

序列推荐在推荐系统中扮演着重要的角色,它将用户-物品的交互行为看作是动态变化的序列,通过对用户的行为序列(比如购买商品的序列)来进行建模,并考虑序列间的相关性来捕捉用户最近的偏好,从而能够对用户的下一个行为进行预测[1]。传统的序列推荐模型如早期的序列模式挖掘[2]和马尔可夫链模型[3-4]等,虽然较为简单,但是它们只能捕获序列的短期依赖关系而忽略长期依赖;随着人工智能的不断发展,深度学习模型已经被应用于各个领域,而且占据了序列化推荐的主导地位。深度神经网络模型(如attention等)能捕获不同实体(如用户、物品、用户-物品的交互)间的综合关系,在序列推荐中能捕获序列的长期依赖。然而,在序列推荐中,表征空间里的流行度偏差仍然存在,导致推荐性能下降。
SASRec(self-attention sequential recommendation)是第一个基于注意力机制(self-attention)的序列推荐,它结合了马尔可夫链(Markov chain)和循环神经网络(recurrent neural network,RNN)的优势[5]。SASRec模型可以像循环神经网络一样捕捉较长的语义信息,与循环神经网络不同的是,SASRec模型里加入了注意力机制,可以像马尔可夫链一样基于较少的行为做出预测,从用户行为历史中找到比较相关的物品,并利用它们来预测下一个物品。对比学习既可以通过学习更均匀的用户-物品表示来减轻流行度偏差,也可以从大量未标记的原始数据中提取特征并以自监督的方式对表示学习进行正则化,是推荐系统中数据稀疏性问题的解决办法[6]。目前,很多研究都基于对比学习来提高模型性能,由于现有的序列推荐算法对收集到的序列数据建模时常受到噪声的影响,从而降低推荐模型的有效性,针对该问题,张少东等[7]使用傅里叶变换对收集到的数据进行噪声过滤,最大化基于自注意力机制的编码器对特征的捕获能力,提高了模型的性能;基于图推荐中的对比学习使用结构扰动来扩充用户项目二部图以达到图增强的效果,然后最大化在不同视图下表示的一致性[8],结果证明对比学习在推荐系统中确实可以提高模型的泛化能力。因此,本文在SASRec模型中引入对比学习,使空间里的特征分布呈现均匀性,以减轻表征空间里的流行度偏差带来的影响。
1 序列推荐
1.1 传统的序列推荐
最早期的序列推荐没有复杂的数学模型和神经网络,主要是数据挖掘模式,即通过用户行为序列挖掘出频繁的模式,但是这样的方式会产生大量的数据冗余。2005年Shani等[9]将基于马尔可夫链的方法应用于序列推荐,该方法采用马尔可夫链对行为序列中用户-物品的交互进行建模,通过计算转移矩阵来预测下一次交互。2010年Rendle等[10]将协同过滤思想应用于推荐系统,通过个性化的马尔可夫链和矩阵分解进行推荐。RoFormer模型[11]提出了一个能够将相对位置信息依赖集成到self-attention中并提升Transformer构架性能的位置编码方法。在基于马尔可夫链的序列推荐中,t时刻的用户行为只与t-1时刻的用户行为有关系,与t-2时刻及以前的用户行为都无关,即马尔可夫链方法在序列推荐中不能充分捕捉用户的上下文信息;此外,用马尔可夫链方法来建模序列依赖,往往只是在稀疏的数据集上效果最佳,随着数据量的增多,马尔可夫链的转移矩阵不能建模更加复杂的序列依赖。
1.2 基于深度学习的序列推荐
目前,循环神经网络、门控循环单元、长短期记忆网络被广泛用于推荐系统中的用户行为序列建模。利用循环神经网络和推荐损失函数将用户的历史交互编码成一个可以表示用户偏好的向量,然后根据这个向量来进行预测,然而,基于RNN的序列推荐算法捕捉用户序列的长期依赖效果不好。除了RNN,Tang等[12]和Yuan等[13]还提出了卷积序列模型,该模型采用垂直和水平的卷积滤波器来学习用户行为序列,但卷积序列模型无法同时兼顾用户的长期偏好和短期偏好。随着技术的不断发展,卷积神经网络也被广泛应用在医学领域,将双向门控循环单元(gated recurrent unit,GRU)和卷积神经网络(convolutional neural network,CNN)相结合可以提取药物之间的相互作用[14]。
2015年Chorowski等[15]提出了注意力机制,他们将注意力机制应用于机器翻译和文本分类任务中,并取得了较好的结果,由此证明注意力机制可以捕获语言中的长期依赖关系。在会话序列推荐中引入注意力机制[16],可以全面捕获序列中用户的短期偏好;Li等[17]结合物品的绝对位置和相对时间间隔的编码优点,在SASRec模型中加入了可感知时间间隔的自注意力机制去学习不同物品的绝对位置和相对时间间隔的权重,以此来预测下一个物品。BERT(bidirectional encoder representations from Transformers)模型在自然语言处理上[18]的原理是利用自监督学习在大规模的无标注语料上进行训练,从而捕捉文本的语义信息。用户行为序列与文本序列存在很多相同之处,因此Sun等[19]在SASRec模型上提出了用于自然语言处理的BERT模型,如果直接将BERT模型用在序列推荐上,会导致数据泄露,为了解决该问题并有效训练双向模型,引入BERT模型的同时加入填空任务(cloze task),通过对用户行为序列左右背景的共同调节来预测序列中的随机掩码(mask)物品。尽管基于注意力机制的模型[5]在序列推荐中都达到了比较好的效果,可高频出现的物品会集中在表征空间里的一小块区域,导致推荐模型的表征退化,影响序列推荐的性能。本文引入高斯噪声做数据增强且采用物品的自身作为正样本对,以优化表示空间的一致性(uniformity)。
2 模型
本文在SASRec模型的基础上,在表征空间里加入了高斯噪声,引入了自监督图学习(self-supervised graph learning,SGL)的对比学习损失函数[8]。如图1所示,本文模型含有2层的Transformer,第二层学习到的是第一层所有位置的信息,而不是像基于RNN的序列推荐模型,只学习向前传递的相关信息。此外,为了更有效地训练模型,将需要预测的物品用一个特殊符号(无意义)代替,再通过联合物品左右的上下文信息来对其进行预测。本文模型相较于基于RNN的从左到右的单项推荐模型,自注意力机制可以捕获任意位置物品的信息,避免了信息的遗漏。通过这种方式,所提出的模型可以获得更强大的用户行为序列,以提高推荐性能。引入对比学习,在表征空间中加入随机的高斯噪声做数据增强不仅能提高序列推荐模型的鲁棒性,而且该方法对基于知识图谱的推荐模型也有同样的改进效果,并能提高模型推荐的准确性。
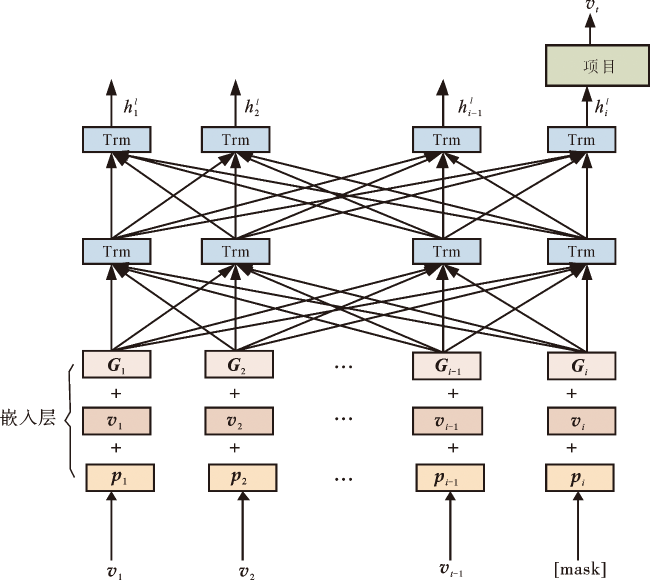
2.1 嵌入层(embedding layer)
在没有任何递归或卷积模块的情况下,变换器层(Trm)不知道输入序列的顺序。为了利用输入的顺序信息,将位置信息注入嵌入层中。此外,为了防止高频出现的物品集中在表征空间的一小块区域,将服从正态分布的高斯噪声注入嵌入层中,以达到数据增强的效果。将训练的物品序列转化成有固定长度的序列S=(v1,v2,…,vt),其中t表示模型可处理的最长序列长度,若输入的物品序列长度小于t,则对序列中的缺失值用0进行填充,若输入的物品序列长度大于t,则将大于t以后的序列长度截断。
= 。
式中: 表示嵌入层最终输出的物品序列矩阵; 表示输入的序列矩阵;Pi表示序列中物品的位置矩阵;Gi表示加入嵌入层的噪声矩阵。
2.2 Transformer层
如图1所示,给定长度为t的用户行为序列,通过迭代计算每个位置i的每个层l处的隐藏表示 ,由于在实验中需要同时计算所有位置上的注意力函数,所以本文将隐藏表示 叠加到矩阵中。Transformer是由多头自注意力机制(multi-head self-attention)和前馈神经网络(feed-forward network,FFN)两个部分组成。
2.2.1 多头自注意力机制
注意力机制已经成为各种任务中序列建模的一个组成部分,允许捕获表示对之间的依赖关系,而不考虑它们在序列中的距离。多头注意力首先用不同的、可学习的线性投影将Hl映射成h个子空间,然后并行应用h个注意力函数来产生输出表示,这些输出表示被连接并再次投影。设输入为 ,首先是多头自注意力机制过程:
S=SA()=At(WQ, WK, WV),
At(Q,K,V)=Softmax V。
式中:SA(E)表示多头注意力机制层的输出矩阵;WQ、WK、WV表示可学习的参数矩阵;d表示维度。其次是Dropout和残差连接(Add)与层归一化(Norm)过程,Add的目的是防止反向传播时梯度消失的问题,Norm是层归一化操作。
2.2.2 mask
由于序列存在复杂的长期依赖关系,模型在预测t样本的时候需考虑前t-1个样本,而自注意力层(self-attention layer)的本质是全连接的,即self-attention不仅会考虑前t-1个样本,还会考虑t样本以后的物品,为了保证预测的准确性,将模型要预测的第t个样本用mask(只是一个普通的占位符)表示作为模型的输入。
2.2.3 FNN
如上所述,自注意层主要基于线性投影。虽然self-attention能将前t-1个样本使用自适应的权重进行集成,但它仍然是一个线性模型,为了加入非线性能力,本文将每个位置的前馈网络用于自注意子层的输出:
Fi=FFN(Si)=GELU(SiW(1)+b(1))W(2)+b(2)。
式中:FFN(Si)表示每个位置的前馈网络用于自注意子层的输出;W(1)、W(2)表示d×d的参数矩阵;b(1)、b(2)表示维度为d的向量;本文使用更平滑的激活函数[20]GELU。
2.2.4 Transformer层堆叠(stacking Transformer layer)
3 主要方法
3.1 基于高斯噪声的数据增强方法
学习高质量句子表示对于各种自然语言处理任务至关重要。尽管基于BERT的预训练语言模型在许多下游任务上有显著性能,但其所产生的句子表示被证明存在崩塌问题,因此在语义文本相似度(semantic textual similarity,STS)任务上表现不佳。文本数据增强在自然语言处理中扮演着关键角色,然而,许多现有的增强方法无法确保语义一致性,且每次数据增强都需要执行模型推理,增加了计算成本。因此,研究人员为解决这一问题,探索了4种在嵌入层隐式生成增强样本的方法,分别是通过梯度反传生成对抗性扰动(Adversarial Attack)、打乱样本词序(Token Shuffle)、随机将词元(token)的整行或整列置为0(Feature Cutoff)、随机将token置为0(Dropout)。
1)Adversarial Attack:对抗性训练通常用于提高模型的鲁棒性。通过向输入样本添加扰动来生成对抗性样本,使用快速梯度值(fast gradient value,FGV)来实现这一策略,但该策略仅适用于与监督联合训练,因为它依赖于监督损失来计算对抗性扰动。
2)Token Shuffle:随机打乱输入序列中标记的顺序。由于 Transformer 结构没有“位置”的概念,模型对token位置的感知全靠嵌入中的位置标识(positionids)得到。因此在实现上,只需要打乱位置标识即可。
3)Feature Cutoff:又可以进一步分为两种。Token Cutoff:随机选取token,将对应token的嵌入整行置为零。Feature Cutoff:随机选取嵌入的特征,将选取的特征维度整列置为零。
4)Dropout:是一种广泛使用的正则化方法,可以避免过拟合。与筛选(Feature Cutoff)不同的是,该方法中的每个元素都是单独被考虑的。
这4种数据增强方法都通过对嵌入矩阵的修改实现,相较于显式生成样本的方法更为高效。根据单种数据增强方法的效果,可以将这4种方法进行排序:Token Shuffle>Token Cutoff>Feature Cutoff>Dropout>无。
在序列推荐中,数据结构复杂且存在许多复杂的长期依赖关系。在神经网络模型训练期间添加噪声进行数据增强可以产生正则化效果,从而提高模型的鲁棒性。文献[22]摒弃了图增广方法,通过向输入图像添加难以察觉的小扰动来构建对抗性样本,并利用对比学习获得更均匀的用户-物品表示。这种方法可以减轻流行度偏差,并平滑地调整学习表示的一致性。本文也采用类似的方法,在表征空间中添加随机的高斯噪声以实现有意义的数据增强,从而避免高频物品在表征空间中过度集中。高斯噪声的概率密度函数服从高斯分布(正态分布),如式(5),是几乎每个点上都出现高斯噪声、噪点深度随机的噪声。
高斯分布
f(x)= 。
式中:μ表示均值;σ表示方差。形式上,给定物品序列i及其在d维表征空间中的表示ei,可以实现如下的表示增强:
=ei+η'i, e″i=ei+η″i,
∈Rn。
式(6)中的η'i和η″i表示高斯噪声向量且η'i、η″i服从高斯分布。此外,式(6)中η的约束如式(7),第一个约束条件是控制噪声向量η的大小,η在数值上相当于图2中半径为ε的超球面上的点;第二个约束条件是要求ei、η'和η″位于同一超象限,这样加入高斯噪声不会使ei存在很大的偏差,导致表征空间里的有效样本减少。
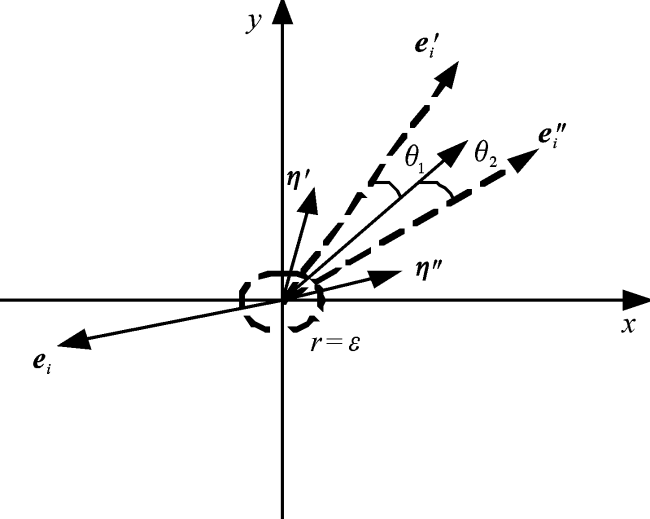
如图2所示,将服从正态分布的高斯噪声添加在原始表示上可以被看作是原始表征向量ei在空间上旋转了两个较小的角度θ1和θ2,当旋转角度θ1和θ2很小时,既保留了大部分的原始信息,同时也带来了语义上的不同。在每一层,不同比例的高斯噪声被随机地施加到当前物品嵌入上。最终的扰动表示如下:
E= [(E(0)+η(1))+((E(0)+η(1))+η(2))+…+(E(0)+ η(1)+…+ η(L-1)+η(L))]。
高斯噪声是一种随机的、连续的信号,其统计特性可以由均值和方差来描述。参数对RS(reed-solomon)编码的性能影响主要体现在错误检测与纠正能力上。RS编码是一种具有强大纠错能力的编码技术,可以在有限的冗余信息下实现对信号的纠错。以下讨论高斯噪声参数对RS编码性能的影响。
噪声方差(noise variance):高斯噪声的方差表示噪声幅度的大小。方差越大,说明噪声幅度越大,对于RS编码来说,可能导致更多的错误位。因此,当高斯噪声的方差增大时,RS编码的纠错能力会下降。
信噪比(signal-to-noise ratio, SNR):SNR是信号功率与噪声功率之比。在高斯噪声情况下,SNR越大,表示信号相对于噪声的强度越大,RS编码的纠错能力越好。因此,当SNR较高时,RS编码能够更好地纠正信道中的错误。
高斯噪声的参数,特别是方差和SNR,对RS编码的性能有显著影响。较小的噪声方差和较高的SNR将有助于提高RS编码的纠错能力,而较大的噪声方差和较低的SNR则会降低RS编码的性能。本论文受以上启发,将排在最前面的 Token Shuffle 数据增强方法引入序列推荐模型的嵌入空间,把序列数据中用户行为序列的顺序打乱,再送入对比学习进行训练,拉近相似样本间的距离,推远不相似样本间的距离,将其结果与上述基于高斯噪声的数据增强方法做对比,发现相较于Token Shuffle 数据增强方法,在嵌入空间加入高斯噪声做数据增强的方法对SASRec模型的流行度偏差问题有较好的改进。
3.2 推荐系统中的对比学习
近年来,对比学习在计算机视觉和自然语言处理领域的应用越来越广泛,在推荐系统中当然也不例外。将对比学习与推荐系统相结合的原因有四点:
1)对比学习可以有效解决推荐系统中数据稀疏性问题。
2)对比学习可以通过自监督对推荐系统中用户行为很少的长尾商品进行增强。
3)对比学习可以解决在跨领域推荐中不能融合多个视图信息的问题,增强网络的表达能力。
4)可通过mask和Dropout增强模型的鲁棒性。
近年来,对比学习在推荐系统中的运用取得了显著的进展。SimGCL[23-24]与XSimGCL[25-26]两个模型都在推荐系统中引入对比学习,SimGCL模型提出了将一种极其简单的图对比学习方法应用于推荐系统,XSimGCL模型舍弃图增强,采用了一种简单而有效的基于噪声的嵌入增强方法来生成对比视图,进而改进推荐系统的准确性和训练效率。Wang等[27]已经明确表示,优化对比学习损失函数会增强视觉表示学习中的两个属性:正样本对特征的对齐以及单位超球体上归一化特征分布的均匀性。本节将用于推荐的简单图对比学习方法(SimGCL)应用于序列推荐中,该方法可以平滑地调节特征分布的均匀性并提高模型的泛化能力。受到基于对比学习的图推荐模型SGL的启发,本文使用高斯噪声增强原始的物品序列,并采用SGL模型的损失函数来最大化正样本对的一致性,而弱化负样本对的一致性。SGL中的联合学习公式如下:
Ljoint=Lrec+λLcl。
式中:Lrec表示推荐损失;Lcl表示对比学习损失;λ表示对比学习损失在联合损失中所占的比例。对比学习中的损失函数在SGL被定义为
Lcl= -ln 。
式中:i、j表示物品序列;Z'表示原始的物品序列;Z″表示加数据增强后的物品序列;τ表示大于0的温度。优化Lcl损失会得到更均匀的表示分布,有助于在推荐场景中消除偏差。Lcl可以最大化Z'i和Z″i之间的相似度且两者互为正样本对,最小化互为负样本Z'i和Z″j之间的一致性。
通过将在表征空间加入高斯噪声做数据增强后的物品序列与原始的物品序列形成样本对,然后将形成的样本对输入对比学习模型中,本文预期该模型框架将会拉近相似样本间的距离,且推远不相似样本间的距离,从而减轻SASRec模型中的流行度偏差,该方法可以显著增强推荐性能。
3.3 修改后的对比学习算法
| 算法 对比学习模型训练 输入:训练数据集D = {(xi,yi)};学习率rl;批量大小Sbatch;迭代次数nepochs。 过程: 1. 使用高斯增强方法对输入样本D进行数据增强,得到增强后的样本集D' 2. 初始化对比学习模型M,包括高斯增强网络G和自注意力网络A 3. 初始化优化器optimizer,使用学习率rl 4. for epoch = 1 to nepochs do 4.1 随机打乱增强后的样本集D' 4.2 将D'分成大小为Sbatch的小批量数据集B,其中每个批次包含多个(x,y)对 //注意:这里的 batch 实际上是一个包含多个(x,y)对的集合 4.3 for batch ∈ B do 4.3.1 初始化一个空列表 batch_zs 用于存储表示向量Z 4.3.2 for (x, _) ∈ batch do //忽略y,因为在这个对比学习场景中可能不需要它 end for 4.3.2.1 使用M中的高斯增强网络G进行前向传播,计算增强后的样本的表示向量Z=G(x) 4.3.2.2 将Z添加到 batch_zs 列表中 4.3.3 将 batch_zs 中的所有Z传递给自注意力网络A,计算注意力权重W=A(batch_zs) 4.3.4 根据 batch_zs和W(以及其他可能的规则)计算正样本对的表示向量Zp和负样本对的表示向量Zn //注意:这里需要定义一个机制来从batch_zs中选择正样本对和负样本对 4.3.5 计算对比损失函数Lcontrastive(Zp,Zn) 4.3.6 使用Lcontrastive进行反向传播 4.3.7 使用优化器optimizer更新模型M的参数 end for end for 5.算法结束,返回训练好的对比学习模型M |
在上述算法中,我们首先使用高斯增强方法对输入样本进行数据增强,以扩充训练数据集。然后,通过迭代训练过程,使用对比损失函数来优化对比学习模型。模型中包括高斯增强网络G和自注意力网络A。高斯增强网络用于对输入样本进行增强,生成增强后的样本的表示向量。自注意力网络用于计算注意力权重,以区分正样本对和负样本对的表示向量。最后,使用反向传播和参数更新来更新模型的权重。训练过程中输出损失函数的平均值,以监控模型的训练进程。
4 实验结果与分析
4.1 数据集
本文使用Movielens-1m和Yelp作为实验数据集,这两个公开数据集在推荐系统领域内都是经常被使用的。Movielens-1m数据集主要记录了6 000多个用户对3 000对各电影的评分和电影的种类信息,Yelp和Movielens-1m的具体信息如表1。
表1 数据集信息表Tab.1 Dataset information table |
| 数据集 | 用户数 | 项目数 | 交互数 |
|---|---|---|---|
| Movielens-1m | 6 041 | 3 707 | 1 000 209 |
| Yelp | 45 478 | 30 709 | 1 777 765 |
4.2 超参数
为了进行公平比较,在原始论文中最佳超参数设置的基础上,通过网格搜索对基线的所有超参数进行微调。超参数设置情况如表2所示。
表2 超参数设置情况表Tab.2 Hyperparameter setting table |
| 实验超参数 | 具体设置数值 |
|---|---|
| 学习率 | 0.001 |
| Dropout | 0.1 |
| 优化函数 | Adam |
| 激活函数 | GELU |
| 嵌入维度 | 64 |
| epoch | 300 |
4.3 比较模型及评价指标
将对比实验设置成SASRec(一种基于Transformer结构的序列推荐)、SASCTS(基于对比学习方法的序列推荐模型)、BERT4Rec(采用深度双向self-attention来建模用户行为序列的模型)、GRU4Rec[28](基于RNN的模型)。
在实验中,将数据集分成3个部分(训练集、验证集和测试集),其比例为8∶1∶1,把每个物品序列的最后一个项目用作测试样本,倒数第二个项目用作验证样本,其余的项目作为训练样本。使用两个常见的评价指标:召回率(recall,记作Rc)和归一化折损累计增益(normalized discounted cumulative gain,记作gNDC),将结果范围K设置为10。
1)召回率Rc,表示前10中正确检索到的推荐物品占所有应该检索到的推荐物品的比例。
2)归一化折损累计增益gNDC,表示前10中推荐物品的返回顺序的评价指标,推荐物品越靠前其值越大。
4.4 SASRec模型简介
在推荐系统中,SASRec是用于改进序列推荐任务的一种模型,与传统的序列推荐模型(如基于马尔可夫链的序列推荐模型、基于循环神经网络的序列推荐模型等)不同,SASRec模型利用自注意力机制可减少对外部信息的依赖,更容易捕捉特征间的内在特性这一核心思想来学习序列推荐中不同物品之间的长期依赖关系,且自注意力机制能够高效地处理长序列。该模型有效地减少了模型中的信息丢失度,但模型遇到了表征退化的问题,即高频出现物品集中在表征空间的一小块区域。
4.5 实验结果分析
4.5.1 整体性能分析
表3记录了本文模型与基准模型的实验结果比较,根据实验结果表的数据可以看出,在Movielens-1m数据集上,SASCTS模型在评价指标Rc和gNDC上的实验结果比SASRec模型好,而在表示空间里加入高斯噪声做数据增强后的模型(SASCTS GN)在两个评价指标上的性能均得到了提高。本文模型相较SASRec模型在Movielens-1m数据集上的评价指标Rc提升了5.6%,gNDC上提升了4.3%。在Yelp数据集上的数据信息也显示了SASCTS GN模型在两个评价指标上比SASRec模型和SASCTS模型有所提升,评价指标Rc上升了3.3%,gNDC上升了1.1%。
表3 实验结果表Tab.3 Experimental result table |
| 数据集 | 模型 | 指标 | |
|---|---|---|---|
| Rc | gNDC | ||
| Movielens-1m | BERT4Rec | 0.129 8 | 0.071 9 |
| GRU4Rec | 0.281 0 | 0.161 8 | |
| SASRec | 0.254 3 | 0.135 9 | |
| SASCTS | 0.301 3 | 0.177 0 | |
| SASCTS GN | 0.310 9 | 0.179 0 | |
| Yelp | BERT4Rec | 0.045 1 | 0.022 8 |
| GRU4Rec | 0.052 7 | 0.026 0 | |
| SASRec | 0.060 0 | 0.031 4 | |
| SASCTS | 0.060 4 | 0.031 5 | |
| SASCTS GN | 0.063 3 | 0.032 5 | |
4.5.2 嵌入维度分析
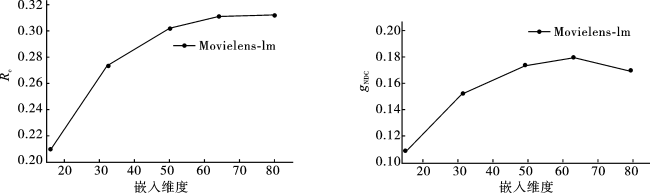
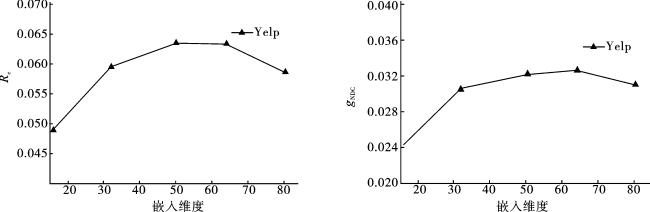
由图3可以清晰地看出,模型的两个评价指标Rc和gNDC刚开始随着嵌入维度的增大而有明显的提升,当嵌入维度大于64时,模型性能提升的速度逐渐变慢并趋于稳定。由此可以得到,模型在嵌入维度为64时已经获得了充分的训练。
4.5.3 评价指标分析
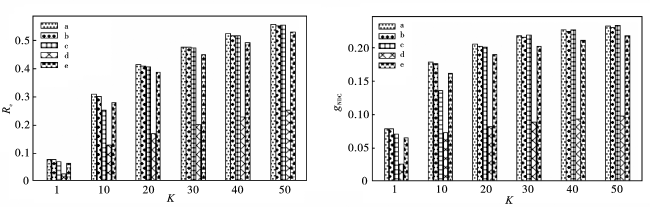
图5显示了SASCTS GN模型和SASRec、SASCTS、BERT4Rec、GRU4Rec 4种基准模型在Movielens-1m上的Rc、gNDC的实验结果,将K分别设置成1、10、20、30、40、50;a表示SASCTS GN模型,b表示SASCTS模型,c表示SASRec模型,d表示BERT4Rec模型,e表示GRU4Rec模型。结果显示,与b、c、d、e 4个基准模型相比较,本文模型在Rc和gNDC两个评价指标上都具有明显的优势。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5 结语
本文在序列推荐的表征空间里加入高斯噪声,通过噪声扰动做数据增强并以物品自身构建正样本对,然后通过对比学习将相似样本间的距离拉近,推远不相似样本间距离的同时让不同样本在表征空间里的分布呈现均匀性,防止高频出现的物品集中在表征空间里的一小块区域而增强流行度偏差。实验结果也充分表明本文模型对推荐性能的提升有积极作用。