

白内障是指晶状体透明度降低或颜色改变的一种退行性病变[1]。随着中国老龄化进程加速,其患病率逐年攀升,我国因白内障致盲人数位居世界首位[2]。白内障超声乳化是其最有效的治疗方法。机器人手术的迅速发展,使得医生可以远离手术台进行手术。手术器械的语义分割是机器人辅助手术稳定合理操作的关键环节[3],精确定位手术器械并正确估计手术器械姿态,可以更好地帮助医生评估手术器械与人体组织的相互作用。此外,手术器械语义分割还有手术器械包装检查[4]、实时手术提醒、手术技能客观评估、手术报告生成、手术工作流程优化等诸多应用前景[5]。白内障手术器械的语义分割也因此受到越来越多学者的关注。
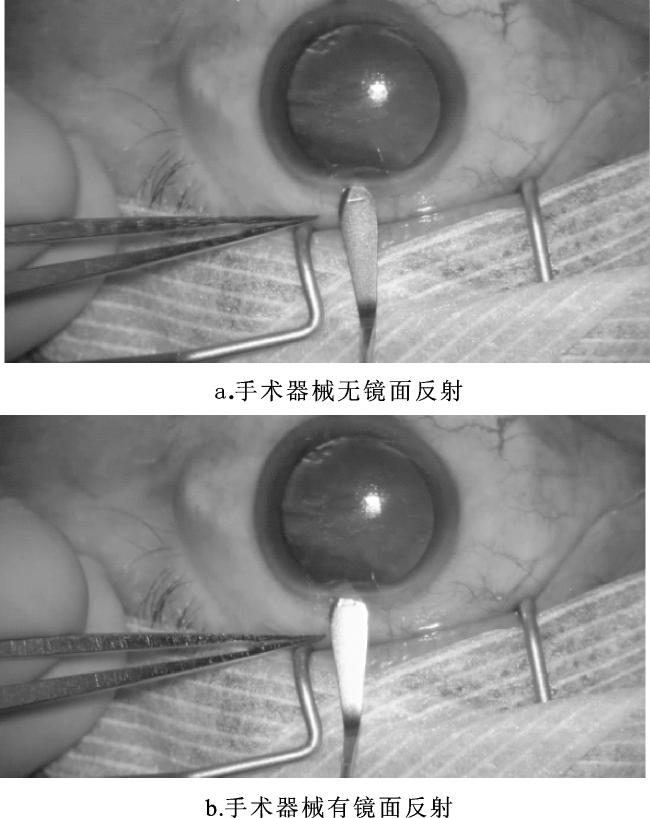
目前,手术器械分割依然面临一些难题,比如手术器械种类多样,手术过程中器械的运动和姿态的改变均会造成手术器械影像尺度、形状发生较大变化;白内障手术在较强光照条件下进行,导致手术器械产生镜面反射,影响手术器械颜色、纹理等视觉表现,阻碍手术器械的稳定识别,如图1所示。
对大规模数据的依赖阻碍了视觉Transformer(vision Transformer,ViT)[6]在数据集较小的医学图像处理领域的广泛应用[7]。因此,常使用卷积神经网络实现对白内障手术器械的分割,例如DenseNet[8]、DeepLabV3+[9]、Unet[10]等经典网络。
Ni等[11]构建了第一个用于语义分割的白内障手术器械数据集,将Unet作为基线模型,在跳跃连接部分采用了增强注意力模块,有效地融合多层次特征,解决了白内障手术过程中器械影像尺度变化问题。为了应对强烈光照引起的镜面反射问题,Ni等[12]继而提出一种金字塔注意聚集网络。双注意力模块通过捕获全局上下文关系,有效地区分目标区域,帮助解决镜面反射问题,并且提出的金字塔上采样模块学习手术器械在不同感受野的形状和大小特征,解决了手术器械影像尺度变化问题。Ni等[13]后续又提出一种具有自适应接受域的双线性注意网络用于白内障手术器械分割,双线性注意模块捕获全局上下文和二阶统计数据来改进特征表示,自适应接受域选择具有特定大小的特征图来选择合适的感受域,可以较好地提升网络性能。
Ghamsarian等[14]提出AdaptNet网络,加入了级联池化融合(CPF)和形状自适应特征融合(SSF)模块,显著地提高了网络的分割性能。Ghamsarian等[15]针对白内障手术中精准分割不同相关结构的问题设计了金字塔视图融合模块和可变形金字塔接受模块,可以较好地捕获卷积特征图中每个像素位置周围区域的全局视图,可形变的接受域也能更好地适应感兴趣对象的几何变化,能够克服白内障手术器械分割中运动模糊、反射变形等问题。
如何克服镜面反射以及应对白内障手术器械影像尺度变化,是白内障手术器械分割任务面对的主要挑战。这两大主要挑战导致现有的模型难以有效地提取手术器械的特征,难以对白内障手术器械实现精细化分割。过去的研究工作大多基于U型网络结构,围绕如何更有效地进行特征提取与特征融合展开,却忽略了U型网络结构本身的限制,也没有考虑到临床中手术器械大多呈现为有规则的条状或棒状物品。现有的分割网络在分割时都能将目标主体大致分割出来,造成误差的地方主要集中在目标与背景边界的识别。因此,在进行模型构建时,除了需要围绕如何更好地提取与融合手术器械的有效特征外,对手术器械边缘特征的提取与融合也同样重要。
受到前述研究的启发,本文提出了一种增强边缘特征的双注意力网络EE-DANet(dual attention network based on enhanced edge features)。本文的主要工作包含以下3个部分。
1)手术器械分割中手术器械形状各异,即使是相同手术器械也存在不同姿态。针对此问题,在解码器端改进了一种多尺度特征融合模块(multi-scale feature fusion module,MFFM)。使用不同大小卷积核的条形卷积,既能高效地捕获图像多尺度信息,同时能够减少网络参数。
2)针对白内障手术过程中存在强烈光照导致分割过程中手术器械存在严重镜面反射问题,本文增强了解码器的特征提取与融合能力。在特征融合模块(feature fusion module,FFM)中不仅使用可形变卷积,还提出一种条形坐标注意力(strip coordinate attention,SCA),对图像进行全局建模,建立长距离依赖,更好地捕获条状物体。
3)针对U型网络分割图像边界模糊以及细节特征丢失的问题,在网络中加入边缘分支弥补网络下采样丢失的空间信息,促进语义信息与边缘信息融合。边缘分支设计了一种增强空间注意力(augmented spatial attention,ASA),能够更好地平衡不同层次特征中边缘信息与语义信息。
1 本文方法
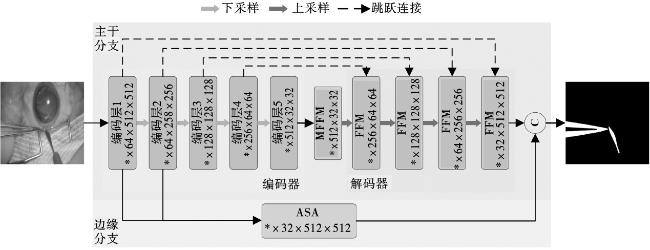
1.1 多尺度特征融合模块MFFM
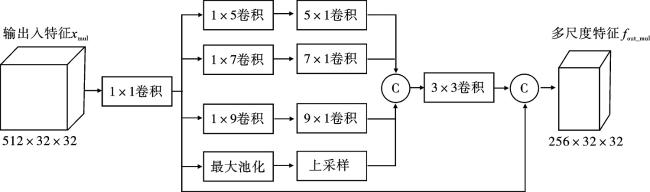
面对输入特征xmul,MFFM首先采用一个1×1卷积减少通道数量。再将所得特征图fmul输入4个并行的分支中,通过不同尺度的感受野来提取图像深层多尺度的语义信息,其中一条分支为串联的全局平均池化层和上采样层,上采样方法采用双线性插值法,其余3个分支是卷积核分别为5、7、9的一组条形卷积,如式(1)~(5)。
$f_{\mathrm{mul}}=\operatorname{Conv}_{1 \times 1}\left(x_{\mathrm{mul}}\right),$
$f_{\mathrm{mul} 1}=\operatorname{Conv}_{5 \times 1}\left(\operatorname{Conv}_{1 \times 5}\left(f_{\mathrm{mul}}\right)\right),$
$f_{\text {mul2 }}=\operatorname{Conv}_{7 \times 1}\left(\operatorname{Conv}_{1 \times 7}\left(f_{\text {mul }}\right)\right),$
$f_{\mathrm{mul} 3}=\operatorname{Conv}_{9 \times 1}\left(\operatorname{Conv}_{1 \times 9}\left(f_{\mathrm{mul}}\right)\right),$
$f_{\text {mul }}=\operatorname{Upsample}\left(\operatorname{GAP}\left(f_{\text {mul }}\right)\right) \text { 。 }$
式中:Conv(·)表示卷积操作;GAP(·)表示全局平均池化;Upsample(·)表示上采样。
条形卷积不仅可以减少参数量,手术器械大多是条形,使用条形卷积也有助于提取分割场景中的条形特征。接着将4个分支提取到的多尺度特征fmul1、fmul2、fmul3、fmul4拼接融合,最后与特征fmul再次拼接,得到图像的多尺度特征fout_mul。特征生成方法如式(6)与式(7)所示。
$\begin{aligned}f_{\text {out_mul }}= & \operatorname{Cat}\left(\operatorname{Conv}_{3 \times 3}\left(\operatorname{Cat}\left(f_{\text {mull }}, f_{\text {mul2 }}, f_{\text {mul3 }}\right)\right),\right. \\& \left.f_{\text {mul }}\right),\end{aligned}$
$f_{\text {out_mul }}=\operatorname{ReLU}\left(\operatorname{BN}\left(\operatorname{Conv}_{3 \times 3}\left(f_{\text {out_mul }}\right)\right)\right) 。$
式中:Cat(·)表示拼接操作;BN(·)表示批归一化层;ReLU(·)表示ReLU激活函数。
1.2 特征融合模块FFM
特征融合模块FFM位于解码器,用于融合不同层级的图像特征,如图4所示。
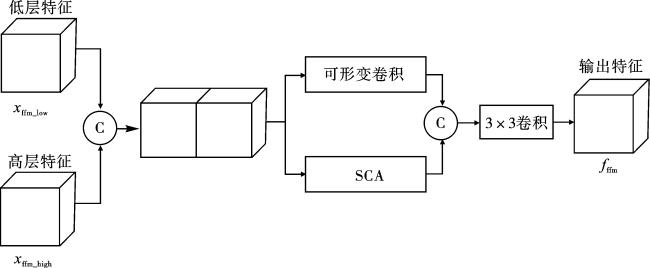
来自编码器的低层特征xffm_low与来自上一层解码器的高层特征xffm_high拼接得到特征xffm_0。将所得特征输入到2个平行分支,一个分支是可形变卷积模块,另一个是条形坐标注意力SCA。可形变卷积模块通过改变卷积核的采样点位置适应输入特征,能够更好地应对白内障手术器械种类、形状多样的问题。SCA通过使用不同方向的条形池化捕获图像的全局信息,其中蕴含的位置信息也可以使网络更好地关注镜面反射导致的手术器械与眼部组织对比度低的地方,也能更好地克服手术器械镜面反射的问题。最后将2个分支得到的输出特征进行拼接、卷积,得到新的特征fffm。生成方法如式(8)、式(9)所示。
$f_{\mathrm{ffm}-0}=\operatorname{Cat}\left(x_{\mathrm{ffm} \_ \text {low }}, x_{\mathrm{ffm} \text { _high }}\right),$
$\begin{aligned}f_{\text {ffr }}= & \operatorname{Conv}_{3 \times 3}\left(\operatorname { C a t } \left(\operatorname{Conv}_{\text {deform }}\left(f_{\text {ffm } \_0}\right),\right.\right. \\& \left.\left.\operatorname{SCA}\left(f_{\text {ffm } \_0}\right)\right)\right) 。\end{aligned}$
式中:SCA(·)表示条形坐标注意力模块;Convdeform(·)表示可形变卷积模块。
普通卷积对输入特征图的固定位置进行采样,在提取空间信息上存在天然不足。同一卷积层的激活单元具有相同的感受野,导致采样得到的信息中包含很多背景特征。可形变卷积通过对卷积核中每个采样点增加偏移量,使得卷积核采样点偏移,不拘泥于规则的格点,使卷积采样点集中于感兴趣区域,增强网络特征提取能力。
为了解决白内障手术器械分割中的镜面反射问题,本文设计的条形坐标注意力SCA如图5所示。手术器械大多数呈狭长的条形,使用条形坐标注意力不仅能捕获跨通道信息,还能捕获方向和位置敏感信息,可以有效地克服镜面反射问题。
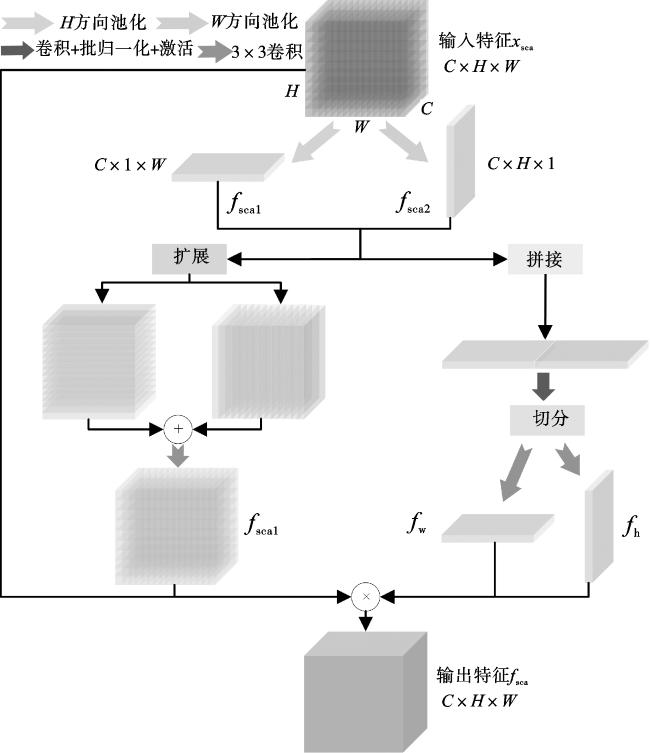
以输入特征xsca的一个通道特征图为例,首先条形坐标注意力对输入的H×W特征分别在H方向与W方向进行平均池化,得到1×W的特征fsca1与H×1的特征fsca2,如式(10)与式(11)所示。
$f_{\mathrm{scal}}=\operatorname{Pool}_{H \times 1}\left(x_{\mathrm{sca}}\right),$
$f_{\mathrm{sca} 2}=\operatorname{Pool}_{1 \times W}\left(x_{\mathrm{sca}}\right) \text { 。 }$
式中:PoolH×1(·)表示H方向的平均池化操作;Pool1×W(·)表示W方向的平均池化操作。
其次,将特征fsca1和特征fsca2分2个分支进行特征提取。其中一条分支将特征fsca1的H通道与W通道进行互换, 与特征fsca2拼接。 经卷积归一化
激活后再进行切分,得到特征fsca_w、fsca_h。分别卷积、激活后得到注意力权重fw、fh,如式(12)~(14)所示。
$f_{\text {sca_w }}, f_{\text {sca_h }}=\operatorname{Split}\left(\operatorname{Conv}_{1 \times 1}\left(\operatorname{Cat}\left(f_{\text {scal }}, f_{\text {sca2 }}\right)\right)\right),$
$f_{\mathrm{w}}=\operatorname{Sigmoid}\left(\operatorname{Conv}_{3 \times 3}\left(f_{\text {sca }-\mathrm{w}}\right)\right),$
$f_{\mathrm{h}}=\operatorname{Sigmoid}\left(\operatorname{Conv}_{3 \times 3}\left(f_{\text {sca_h }}\right)\right) \text { 。 }$
式中:Split(·)表示对特征图进行切分;Sigmoid(·)表示Sigmoid激活函数。
另一条分支将特征fsca1、fsca2扩展为H×W大小,再将得到的特征对应位置相加得到特征,经过激活后得到注意力权重fsca_1,如式(15)所示。
$\begin{aligned}f_{\text {sca } 1}= & \operatorname{Sigmoid}\left(\operatorname { C o n v } _ { 3 \times 3 } \left(\operatorname{Expand}\left(f_{\text {scal }}\right)+\right.\right. \\& \left.\left.\operatorname{Expand}\left(f_{\text {sca2 }}\right)\right)\right) 。\end{aligned}$
式中,Expand(·)表示扩展操作。
最后,将原始特征xsca与得到的特征fw、fh和fsca_1对应元素相乘,得到融合坐标注意力的特征。条形坐标注意力SCA生成方法如式(16)所示:
$f_{\text {sca }}=x_{\text {sca }} \times f_{\text {sca_w }} \times f_{\text {sca_h }} \times f_{\text {sca_1 } 10}$
1.3 增强空间注意力ASA
在编码过程中,经典U型结构的下采样操作将不可避免地造成图像丢失一些空间信息,导致网络对边界附近像素误分类,无法精准分割图像边缘,图像分割边界模糊以及部分区域丢失,即使通过跳跃连接这些空间信息也无法轻易弥补。因此,构建了边缘特征提取模块,帮助网络更好地融合边缘特征。
低层特征虽然包含边缘、纹理等图像基本特征,但也包含大量无用的背景信息,这些信息在一定程度上会干扰目标对象的分割。高层特征包含了丰富的语义信息,能够更好地描述物体的外观和语义信息。增强空间注意力模块的主要思想就是使用包含语义信息较多的高层特征,指导包含语义信息少但是边缘信息多的低层特征。
与编码层2提取的特征相比,编码层1提取特征拥有更多的边缘信息与更少的语义信息,增强空间注意力ASA如图6所示。
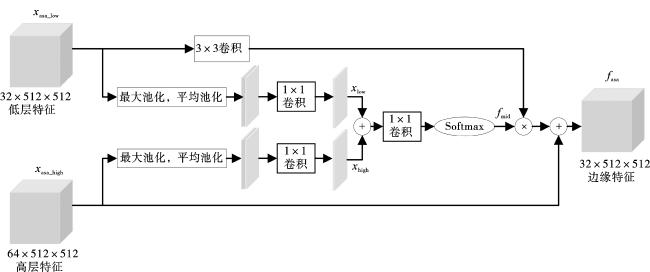
增强空间注意力模块首先对网络中编码层1提取的低层特征xasa_low与编码层2提取的高层特征xasa_high在通道维度上分别进行最大池化与平均池化,以融合同一位置不同通道的信息,得到特征xlow和xhigh。再经过相加、卷积得到空间注意力图fmid,并对低层特征重新赋予权重。最后,将得到的融合高层语义信息的边缘特征与高层特征融合得到图像的边缘特征fasa。
ASA注意力向量生成方法描述如式(17)~(20)所示。
$\begin{aligned}x_{\text {low }}= & \operatorname{Conv}_{1 \times 1}\left(\operatorname { C a t } \left(\operatorname{GAP}\left(x_{\text {asa_low }}\right)+\right.\right. \\& \left.\left.\operatorname{GMP}\left(x_{\text {asa_low }}\right)\right)\right),\end{aligned}$
$\begin{aligned}x_{\text {high }}= & \operatorname{Conv}_{1 \times 1}\left(\operatorname { C a t } \left(\operatorname{GAP}\left(x_{\text {asa_high }}\right)+\right.\right. \\& \left.\left.\operatorname{GMP}\left(x_{\text {asa_high }}\right)\right)\right),\end{aligned}$
$f_{\text {mid }}=\operatorname{Sigmoid}\left(\operatorname{Conv}_{1 \times 1}\left(x_{\text {low }}+x_{\text {high }}\right)\right),$
$f_{\text {asa }}=\operatorname{Conv}_{3 \times 3}\left(x_{\text {asa_low }}\right) \times f_{\text {mid }}+x_{\text {asa_high }} \text { 。 }$
式中,GMP(·)表示全局最大池化。

2 实验结果及分析
2.1 实验数据
表1 实验数据集Tab.1 Experimental dataset |
| 数据集 | 手术器械种类 | 分辨率/dpi | 训练集 | 测试集 |
|---|---|---|---|---|
| Dataset_instrument | 白内障手术器械 | 960×540 | 3 190 | 459 |
| Kvasir-Instrument | 胃肠道内窥镜手术器械 | 720×576~1 280×1 024 | 472 | 118 |
2.2 实验环境与参数设置
本文实验在具有NVIDIA GeForce RTX 3090 Ti 型显卡,GPU专用内存 24 GB的机器上完成。实验基于Python 3.8.4与PyTotch 1.11.0的深度学习框架,CUDA版本为11.3。图片分辨率预处理为512×512。使用Adam优化器,初始学习率设置为0.000 1,批处理的大小(batch size)为设置为4,迭代次数为200次。
2.3 评价指标
本文使用的评价指标是语义分割中常见的交并比(intersection-over-union,IoU,记作IoU)与戴斯相似性系数(Dice similarity coefficient,Dice,记作cDice),计算方法如式(21)与式(22)所示。IoU与Dice均是用于评估图像分割模型性能的指标,范围为0~1,比值越高,模型越优越。
$I_{\mathrm{oU}}=\frac{|X \bigcap Y|}{|X \bigcup Y|}=\frac{T_{\mathrm{P}}}{T_{\mathrm{P}}+F_{\mathrm{P}}+F_{\mathrm{N}}},$
$c_{\text {Dice }}=\frac{2|X \bigcap Y|}{|X|+|Y|}=\frac{2 T_{\mathrm{P}}}{2 T_{\mathrm{P}}+F_{\mathrm{P}}+F_{\mathrm{N}}}.$
对于手术器械分割任务,上式中:X表示分割金标准图中的手术器械区域;Y表示预测结果中的手术器械区域;TP表示分类正确的手术器械像素数;TN表示分类正确的背景像素数;FP表示背景像素被分类为手术器械像素的数量;FN表示手术器械被分类为背景像素的数量。
2.4 对比实验
为了验证本文模型的有效性与泛化性,在相同实验环境下,采用11种先进网络与本文模型分别在Dataset_instrument数据集与Kvasir-Instrument数据集上进行训练和测试。实验结果如表2所示。
表2 不同方法在不同数据集的对比实验Tab.2 Comparative experiments of different methods on different datasets |
| 方法 | 参数量/M | Dataset_instrument | Kvasir-Instrument | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IoU/% | Dice/% | IoU/% | Dice/% | ||||||
| Unet(2015)[10] | 7.8 | 68.4 | 79.0 | 86.5 | 91.8 | ||||
| Pspnet(2017)[19] | 46.6 | 68.0 | 78.5 | 88.1 | 92.6 | ||||
| R2Unet(2018)[20] | 9.8 | 67.3 | 77.0 | 77.3 | 86.0 | ||||
| Raunet(2019)[11] | 22.1 | 69.5 | 79.8 | 88.2 | 92.6 | ||||
| Multiresunet(2019)[21] | 7.3 | 62.0 | 72.5 | 84.5 | 90.4 | ||||
| CEnet(2019)[22] | 29.0 | 72.5 | 82.4 | 89.7 | 94.3 | ||||
| HRnet(2020)[23] | 16.3 | 72.0 | 80.3 | 85.9 | 91.4 | ||||
| U2net(2020)[24] | 44.0 | 71.5 | 79.7 | 86.9 | 91.4 | ||||
| Bisenetv2(2021)[25] | 3.6 | 57.8 | 67.8 | 85.5 | 90.9 | ||||
| AdaptNet(2021)[14] | 22.3 | 47.1 | 60.6 | 87.2 | 92.9 | ||||
| DeepPrymid(2022)[15] | 61.3 | 74.4 | 83.3 | 88.9 | 93.9 | ||||
| EE-DANet | 25.3 | 75.5 | 83.9 | 90.6 | 94.6 | ||||
注:加粗数据表示最优结果。 |
从表2可以看出,本文模型EE-DANet在白内障手术器械数据集Dataset_instrument上比其他11种先进模型中分割效果最好的DeepPrymid的IoU和Dice分别高了1.1%和0.6%;比第二名CEnet的IoU和Dice分别高了3.0%和1.5%;在肠胃内窥镜手术器械数据集Kvasir-Instrument上比分割效果最优的CEnet的IoU和Dice分别高了0.9%和0.3%;比第二名DeepPrymid的IoU提高了1.7%。充分表明本文设计的模型在白内障手术器械分割任务上具有优势,且有较好的泛化性,在其他类型手术器械分割任务中也拥有良好表现。
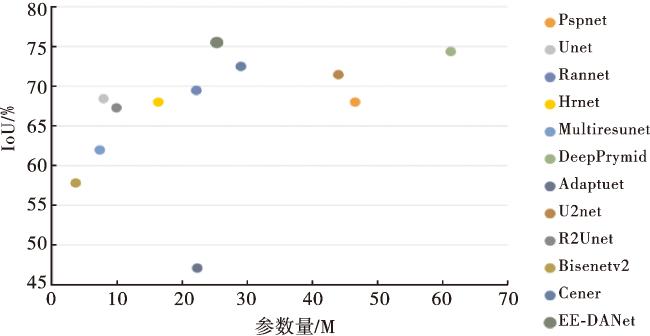
表3 Dataset_instrument数据集上不同编码器的消融实验Tab.3 Ablation experiments of different encoders on the Dataset_instrument |
| 经过预训练的编码器 | IoU/% | Dice/% | 参数量/M | 批处理大小 | GPU内存/GB |
|---|---|---|---|---|---|
| ResNet-18 | 74.5 | 83.2 | 15.2 | 4 | 20.9 |
| ResNet-34 | 75.5 | 83.9 | 25.3 | 4 | 21.8 |
| ResNet-50 | 72.5 | 81.5 | 82.3 | 2 | 20.2 |
注:加粗数据表示最优结果。 |
网络深度越深越能提取到图像中的细节特征,使得网络分割精确率提高,但是随着网络层数的进一步加深,准确率会达到饱和最后逐渐下降。而且更深的网络层数会导致模型参数量过大的问题。使用ResNet-50作为编码器的模型参数量达到82.3 M,是使用ResNet-34作为编码器参数量25.3 M的3倍多,因此选择ResNet-34作为模型编码器。
表4展示了ResNet-34是否进行预训练对模型产生的影响,加粗数据表示最优结果。可以得出采用预训练编码模型可以显著地提高模型分割准确度。
表4 是否使用预训练对模型性能的影响Tab.4 The impact of using pre-training on model performance |
| 编码器ResNet-34 | IoU/% | Dice/% |
|---|---|---|
| 未预训练 | 71.4 | 80.4 |
| 预训练 | 75.5 | 83.9 |
注:加粗数据表示最优结果。 |
2.5 消融实验
本文提出的分割模型EE-DANet主要改进了3个模块,主干分支的多尺度特征融合模块MFFM、特征融合模块FFM与边缘分支的增强空间注意力ASA,为了验证本文模型各模块的有效性,在Dataset_instrument数据集上进行消融实验,实验结果如表5所示,加粗数据表示最优结果。
表5 Dataset_instrument数据集上不同模块的消融实验Tab.5 Ablation experiments on different modules on the Dataset_instrument |
| 模块 | IoU/% | Dice/% | ||
|---|---|---|---|---|
| MFFM | FFM | ASA | ||
| 72.3 | 81.6 | |||
| √ | √ | 74.0 | 83.0 | |
| √ | √ | 74.8 | 83.6 | |
| √ | √ | 73.9 | 82.7 | |
| √ | √ | √ | 75.5 | 83.9 |
注:加粗数据表示最优结果。 |
模型中不加入本文改进的3个模块,仅将预训练过的ResNet-34作为编码器,解码器使用两层卷积,正常融合不同层级特征作为基线模型,得到的分割结果IoU和Dice分别为72.3%与81.6%。而将3个模块均加入模型则IoU和Dice可以比基线模型分别提升3.2%和2.3%,达到75.5%与83.9%。加入MFFM可以有效增强模型对不同尺度手术器械的分割效果,加入FFM可以增强模型对条状手术器械的捕获,也可以应对镜面反射问题,加入ASA可以增加模型对手术器械边缘特征的提取,提高模型分割性能。
本文模型中去掉某个模块,模型性能都有一定下降,表明本文提出的3个改进模块均是有效的。下降幅度最大的是在去除MFFM后,IoU和Dice比本文模型分别下降了1.6%和1.2%。去掉不同模块造成模型性能不同程度的下降也可以得出不同模块对模型的重要程度。从表5可以得出,白内障手术器械分割任务更加注重模型的多尺度特征提取能力和边缘特征提取能力,因为白内障手术器械数据集中手术器械影像尺度变换较大,且有诸多细小的手术器械。由于白内障手术器械数据集的特殊性,在特征融合阶段加入条形坐标注意力SCA和可形变卷积模块克服镜面反射问题也可以使得IoU和Dice提升0.7%与0.3%。
为验证增强空间注意力ASA在边缘特征融合中的有效性,通过探索边缘分支不同特征融合方式,进行消融实验,实验结果如表6所示,加粗数据表示最优结果。
表6 Dataset_instrument数据集上边缘分支特征融合方式的消融实验Tab.6 Ablation experiment of edge branch feature fusion on Dataset_instrument |
| 融合方式 | IoU/% | Dice/% |
|---|---|---|
| 直接融合 | 74.0 | 83.0 |
| 73.4 | 82.9 | |
| ASA | 75.5 | 83.9 |
注:加粗数据表示最优结果。 |
表6结果所示,将不同层次的边缘特征直接融合比不加入边缘分支的模型,分割性能非但没有提高甚至有所损害。图像的浅层特征虽然含有大量的边缘信息,但同时含有大量无用的背景信息。将包含大量无用信息的浅层特征与深层特征直接融合,会对模型提取的深层特征造成干扰,降低模型性能。采用增强空间注意力ASA,使具有较多语义信息的深层特征指导具有较多边缘信息的浅层特征,既能够包含较多边缘信息,又能抑制背景信息,因此模型性能会进一步提升。使用增强空间注意力模块比直接融合IoU与Dice分别提高了2.1 %与1.0 %,验证增强空间注意力ASA的有效性。
特征融合模块FFM主要由SCA模块与可形变卷积的双分支构成。为了验证FFM模块中条形坐标注意力SCA模块与对输入特征不同方向池化后进行扩展、拼接获得注意力权重方法的有效性,本文设计了如下消融实验,实验结果如表7所示。
表7 Dataset_instrument数据集上FFM模块的消融实验Tab.7 Ablation experiment of FFM module on Dataset_instrument |
| FFM模块 | 评价指标 | ||||||
|---|---|---|---|---|---|---|---|
| SCA模块 | 可形变卷积 | IoU/% | Dice/% | ||||
| 扩展 | 拼接 | ||||||
| √ | 73.9 | 82.7 | |||||
| √ | √ | 74.0 | 82.8 | ||||
| √ | √ | 74.8 | 83.5 | ||||
| √ | √ | √ | 75.5 | 83.9 | |||
注:加粗数据表示最优结果。 |
消融实验中,将FFM模块中的SCA模块替换成普通卷积,模型的IoU与Dice分别下降了1.6%与1.2%。与全局平均池化相比,条形池化的关注范围更为狭长,并非整个特征图,避免了与距离较远的位置建立不必要的连接,从而提高条形物体的识别能力。将该分支中的特征进行不同方向的条形池化后得到的特征分别进行扩展操作或拼接操作得到注意力权重,并对输入特征进行重新赋值,模型分割效果均得到小幅提升。验证了对特征进行不同方向池化后进行扩展与拼接获得注意力权重方法的有效性,也验证了SCA模块的有效性。
多尺度特征融合模块MFFM不同位置与数量会导致模型分割精度存在差异。为了验证MFFM不同位置与数量对模型分割精度的影响,在不同位置添加不同数量的多尺度模块。实验结果如表8所示,加粗数据表示最优结果。
表8 Dataset_instrument数据集上MFFM数目的消融实验Tab.8 Ablation experiment of the number of MFFM on Dataset_instrument |
| MFFM数量/个 | IoU/% | Dice/% |
|---|---|---|
| 0 | 73.9 | 82.7 |
| 1 | 75.5 | 83.9 |
| 4 | 75.1 | 83.7 |
注:加粗数据表示最优结果。 |
其中,数量为0表示本文模型不采用MFFM模块;数量为1即在编解码器过渡阶段采用1个MFFM模块;数量为4指在每个解码层前都采用MFFM提取多尺度特征。表8结果表明多尺度特征融合能力对提升模型分割效果是必要的,但是数量较多的MFFM并不能比单独的MFFM提升模型更多的精度。MFFM个数对模型性能并没有太大影响,而单个MFFM比4个MFFM可以减少不必要的参数。
多尺度特征融合模块可以捕获图像的多尺度特征,在分割模型中有重要作用。为了进一步探索不同大小的卷积核对多尺度模块性能的影响,设计了如下实验,实验结果如表9所示,其中加粗数据表示最优结果。实验结果表明,虽然卷积核越大,感受野越大,但是感受野过大会导致图像细节的丢失。在白内障手术器械分割任务中,一些手术器械尺寸较小,所以采用5×5、7×7、9×9这样3组卷积,在提取图像丰富多尺度特征时,不丢失过多图像细节,验证了该模块的有效性。
表9 Dataset_instrument数据集上MFFM不同卷积核数目的消融实验Tab.9 Ablation experiment of different number of convolution nuclei of MFFM on Dataset_instrument |
| 卷积核大小 | IoU/% | Dice/% |
|---|---|---|
| 3×3、5×5、7×7 | 75.1 | 83.7 |
| 5×5、7×7、9×9 | 75.5 | 83.9 |
| 7×7、9×9、11×11 | 74.1 | 82.9 |
注:加粗数据表示最优结果。 |
2.6 部分图像分割结果可视化

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
从图10中可以直观地看出,本文分割模型EE-DANet对图像的边缘部分处理比其他先进网络更为先进,并且在对条形物体分割时有明显的优势。对于镜面反射严重和与周围组织对比度低的手术器械,传统的分割网络总是将其误分类为背景,而本文模型仍然具有不俗的分割能力,可以很好适应由于光照条件不同,手术器械呈现的不同视觉特征。
3 结论
为了解决白内障手术器械分割中,手术器械的镜面反射问题与传统图像分割边缘信息丢失问题,本文提出了一种增强边缘特征的双注意力网络EE-DANet。主干分支通过多尺度特征融合模块与条形坐标注意力进行特征融合,提高模型对不同形状物体尤其是条状物体的特征提取能力;边缘分支使用增强空间注意力模块提取图像边缘特征,提高模型对边缘信息的恢复能力。所提出的方法分别在Dataset_instrument、Kvasir-instrument两个不同数据集进行验证,在两个数据集上均取得了更高的分割精度,与其他先进方法相比,所提方法有良好的分割性能和泛化能力,并且通过消融实验证明了我们提出模块综合使用的有效性。
在白内障手术器械分割的研究中,部分透明手术器械与周围眼部环境的视觉特征极其相似。对于Dataset_instrument数据集中的透明手术器械,模型的分割准确率不够理想。在进一步的工作中,将针对性地收集更多类似情况的手术器械数据集,探索如何在分割物与背景相似的环境下,进一步提升模型的分割精度。