
| x4 | 2 | 1 | 0 | 1 | 0.7 | 0.2 |
| x5 | 1 | 0 | 0 | 1 | 0.1 | 0.8 |
| x6 | 0 | 1 | 1 | 0 | 0.3 | 0.7 |
| x7 | 1 | 0 | 0 | 1 | 0.2 | 0.1 |
| x8 | 0 | 1 | 1 | 0 | 0 | 0.9 |
| x9 | 1 | 0 | 1 | 0 | 0.4 | 0.6 |
| x10 | 1 | 0 | 1 | 0 | 0.2 | 0.7 |
(x1)= (x3)= (x4)=0.8∧1∧0.7=0.7,
(x2)= (x5)= (x7)= (x9)= (x10)=0.3∧0.1∧0.2∧0.4∧0.2=0.1,
(x1)= (x3)= (x4)= (x6)= (x8)=0.8∧1∧0.7∧0.3∧0=0,
(x2)= (x5)= (x7)= (x9)= (x10)=0.3∧0.1∧0.2∧0.4∧0.2=0.1,
(x1)= (x2)= (x3)= (x4)= (x5)= (x7)=0.8∧0.3∧1∧0.7∧0.1∧0.2=0.1,
(x6)= (x8)= (x9)= (x10)=0.3∧0∧0.4∧0.2=0,
(x1)= (x2)= (x3)= (x4)= (x5)= (x7)=0.8∧0.3∧1∧0.7∧0.1∧0.2=0.1,
(x6)= (x8)= (x9)= (x10)=0.3∧0∧0.4∧0.2=0;
(x1)=0.7∨0∨0.1∨0.1=0.7,
(x2)=0.1∨0.1∨0.1∨0.1=0.1,
(x3)=0.7∨0∨0.1∨0.1=0.7,
(x4)=0.7∨0∨0.1∨0.1=0.7,
(x5)=0.1∨0.1∨0.1∨0.1=0.1,
(x6)=0∨0∨0∨0=0,
(x7)=0.1∨0.1∨0.1∨0.1=0.1,
(x8)=0∨0∨0∨0=0,
(x9)=0.1∨0.1∨0∨0=0.1,
(x10)=0.1∨0.1∨0∨0=0.1;
(x)={ + + + +
+ + + + + }。
同理可以得到
(x)={ + + + + + + + + + },
(x)={ + + + + + + + + + },
(x)={ + + + + + + + + + }。
2 多粒度粗糙模糊集近似集的矩阵表示
定义7[20] 信息系统S=(U,A∪D,V,f)是一个模糊决策信息系统,∀k∈{1,2,…,m},∀ak∈A,且U={x1,x2,…,xn}, 表示属性ak在U上的等价关系。 =( )n×n表示属性ak的等价关系矩阵,则
定义8[19] S=(U,A∪D,V,f)是一个模糊决策信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度。∀a1,a2,…,am∈A, , ,…, 是m个等价关系。而且 =( )n×n,∀k∈{1,2,…,m}, ⊗max 是一个列向量,该向量的第i(i=1,2,…,n)个元素定义如下:
(⊗max )(i)=max{ · (x1), · (x2),…, · (xn)}。
定理1 S=(U,A∪D,V,f)是一个模糊决策信息系统, , ,…, 是等价关系矩阵, 是D的一个模糊子集, (x)表示x关于 的隶属度, ⊗max 是一个列向量。∀a1,a2,…,am∈A, , ,…, 是m个等价关系,∀k={1,2,…,m}, 的乐观和悲观多粒度上下近似计算如下:
= (L- ⊗max ),
= (⊗max ),
= (L- ⊗max ),
= (⊗max )。
式中:L是所有元素都是1的列向量; 是 的补集。
证明 根据定义8,∀xi∈U,任意的等价关系 ,有式(12)成立,如果 =1成立,则有xj∈[xi ,即 · (xj)= (xj),否则 · (xj)=0。根据定义2和定义5有 (xi)={ ( ⊗max )}(i)成立,根据定义2和定义6有 (xi)={ ( ⊗max )}(i)成立,根据 =~ 和定义5,有等式 (xi)={ (L- ⊗max )}(i)成立,同理有 (xi)={ (L- ⊗max )}(i)成立。
例2 根据表1给出的模糊信息系统, 取流感,U表示患者,设 =(L- ⊗max ), = ⊗max , =(0.8 0.3 1 0.7 0.1 0.3 0.2 0 0.4 0.2)T,求 的乐观和悲观多粒度上下近似。 = ⊗max = ⊗max = 。
同理可得
=(1 0.4 1 1 0.4 1 0.4 1 0.4 0.4)T,
=(1 1 1 1 1 0.4 1 0.4 0.4 0.4)T,
=(1 1 1 1 1 0.4 1 0.4 0.4 0.4)T,
=(0.7 0.1 0.7 0.7 0.1 0 0.1 0 0.1 0.1)T,
=(0 0.1 0 0 0.1 0 0.1 0 0.1 0.1)T,
=(0.1 0.1 0.1 0.1 0.1 0 0.1 0 0 0)T,
=(0.1 0.1 0.1 0.1 0.1 0 0.1 0 0 0)T。
根据定理1,有
=(0.7 0.1 0.7 0.7 0.1 0 0.1 0 0.1 0.1)T,
=(1 0.4 1 1 0.4 0.3 0.4 0.3 0.4 0.4)T,
=(0 0.1 0 0 0.1 0 0.1 0 0 0)T,
=(0 0.1 0 0 0.1 0 0.1 0 0 0)T。
3 增加属性时基于矩阵的上下近似更新
在多粒度粗糙模糊集中,研究由属性增加而引起的粒结构的变化具有重要意义,在增加属性时,提出了基于矩阵动态更新 的乐观和悲观多粒度上下近似的定理,并进行了证明。
定理2 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的乐观多粒度下近似的矩阵表示,增加属性am+1后, =[ , ,…, ]T为更新之后的矩阵,设增加的 =L- ⊗max =[ , ,…, ]T,∀i∈{1,2,…,n},则如下结果成立:
=
证明 设 =L- ⊗max =[ , ,…, ]T,∀k∈{1,2,…,m}。根据定理1,∀i∈{1,2,…,n},有 = 成立。当 ≥ 时, = = ∨ = 。同理可以看出,当 < 时, = = ∨ = ,则定理可证。
定理3 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的乐观多粒度上近似的矩阵表示,增加属性am+1后, =[ , ,…, ]T为更新之后的矩阵表示,计算得到 = ⊗max =[ , ,…, ]T,∀i={1,2,…,n),则如下结果成立:
=
证明 假设 = ⊗max =[ , ,…, ]T成立,∀k∈{1,2,…,n},根据定理1`,∀i∈{1,2,…,n},有 = 成立。当 ≤ 时, = = ∧ = ,同理当 ≥ , = = ∧ = ,则定理可证。
定理4 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的悲观多粒度下近似的矩阵表示,增加属性am+1后,更新之后得到矩阵 =[ , ,…, ]T,设增加的 =L- ⊗max =[ , ,…, ]T,∀i∈{1,2,…,n},则如下结果成立:
=
证明 设 =L- ⊗max =[ , ,…, ]T,∀k∈(1,2,…,m),根据定理1,∀i∈{1,2,…,n},有 = 成立。当 ≤ 时, = = ∧ = ,当 > 时, = = ∧ = ,则定理可证。
定理5 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的悲观多粒度上近似的矩阵表示,增加属性am+1后, =[ , ,…, ]T为更新之后的矩阵,设增加的 = ⊗max =[ , ,…, ]T,∀i∈{1,2,…,n},则如下结果成立:
=
证明 假设 = ⊗max =[ , ,…, ]T成立,∀k∈{1,2,…,m},根据定理1,∀i{1,2,…,n},有 = 成立。当 ≥ 时, = = ∨ = ,同理当 ≥ 时, = = ∨ = ,则定理可证。
4 减少属性时基于矩阵的上下近似更新
本节提出了在减少属性时动态更新上下近似的基于矩阵的一些定理,并加以证明。
定理6 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的乐观多粒度下近似的矩阵表示,减少属性am后, =[ , ,…, ]T为更新之后的矩阵,设减少的 =L- =[ , ,…, ]T,∀i={1,2,…,n},∀j∈{1,2,…,m-1},则如下结果成立:
=
式中, =1-( ⊗max )(i)。
证明 设 =L- ⊗max =[ , ,…, ]T,∀k∈(1,2,…,m},根据定理1,∀i∈{1,2,…,n},有 = 成立。当 < 时, = = ,同理当 ≥ ,有 = =max ,j∈{1,2,…,m-1}成立,则定理可证。
定理7 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈(1,2,……,m), , ,…, 是m个等价关系。 =[ , ,…, ]T为 的乐观多粒度上近似的矩阵表示,减少属性am后 =[ , ,…, ]T为更新之后的矩阵,设减少的 = ⊗max =[ , ,…, ]T,∀i∈{1,2,…,n},∀j∈{1,2,…,m-1},则如下结果成立:
=
式中, =( ⊗max )(i)。
证明 假设 = ⊗max =[ , ,…, ]T成立,∀k∈{1,2,…,m},根据定理1,∀i∈{1,2,…,n},有 = 成立。当 > 时, = = ,同理可以看出当 ≤ 时,有 = =min 成立,则定理可证。
定理8 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的悲观多粒度下近似的矩阵表示,减少属性am后, =[ , ,…, ]T为更新之后的矩阵,设减少的 =L- ⊗max =[ , ,…, ]T,∀i∈{1,2,…,n},∀j∈{1,2,…,m-1},则如下结果成立:
=
式中, =1-( ⊗max )(i)。
证明 设 =L- ⊗max =[ , ,…, ]T,∀k∈{1,2,…,m},根据定理1,∀i∈{1,2,…,n},有 = 成立。当 > 时, = = ,同理可以看出当 ≤ 时, = =min ,则定理可证。
定理9 S=(U,A∪D,V,f)是一个信息系统, 是D的一个模糊子集, (x)表示x关于 的隶属度,∀a1,a2,…,am∈A,∀k∈{1,2,…,m}, , ,…, 是m个等价关系。设 =[ , ,…, ]T为 的悲以多粒度上近似的矩阵表示,减少属性am后, =[ , ,…, ]T为更新之后的矩阵,设增加的 = ⊗max =[ , ,…, ]T,∀i∈{1,2,…,n},∀j∈{1,2,…,m-1},则如下结果成立:
=
式中, =( ⊗max )(i)。
证明 假设 = ⊗max =[ , ,…, ]T成立,∀k∈{1,2,…,m},根据定理1,∀i∈{1,2,…,n},有 = 成立。当 < 时, = = ,同理可以看出当 ≥ 时, = =max ,则定理可证。
5 时间复杂度的计算
本节在上述理论分析的基础上,提出了一种基于矩阵的动态算法,用于增加或减少属性时基于矩阵计算 的乐观和悲观多粒度上下近似,并比较了静态算法和动态算法的时间复杂度。
算法1是一种基于矩阵的静态算法,用于计算 的乐观和悲观多粒度上下近似。步骤1~11是根据定义7计算等价关系矩阵,其时间复杂度为O(m|U|2)。步骤12~15是根据定义8计算,其时间复杂度为O(m|U|2)。步骤16是根据定理1计算 的乐观悲观多粒度上下近似,其时间复杂度为O(m|U|)。因此,算法1的总时间复杂度为O(m|U|2)。
| 算法1 计算上下近似的静态算法 输入:模糊信息系统S=(U,A∪D,V,f);属性值a1,a2,…,am;隶属度 (x)。 输出: , , , 。 1:for k=1 to m do 2: for i=1 to n do 3: for j=1 to n do 4: if ak(xi)=ak(xj) then 5: =1; 6: = ; 7: =0; 8: end 9: end 10: end 11:end 12:for k=1 to m do 13: 计算 ⊗max ; 14: 计算L- ⊗max ; 15:end 16:计算 , , , 。 17:end |
算法2是一种基于矩阵的动态算法,用于在增加属性时计算 的乐观和悲观多粒度上下近似。步骤1是根据定义7计算属性am+1的等价关系矩阵,又根据定义8计算 和 ,其时间复杂度为O(|U|2)。步骤2~8是根据定理2更新表示 的乐观多粒度上近似,其时间复杂度为O(|U|)。步骤9~15是根据定理2更新表示 的乐观多粒度下近似,其时间复杂度为O(|U|)。步骤16~22是根据定理2更新表示 的悲观多粒度下近似,其时间复杂度为O(|U|)。步骤23~29是根据定理2更新表示 的悲观多粒度上近似,其时间复杂度为O(|U|)。总时间复杂度为O(|U|2)。可以看出,优于基于矩阵的静态算法(算法1)。
| 算法2 增加属性时更新上下近似的动态算法 输入:模糊信息系统S=(U,A∪D,V,f);属性值a1,a2,…,am;隶属度 (x);增加的属性am+1;更新之前的上下近似 , , , 。 输出: , , , 。 1:计算 and and ; 2:for i=1 to n do 3: if ≥ then 4: = 5: else 6: = 7: end 8:end 9:for i=1 to n do 10: if ≤ then 11: = 12: else 13: = 14: end 15:end 16:for i=1 to n do 17: if ≤ then 18: = 19: else 20: = 21: end 22:end 23:for i=1 to n do 24: if ≥ then 25: = 26: else 27: = 28: end 29:end |
算法3是一种基于矩阵的动态算法,用于在减少属性时计算 的乐观和悲观多粒度上下近似。步骤1是根据定义7计算属性am的等价关系矩阵,又根据定义8计算 和 ,其时间复杂度为O(|U|2)。步骤2~8是根据定理2更新表示 的乐观多粒度上近似,当if else语句中的条件判断导致每次都执行else分支时,算法的时间复杂度达到最坏情况,在最坏情况下,时间复杂度为O((m-1)|U|2)。同理,步骤9~15是根据定理2更新表示的乐观多粒度下近似,在最坏情况下,其时间复杂度为O((m-1)|U|2)。步骤16~22是根据定理2更新表示 的悲观多粒度下近似,在最坏情况下,其时间复杂度为O((m-1)|U|2)。步骤23~29是根据定理2更新表示 的悲观多粒度上近似,在最坏情况下,则其时间复杂度为O((m-1)|U|2)。所以,总的时间复杂度是O((m-1)|U|2,但是实际运行时间会与if else语句中的条件判断有关。
| 算法3 减少属性时更新上下近似的动态算法 输入:模糊信息系统S=(U,A∪D,V,f);属性值a1,a2,…,am;隶属度 (x);减少的属性am;更新之前的上下近似 , , , 。 输出: , , , 。 1:计算 and and ; 2:for i=1 to n do 3: if < then 4: = 5: else 6: =max 7: end 8:end 9:for i=1 to n do 10: if > then 11: = 12: else 13: =min 14: end 15:end 16:for i=1 to n do 17: if > then 18: = 19: else 20: =min 21: end 22:end 23:for i=1 to n do 24: if < then 25: = 26: else 27: =max 28: end 29:end |
6 实验时间的对比
本节进行了几个实验来验证在增加或减少属性时更新近似算法的有效性,对动态更新算法和静态算法的运行时间进行了比较,同时和从集合角度的动态更新算法进行了比较,表2中实验评估的数据集源自UCI机器学习数据集存储库。实验中我们将每个数据集分成10个相等的部分,第1部分作为第1个数据集,第1部分和第2部分的组合作为第2个数据集,以此类推,这10部分的组合作为第10个数据集,所有实验算法在Windows 11,Intel(R) Core(TM) i7-10700K CPU@3.80 GHz,3.70 GHz 32 GB内存的个人电脑上进行测试,算法在MATLAB 2021中编码。
表2 实验使用的UCI数据集Tab.2 UCI data set for experimental use |
| 数据集 | 个数 | 属性数 | 类别数 |
|---|---|---|---|
| Balance Scale | 625 | 4 | 3 |
| Breast Cancer Wisconsin | 683 | 9 | 2 |
| Contraceptive Method Choice | 1 473 | 9 | 2 |
| Phishing Websites | 2 456 | 30 | 3 |
6.1 增加属性时实验时间的对比
当增加属性时,我们比较了表3所示数据集上基于矩阵的静态算法和动态更新算法的运行时间。我们将表3中的初始属性作为数据集中的原始条件,各个数据集从表3中添加相应的属性。实验结果如图1所示,横坐标代表论域的大小,纵坐标代表计算时间,图中的●折线显示了随着数据集规模增加,增加属性的矩阵动态算法运行时间随论域增加的变化情况;■折线显示了随着数据集规模增加,静态算法运行时间随论域增加的变化情况;▲折线显示了随着数据集规模增加,从集合角度的非矩阵更新算法运行时间随论域增加的变化情况。从图1中的实验结果可以看出,静态算法和增量算法的运行时间随着数据集的增加而增加;基于矩阵的增量算法的计算时间始终低于静态算法和非矩阵更新算法,当数据集的规模增加时,这种差距会变得更大。
表3 增加属性时使用的UCI数据集Tab.3 The UCI data set used when adding attributes |
| 数据集 | 初始的属性 | 增加的属性 |
|---|---|---|
| Balance Scale | {a1,a2,a3} | {a4} |
| Breast Cancer Wisconsin | {a1,a2,…,a7} | {a8,a9} |
| Contraceptive Method Choice | {a1,a2,…,a7} | {a8,a9} |
| Phishing Websites | {a1,a2,…,a27} | {a28,a29,a30} |
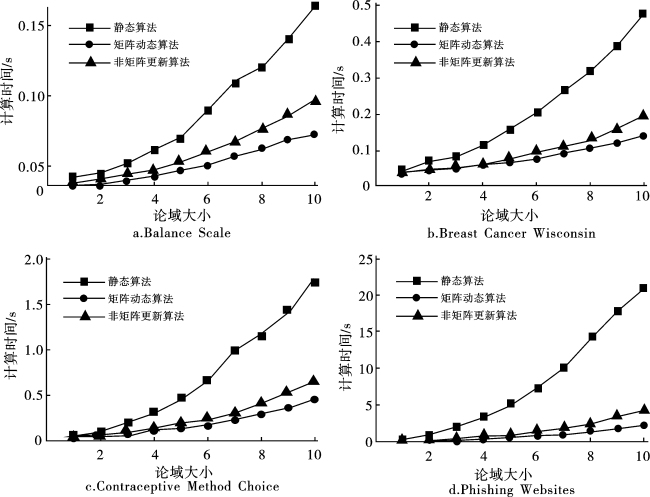
6.2 减少属性时实验时间的对比
表4 减少属性时使用的UCI数据集Tab.4 The UCI data set used when reducing attributes |
| 数据集 | 初始的属性 | 减少的属性 |
|---|---|---|
| Balance Scale | {a1,a2,…,a4} | {a4} |
| Breast Cancer Wisconsin | {a1,a2,…,a9} | {a8,a9} |
| Contraceptive Method Choice | {a1,a2,…,a9} | {a8,a9} |
| Phishing Websites | {a1,a2,…,a30} | {a28,a29,a30} |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
7 结语
本文提出了一种在模糊信息系统中增加或减少属性时基于矩阵更新多粒度粗糙模糊集近似集的动态算法,首先用矩阵的形式给出了多粒度粗糙模糊集上下近似集的表示方法,并给出了相应的动态算法,比较静态算法和动态算法的时间复杂度,并在UCI数据集中进行了实验,表明动态算法计算效率优于静态算法。
未来的工作将探究在多粒度模糊的前提下,当对象增加或者减少时近似集的动态更新方法,当本文中的等价关系与属性改变时基于矩阵给出相应的近似集的动态更新方法,并实际应用于具体的数据集中。