

聚类是发现一个数据集样本原始分布的过程,基于“物以类聚,人以群分”的原理,聚类将相似样本聚集到同一类簇,不相似样本分布在不同类簇,从而发现隐藏在数据中的模式与规律。聚类分析已广泛应用于模式识别、遥感分析、图像处理、市场研究等领域[1]。
聚类是无监督学习,根据学习算法自动发现数据的分布模式,确定无标签数据的标记[2]。现有聚类算法可以划分为:划分式聚类[3]、层次聚类[4]、密度聚类[5⇓-7]、网格聚类[8]和模糊聚类[9]。最常见的是划分式聚类和基于密度的聚类。K-means[10]是经典的划分式聚类算法,该算法简单高效,但严重依赖于初始参数,无法发现非凸形状的类簇,且对噪声和离群点十分敏感。为此,出现了全局K-means[11]及其改进算法[12]。基于密度的经典聚类算法DBSCAN(density based spatial clustering of applications with noise)[13]能发现任意形状的类簇,对噪声不敏感,但其参数难以确定[5]。
具有里程碑意义的密度峰值聚类算法DPC(clustering by fast search and find of density peaks)[14]通过定义样本局部密度和距离,将所有样本散列在以密度为横坐标、距离为纵坐标的二维空间(决策图),决策图右上角区域的样本同时具有较高局部密度和距离,且远离其他样本,构成密度峰值点,即数据集类簇中心;其余样本分配至与其距离最近的高密度样本所在类簇,得到数据集样本分布模式。DPC算法能够发现任意维度和形状的簇,但该算法定义样本局部密度时,需要人为给定截断距离,样本局部密度依赖于截断距离。当数据集中同时包含稠密簇和稀疏簇时,DPC可能无法发现稀疏簇的类簇中心,从而影响聚类结果。另外,DPC算法的一步分配策略,带来算法高效率的同时,也带来了“多米诺骨牌效应”,一旦一个样本分配错误,将引起一系列样本的错误分配。还有DPC算法的类簇中心选取需要借助决策图手动完成,具有较强主观性[15⇓⇓-18]。为此,KNN-DPC(K-nearest neighbors optimized density peak clustering)[5]算法引入K近邻思想,重新定义了样本局部密度,并定义了离群点和非离群点,采用不同的分配策略分别对非离群点和离群点进行分配。FKNN-DPC(fuzzy weighted K-nearest neighbors density peak clustering)算法[6]提出了模糊加权K近邻,进一步改进了KNN-DPC的分配策略,采用模糊隶属度来判断样本所属类簇。ADPC(accelerating density peak clustering)算法[19]通过在聚类初始阶段识别非密度峰值样本来避免计算非密度峰值的相对距离,提高了DPC算法的运行速度。但ADPC算法在聚类效果方面没有显著提高。BC-DPC(density peaks clustering based on balance density and connectivity)[20]针对样本密度分布不均匀问题,提出了基于平衡密度和连通性的密度峰值聚类思想,消除数据集中各类簇中心的密度差异,从而正确选择出复杂数据集的类簇中心,且与其他同类算法相比具有更低的复杂度,提高了DPC算法的效率。RKNN-DPC(density peaks clustering algorithm based on representative points and K-nearest neighbors)算法[21]引入代表点刻画样本全局分布,提出了新的局部密度定义,并利用样本的K近邻信息提出一种加权的K近邻分配策略,解决类簇中心的密度差异,同时缓解“多米诺骨牌效应”。带有连通性估计的密度峰值聚类算法DPC-CE(density peak clustering with connectivity estimation)[22]采用同时考虑欧氏距离和连通性信息的距离惩罚来评估类簇中心间的相似性,避免了非球形和非均匀密度类簇对算法聚类性能的挑战,但该算法时间复杂度较高,不适用于较大规模数据集。SFKNN-DPC[23]针对DPC算法及其改进算法使用欧氏距离,忽略了不同特征对样本相似度的不同贡献,从而影响聚类结果,提出标准差加权距离,通过考虑每个特征的标准差对样本相似度的具体贡献来增强欧氏距离。在此加权距离基础上,定义样本局部密度和距离,最大程度地捕获样本的局部模式,并定义异常点,提出分而治之的分配策略,充分利用提出的加权距离、半监督学习和互近邻思想依次分配非离群点和离群点至最合适的类簇。基准数据集的大量实验表明,SFKNN-DPC优于DPC及其变体和其他基准聚类算法,且与同类算法相比具有统计意义上的显著性差异。
以上算法针对DPC算法存在的缺陷,从时间复杂度、局部密度计算等不同角度对DPC算法进行改进,但都没有考虑到标准差可以反映数据集样本的真实分布。为此,本文在以上研究的基础上,针对DPC算法样本局部密度定义的缺陷以及一步分配策略存在的缺陷,提出ESDTS-DPC(density peak clustering optimized by exponential function of standard deviation with two-step assignment strategy)算法。ESDTS-DPC算法借助标准差能很好地反映样本周围的样本分布密集程度这一内在本质,提出基于局部标准差的样本局部密度定义,通过构造一种能够反映样本真实分布的密度度量方法,发现数据集的类簇中心,以期能同时发现数据集的稠密簇和稀疏簇的类簇中心,并基于“分而治之”的思想提出两步分配策略,以期克服DPC算法的“多米诺骨牌效应”。大量实验验证了提出的ESDTS-DPC算法在复杂数据集情况下,可以得到更好的聚类结果。
1 DPC算法简介
DPC算法基于假设:类簇中心的局部密度高于其周围样本的局部密度,各类簇中心之间相距较远。因此DPC采用式(1)定义了样本i的局部密度ρi,用式(2)定义了样本i的局部距离δi。
ρi=|{j|dij<dc}|。
式中:|·|表示集合的模;dij为样本i和j之间的欧氏距离;dc为截断距离。因此,样本i的局部密度ρi等于以样本i为中心、以dc为半径的邻域内包含的样本数量。
δi=
由式(2)中局部距离定义可知,如果样本i具有最大密度,则其局部距离是它到所有样本距离的最大值;否则,其局部距离是到密度比它高的样本的最小距离。此定义保障了密度最大的样本一定是某类簇的中心。
DPC算法的重要贡献是提出了决策图思想,分别以样本的局部密度ρ和距离δ为x轴和y轴,将所有样本散列在该二维空间,使得密度较大且相互距离较远的样本分布在该二维空间的右上角区域,成为密度峰值点(类簇中心)。DPC算法的另一个重要贡献是它的一步分配策略,将类簇中心外的其余样本分配到距离最近且密度更高的样本所在类簇,快速获得数据集样本的分布模式。然而,DPC算法的样本局部密度定义中的截断距离dc是主观给定的,会导致稀疏簇的类簇中心具有相对较小的局部密度,以至于在决策图中无法选择到稀疏簇的类簇中心。另外,DPC算法的一步分配策略虽然高效,但一个样本分配错误,会引起后续若干样本的错误分配,导致“多米诺骨牌效应”。
2 ESDTS-DPC算法
2.1 算法思想
为了使样本局部密度准确反映数据集样本的真实分布情况,使稀疏区域的类簇中心和稠密区域的类簇中心同时被发现,借助样本局部标准差能体现该样本周围样本的分布情况,以及负指数函数当自变量大于0时,函数值随自变量增大而减小的本质。本文用式(3)定义样本的局部密度,使标准差越大的样本局部密度越小,标准差越小的样本局部密度越大,从而尽可能真实地体现数据集样本的分布情况,一定程度上克服DPC算法的局部密度定义缺陷。式(3)中的Ki表示样本i的K近邻构成的集合,dij是样本i、j间的欧氏距离。样本i局部距离δi的定义与DPC算法相同。在此基础上,采用和DPC算法相同的方式构造决策图,选择决策图右上角区域中同时具有较高局部密度和距离、远离其他样本的密度峰值样本作为数据集的类簇中心,
ρi=exp 。
在样本分配时,借助分而治之思想,先分配容易分配的样本,再借助已分配样本的启发信息,分配难分配的样本,从而保障最大概率地获得正确的聚类结果。因此,提出两步分配策略,尽可能正确地分配所有样本到正确类簇。为此,定义离群点和非离群点,将非离群点样本先分配,借助半监督思想,利用已分配的非离群点的类簇信息指导离群点样本的分配,保障所有非类簇中心样本都能分配到最合适的类簇,发现数据集样本的原始分布。离群点定义见式(4),表示当样本i到其K最近邻的最大距离大于所有样本到各自K最近邻的最大距离的平均时,则样本i为离群点。这里的所有样本到其K最近邻的最大距离均值为阈值,Ks是样本s的K个最近邻构成的集合,dst是样本s、t间的欧氏距离,n是数据集样本数,dij是样本i、j间的欧氏距离,Ki是样本i的K最近邻构成的集合。非离群点样本就是所有样本除去类簇中心和离群点后的剩余样本。
O= 。
2.2 TWO-STEP分配策略
ESDTS-DPC算法采用分而治之思想,提出两步分配策略,分别分配非离群点和离群点样本到最合适的类簇。分配离群点时,采用半监督思想,利用已分配的非离群点样本的类簇信息,指导离群点样本的分配,以便尽可能地使所有非类簇中心样本都能分到最合适的簇,从而发现数据集样本的原始分布。对非离群点采用算法1进行分配,对离群点采用算法2进行分配。如果算法1分配后,非离群点还有样本未被分配,则也按照算法2进行分配。


算法2假设了K互近邻并采用半监督思想,利用式(5)的模糊加权K最近邻定义样本i对类簇c的隶属度 。
= γij×sij。
式中:sij= 表示样本i、j间的相似程度;γij= 为权重,表示样本i、j相似程度占样本j与其K最近邻相似度和的比率;yj=c表示样本j已经被算法1分配到类簇c。
当算法2将样本i的K最近邻样本j分配到类簇c后,则样本i对类簇c的隶属度 依据式(6)进行更新。这里假设了样本i、j互为K最近邻。离群点的具体分配策略如算法2描述。
= +γij×sij。
2.3 ESDTS-DPC算法详细步骤
ESDTS-DPC算法详细步骤描述如下,算法的第7)步确保了该算法一定是收敛的。

2.4 算法时间性能分析
对于样本规模为n的数据集,DPC算法中时间复杂度由三部分组成:a)计算样本间距离;b)计算样本局部密度ρi;c)计算样本局部距离δi。三部分的时间复杂度均为O(n2),所以DPC算法的时间复杂度为O(n2)。
ESDTS-DPC算法的时间复杂度由以下四部分决定:a)计算样本间距离;b)计算样本局部密度ρi;c)计算样本局部距离δi;d)分配剩余样本。四部分时间复杂度均不超过O(n2)。因此,ESDTS-DPC算法的时间复杂度为O(n2),与DPC算法的时间复杂度相同,但是其聚类性能远优于DPC及其改进算法。
3 实验结果与分析
首先,在人工数据集进行消融实验,验证本文提出的样本局部密度定义、TWO-STEP分配策略的有效性。为了验证提出的样本局部密度的有效性,将DPC采用本文定义的样本局部密度,其他不变,得到ESD-DPC算法。消融实验将比较DPC、ESD-DPC和ESDTS-DPC算法在人工数据集的聚类结果,分别验证本文的局部密度定义和分配策略的有效性。然后,在UCI数据集和基因数据集上比较本文ESDTS-DPC算法与其他对比算法的聚类结果。
IAM(U,V)= 。
式中:IM(U,V)表示U和V之间的互信息;E{IM(U,V)}表示U和V之间的期望互信息;H(U)和H(V)分别表示U和V的熵。
IAR= 。
式中:TP表示在U和V中均属于同一类簇的样本对数目;FN表示在U中属于同一类,在V中不属于同一类的样本对数目;FP表示在U中不属于同一类,在V中属于同一类的样本对数目;TN表示在U中不属于同一类,在V中也不属于同一类的样本对数目。
3.1 数据预处理
数据预处理包含对缺失数据的处理和对数据规范化。采用均值代替法来补全缺失数据,采用式(9)的最大最小化对数据进行标准化,消除不同量纲对实验结果的影响,并减少计算的时间复杂度。
← 。
式中:xij表示第i个样本的第j个特征的取值;max(x·j)和min(x·j)分别表示第j个特征在数据集所有样本的最大值和最小值。
3.2 人工数据集的消融实验
表1 人工数据集Tab.1 Synthetic datasets |
表2 dataset1生成参数描述Tab.2 The parameters for generating dataset1 |
| 参数 | 簇1 | 簇2 | 簇3 |
|---|---|---|---|
| mean | [3, 2] | [8, 2] | [6, 5.5] |
| covariance | |||
| No points | 300 | 300 | 50 |
表3 dataset2生成参数描述Tab.3 The parameters for generating dataset2 |
| 参数 | 簇1 | 簇2 | 簇3 | 簇4 | 簇5 | 簇6 | 簇7 | 簇8 |
|---|---|---|---|---|---|---|---|---|
| mean | [1, 8] | [1, 3] | [3, 6] | [8, 10] | [9, 2] | [13, 6] | [16, 1] | [16, 12] |
| covariance | ||||||||
| No points | 2 000 | 2 000 | 2 000 | 100 | 100 | 100 | 2 000 | 2 000 |
表4 dataset3生成参数描述Tab.4 The parameters for generating dataset3 |
| 参数 | 簇1 | 簇2 | 簇3 | 簇4 |
|---|---|---|---|---|
| mean | [2,2] | [9,2] | [6,5.5] | [0.5,12.5] |
| covariance | [8,9.5] | |||
| No points | 8 000 | 3 000 | 3 999 | 5 001 |

图1 Pathbased1数据集的消融实验结果注:网络版为彩图。 Fig.1 Ablation experiment results on Pathbased1 dataset |

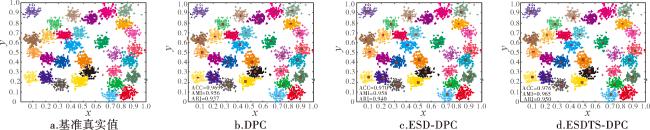
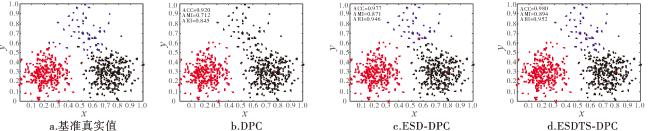
图4 dataset1数据集的消融实验结果注:网络版为彩图。 Fig.4 Ablation experiment results on dataset1 dataset |
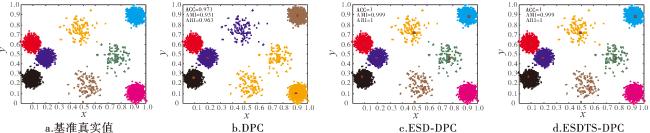
图5 dataset2数据集的消融实验结果注:网络版为彩图。 Fig.5 Ablation experiment results on dataset2 dataset |
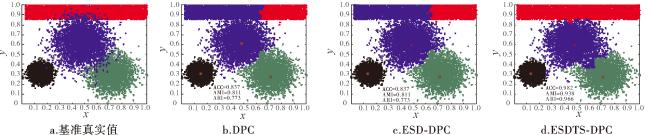
图1在Pathbased1数据集的消融实验结果显示,提出的ESDTS-DPC算法对Pathbased1的聚类结果最接近该数据集的真实分布;ESD-DPC和DPC算法尽管都发现了正确的类簇中心,但发现的类簇中心不同,且这两个算法均未能发现Pathbased1数据集样本的正确分布,然而ESD-DPC的聚类结果在ACC、AMI和ARI指标上明显优于DPC。上述结果说明提出的密度定义是有效的,分配策略更进一步提升了算法的聚类效果。
图2所示的Flame数据集的消融实验结果显示,ESDTS-DPC算法能发现Flame数据集的样本正确分布,在Flame数据集聚类准确率ACC、调整互信息AMI和调整Rand指标ARI均为1。ESD-DPC和DPC算法都不能发现Flame数据集的样本正确分布。尽管如此,但ESD-DPC在聚类指标ACC、AMI和ARI上的结果明显好于DPC。这说明本文提出的样本密度定义是有效的,TWO-STEP分配策略使算法的聚类性能进一步提升。
图3所示的在包含31个簇且各簇间存在样本重叠的数据集d31的消融实验结果显示,每个算法都能够发现d31数据集的正确类簇数和类簇中心。其中ESDTS-DPC算法的性能最优,其次是ESD-DPC,且该两个算法在ACC、AMI和ARI指标上均优于DPC算法。这说明本文提出的密度定义提升了DPC的性能,样本分配策略更进一步提升了ESD-DPC算法的性能。
图4在dataset1数据集的消融实验结果显示,DPC算法未能发现稀疏簇的类簇中心,从而无法发现数据集样本的正确类簇数和类簇分布,将类簇3和类簇2误识为同一个类簇。ESD-DPC和提出的ESDTS-DPC算法均可以发现数据集的正确类簇数和类簇中心。ESDTS-DPC算法的聚类结果最优,明显好于DPC和ESD-DPC算法的聚类结果。DPC算法因为无法发现稀疏簇的类簇中心,聚类结果最差。ESD-DPC算法由于改进了样本密度定义,各项聚类指标优于DPC算法。该数据集的消融实验再次说明,本文提出的样本密度定义和分配策略分别依次提升了DPC算法的性能。
图5对同时包含3个稀疏簇和5个稠密簇的8个类簇的dataset2数据集进行消融实验的结果显示,DPC算法不能正确检测出3个稀疏簇的类簇中心,致使3个稀疏簇被分别识别为近邻的稠密簇。而ESDTS-DPC和ESD-DPC算法不仅可以同时发现稀疏簇和稠密簇的类簇中心,且在dataset2上得到了相同的聚类结果,且明显优于DPC算法的结果。这进一步说明本文提出的样本密度定义和分配策略提高了DPC算法的性能。
图6是包含4个类簇且类簇样本有重叠的不平衡数据集dataset3,DPC算法发现了正确的类簇中心,但与ESD-DPC和ESDTS-DPC算法发现的类簇中心不同。尽管ESD-DPC与DPC发现的类簇中心不同,但他们的聚类结果相同,且均将长条形的类簇4划分为两个类簇。提出的ESDTS-DPC算法的聚类结果最接近数据集的真实分布,但对簇间重叠样本的分配依然有误。ESDTS-DPC算法在ACC、AMI和ARI指标上的结果远优于ESD-DPC和DPC算法。该数据集的聚类结果说明,聚类结果不仅与样本密度有关,很大程度上更依赖于样本的分配策略。
以上对各人工数据集的消融实验结果分析表明,本文提出的样本局部密度定义改进了DPC算法的性能,提出的TWO-STEP分配策略进一步改进了ESD-DPC算法的性能。因此,针对DPC算法的密度定义缺陷和分配策略缺陷提出的新密度定义和TWO-STEP分配策略非常有效,ESDTS-DPC对DPC的两处改进在不同程度上分别改进了DPC算法的聚类性能。
3.3 UCI真实数据集的实验
为了进一步验证本文提出的ESDTS-DPC算法的有效性,从UCI机器学习数据库中选取10个具有代表性的数据进行实验测试。各数据集具体信息描述如表5所示。
表5 UCI机器学习数据库的真实数据集信息描述Tab.5 Descriptions of the real-world datasets from UCI machine learning repository |
ESDTS-DPC、ESD-DPC、DPC-CE、FKNN-DPC、KNN-DPC、DPC和DBSCAN算法在10个UCI真实数据集的聚类结果见表6。其中,F/P分别表示发现的类簇数和其所在的真实类簇数,Par表示实验参数,均为各算法在相应数据集的聚类结果达到最优时的对应参数。
表6 各算法在UCI真实世界数据集的聚类结果Tab.6 The clustering results of each algorithm on real-world datasets from UCI machine learning repository |
| 算法 | 数据集 | ACC | AMI | ARI | F/P | Par | 数据集 | ACC | AMI | ARI | F/P | Par |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ESDTS-DPC | Iris | 0.973 | 0.912 | 0.922 | 3/3 | 7 | Wine | 0.949 | 0.831 | 0.846 | 3/3 | 6 |
| ESD-DPC | 0.960 | 0.861 | 0.886 | 3/3 | 2 | 0.905 | 0.740 | 0.727 | 3/3 | 18 | ||
| DPC-CE | 0.853 | 0.728 | 0.663 | 3/3 | 2 | 0.612 | 0.322 | 0.293 | 3/3 | 2 | ||
| FKNN-DPC | 0.973 | 0.912 | 0.922 | 3/3 | 7 | 0.949 | 0.831 | 0.852 | 3/3 | 7 | ||
| KNN-DPC | 0.973 | 0.912 | 0.922 | 3/3 | 7 | 0.948 | 0.829 | 0.844 | 3/3 | 7 | ||
| DPC | 0.887 | 0.767 | 0.720 | 3/3 | 2 | 0.882 | 0.706 | 0.672 | 3/3 | 2 | ||
| DBSCAN | 0.893 | 0.775 | 0.732 | - | 0.14/9 | 0.876 | 0.678 | 0.660 | - | 0.42/10 | ||
| ESDTS-DPC | WDBC | 0.924 | 0.615 | 0.718 | 2/2 | 5 | Libras | 0.483 | 0.508 | 0.326 | 12/10 | 10 |
| ESD-DPC | 0.914 | 0.730 | 0.766 | 2/2 | 3 | movement | 0.442 | 0.486 | 0.303 | 9/8 | 10 | |
| DPC-CE | 0.896 | 0.508 | 0.627 | 2/1 | 2 | 0.400 | 0.442 | 0.282 | 8/7 | 2 | ||
| FKNN-DPC | 0.944 | 0.679 | 0.786 | 2/2 | 7 | 0.436 | 0.508 | 0.308 | 13/9 | 9 | ||
| KNN-DPC | 0.943 | 0.675 | 0.783 | 2/2 | 7 | 0.453 | 0.523 | 0.331 | 13/9 | 9 | ||
| DPC | 0.613 | 0.009 | -0.011 | 2/1 | 9 | 0.361 | 0.390 | 0.214 | 9/7 | 0.5 | ||
| DBSCAN | 0.851 | 0.361 | 0.486 | - | 0.27/7 | 0.350 | 0.408 | 0.154 | - | 0.96/5 | ||
| ESDTS-DPC | Seeds | 0.929 | 0.756 | 0.799 | 3/3 | 5 | Segmentation | 0.686 | 0.621 | 0.506 | 7/6 | 6 |
| ESD-DPC | 0.914 | 0.730 | 0.766 | 3/3 | 3 | 0.686 | 0.621 | 0.530 | 6/6 | 9 | ||
| DPC-CE | 0.900 | 0.682 | 0.729 | 3/3 | 2 | 0.652 | 0.586 | 0.470 | 6/5 | 2 | ||
| FKNN-DPC | 0.924 | 0.759 | 0.790 | 3/3 | 8 | 0.716 | 0.655 | 0.555 | 6/5 | 7 | ||
| KNN-DPC | 0.923 | 0.758 | 0.788 | 3/3 | 8 | 0.717 | 0.632 | 0.539 | 6/5 | 7 | ||
| DPC | 0.900 | 0.717 | 0.734 | 3/3 | 2 | 0.684 | 0.651 | 0.550 | 6/5 | 3 | ||
| DBSCAN | 0.881 | 0.644 | 0.686 | - | 0.17/8 | 0.441 | 0.435 | 0.227 | - | 0.25/10 | ||
| ESDTS-DPC | Ionosphere | 0.752 | 0.284 | 0.355 | 3/2 | 8 | Waveform | 0.703 | 0.324 | 0.350 | 3/3 | 5 |
| ESD-DPC | 0.746 | 0.150 | 0.236 | 2/2 | 3 | 0.665 | 0.327 | 0.285 | 3/3 | 7 | ||
| DPC-CE | 0.678 | 0.164 | 0.186 | 3/2 | 2 | 0.515 | 0.365 | 0.280 | 3/3 | 2 | ||
| FKNN-DPC | 0.752 | 0.284 | 0.355 | 3/2 | 8 | 0.703 | 0.324 | 0.350 | 3/3 | 5 | ||
| KNN-DPC | 0.729 | 0.241 | 0.297 | 3/2 | 8 | 0.696 | 0.313 | 0.338 | 3/3 | 5 | ||
| DPC | 0.681 | 0.238 | 0.276 | 3/2 | 0.65 | 0.586 | 0.318 | 0.268 | 3/3 | 0.5 | ||
| DBSCAN | 0.607 | 0.086 | 0.036 | - | 0.2/7 | - | - | - | - | - | ||
| ESDTS-DPC | Waveform(noise) | 0.648 | 0.247 | 0.253 | 3/3 | 5 | Ecoli | 0.774 | 0.605 | 0.731 | 7/6 | 6 |
| ESD-DPC | 0.635 | 0.218 | 0.223 | 3/3 | 2 | 0.786 | 0.606 | 0.727 | 7/6 | 6 | ||
| DPC-CE | 0.545 | 0.197 | 0.157 | 3/3 | 2 | 0.810 | 0.639 | 0.752 | 6/5 | 2 | ||
| FKNN-DPC | 0.648 | 0.247 | 0.253 | 3/3 | 5 | 0.774 | 0.596 | 0.730 | 6/5 | 6 | ||
| KNN-DPC | 0.654 | 0.245 | 0.265 | 3/3 | 5 | 0.760 | 0.581 | 0.684 | 7/5 | 6 | ||
| DPC | 0.535 | 0.184 | 0.164 | 3/3 | 0.3 | 0.646 | 0.386 | 0.430 | 5/5 | 2 | ||
| DBSCAN | - | - | - | - | - | 0.560 | 0.392 | 0.473 | - | 0.1/3 |
从表6各算法在UCI数据集的聚类结果可以看出,在测试聚类算法的经典数据集Iris,所有算法均能找到该数据集的正确类簇中心,其中ESDTS-DPC和FKNN-DPC、KNN-DPC的聚类效果同时最优,接着是ESD-DPC、DBSCAN和DPC,DPC-CE的性能最差。
在Wine数据集,ESDTS-DPC在ACC和AMI上与FKNN-DPC相同,优于其他算法,FKNN-DPC算法在3个指标上均达到最优,KNN-DPC结果不如ESDTS-DPC算法,但优于ESD-DPC、DPC-CE、DPC和DBSCAN算法,ESD-DPC的聚类效果优于DPC,DPC-CE算法虽能找到正确的类簇中心,但与其他算法相比聚类结果最差。
在WDBC数据集,FKNN-DPC聚类效果最优,KNN-DPC次之,然后依次是ESDTS-DPC、ESD-DPC、DPC-CE和DBSCAN算法的聚类效果,DPC算法在WDBC数据集的聚类结果最差,原因是DPC在1个簇中检测出2个密度峰值。
在Libras movement数据集,ESDTS-DPC在聚类准确率ACC指标上达到了最优,KNN-DPC在AMI和ARI聚类指标的结果最好。Libras movement数据集较为复杂,对比的7个聚类算法没有一个能正确检测出该数据集的15个类簇中心,ESDTS-DPC从10个簇中检测出12个密度峰值,ESD-DPC从8个簇中检测出9个密度峰值,FKNN-DPC和KNN-DPC从9个簇中检测出13个密度峰值,DPC-CE从7个簇中检测出8个密度峰值,DPC从7个簇中检测出9个密度峰值。
在Seeds数据集,ESDTS-DPC在ACC和ARI上优于其他算法,FKNN-DPC在AMI上优于其他算法,KNN-DPC和ESD-DPC的聚类效果好于DPC,DPC在AMI和ARI上优于DPC-CE,DBSCAN的聚类结果最差。
在Segmentation数据集,KNN-DPC的ACC结果最好,FKNN-DPC在AMI和ARI上达到了最优。ESD-DPC和ESDTS-DPC结果都优于DPC和DPC-CE算法,DBSCAN算法的性能最差。ESDTS-DPC在6个簇中发现了7个密度峰值,DPC-CE、FKNN-DPC、KNN-DPC和DPC都在5个簇中检测出6个密度峰值。没有一个算法能正确检测到该数据集的全部7个类簇的类簇中心。
在Ionosphere数据集,聚类性能最优的是ESDTS-DPC和FKNN-DPC,其次是ESD-DPC和KNN-DPC,结果都好于DPC、DPC-CE和DBSCAN算法。除ESD-DPC外,ESDTS-DPC、DPC-CE、FKNN-DPC、KNN-DPC和DPC算法都在2个簇中检测出3个密度峰值。
Waveform和Waveform(noise)是两个较大的数据集,包含3个簇。Waveform(noise)数据集包含19个噪声特征。由于DBSCAN算法的2个参数不容易调优,因此在Waveform和Waveform(noise)数据集没有DBSCAN算法的相关聚类结果。在Waveform数据集,ESDTS-DPC和FKNN-DPC都在ACC和ARI指标取得最优结果,DPC-CE算法在AMI指标取得最优值,KNN-DPC的聚类结果总体优于ESD-DPC和DPC-CE,最差的是DPC算法的聚类结果。在Waveform(noise)数据集上,ESDTS-DPC和FKNN-DPC在AMI指标达到了最优,KNN-DPC在ACC和ARI指标取得最优值,ESD-DPC的聚类结果优于DPC-CE和DPC算法。
在Ecoli数据集,DPC-CE算法在所有指标上都优于其他算法,ESD-DPC算法在ACC和AMI指标上优于除DPC-CE外的其他算法,ESDTS-DPC在ARI上优于除DPC-CE外的其他算法。所有算法都未能发现Ecoli数据集的类簇数和全部类簇中心,ESDTS-DPC和ESD-DPC算法从6个簇中找到了7个密度峰值;DPC-CE和FKNN-DPC算法从5个簇中找到了6个密度峰值,KNN-DPC算法从5个簇中找到了7个密度峰值,但DPC算法能正确发现该数据集的5个类簇的中心,尽管其未能发现该数据集所有类簇的类簇中心。
以上实验结果分析表明,ESDTS-DPC和ESD-DPC算法的总体表现优于其他同类算法,更进一步验证了本文提出的样本密度定义和分配策略的有效性,有效改进了DPC算法的缺陷。
3.4 基因数据集实验
表7 基因数据集Tab.7 Gene datasets |
表8 各算法在基因数据集上的聚类结果Tab.8 The clustering results of each algorithm on Gene datasets |
| 算法 | 数据集 | ACC | AMI | ARI | F/P | Par | 数据集 | ACC | AMI | ARI | F/P | Par |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ESDTS-DPC | St.Jude | 0.980 | 0.944 | 0.958 | 6/6 | 8 | Leukemia | 1 | 1 | 1 | 3/3 | 6 |
| ESD-DPC | leukemia | 0.980 | 0.948 | 0.960 | 6/6 | 10 | 1 | 1 | 1 | 3/3 | 6 | |
| DPC-CE | 0.948 | 0.921 | 0.955 | 7/6 | 2 | 0.816 | 0.589 | 0.545 | 3/3 | 2 | ||
| FKNN-DPC | 0.980 | 0.944 | 0.958 | 6/6 | 8 | 1 | 1 | 1 | 3/3 | 6 | ||
| KNN-DPC | 0.990 | 0.966 | 0.979 | 6/6 | 8 | 1 | 1 | 1 | 3/3 | 6 | ||
| DPC | 0.919 | 0.866 | 0.879 | 5/5 | 2 | 1 | 1 | 1 | 3/3 | 2 | ||
| DBSCAN | 0.980 | 0.944 | 0.959 | - | 0.73/4 | 0.947 | 0.821 | 0.830 | - | 0.83/2 | ||
| ESDTS-DPC | Novartis | 0.99 | 0.969 | 0.973 | 4/4 | 9 | Lung cancer | 0.970 | 0.849 | 0.904 | 4/4 | 8 |
| ESD-DPC | 0.99 | 0.969 | 0.973 | 4/4 | 10 | 0.944 | 0.775 | 0.828 | 4/4 | 10 | ||
| DPC-CE | 0.544 | 0.444 | 0.335 | 5/3 | 2 | 0.919 | 0.670 | 0.750 | 4/4 | 2 | ||
| FKNN-DPC | 0.99 | 0.969 | 0.973 | 4/4 | 9 | 0.970 | 0.849 | 0.904 | 4/4 | 8 | ||
| KNN-DPC | 0.99 | 0.969 | 0.973 | 4/4 | 10 | 0.963 | 0.833 | 0.884 | 4/4 | 8 | ||
| DPC | 0.99 | 0.969 | 0.973 | 4/4 | 3 | 0.949 | 0.786 | 0.843 | 4/4 | 0.7 | ||
| DBSCAN | 0.99 | 0.969 | 0.973 | - | 0.65/3 | 0.883 | 0.619 | 0.665 | - | 0.33/5 | ||
| ESDTS-DPC | Normal tissues | 0.833 | 0.825 | 0.758 | 13/12 | 2 | CNS tumors | 0.857 | 0.727 | 0.700 | 5/5 | 2 |
| ESD-DPC | 0.844 | 0.852 | 0.787 | 13/12 | 2 | 0.881 | 0.791 | 0.739 | 5/5 | 2 | ||
| DPC-CE | 0.500 | 0.419 | 0.232 | 15/8 | 2 | 0.619 | 0.462 | 0.418 | 6/2 | 2 | ||
| FKNN-DPC | 0.833 | 0.825 | 0.758 | 13/12 | 2 | 0.857 | 0.727 | 0.700 | 5/5 | 2 | ||
| KNN-DPC | 0.844 | 0.852 | 0.787 | 13/12 | 2 | 0.857 | 0.727 | 0.700 | 5/5 | 2 | ||
| DPC | 0.844 | 0.852 | 0.787 | 13/12 | 2 | 0.547 | 0.395 | 0.341 | 3/3 | 2 | ||
| DBSCAN | 0.867 | 0.820 | 0.795 | - | 0.41/3 | 0.762 | 0.601 | 0.602 | - | 0.59/2 | ||
| ESDTS-DPC | Mouse lung | 1 | 1 | 1 | 2/2 | 6 | Multi-A | 0.961 | 0.899 | 0.898 | 4/4 | 11 |
| ESD-DPC | 1 | 1 | 1 | 2/2 | 4 | 0.971 | 0.917 | 0.920 | 4/4 | 8 | ||
| DPC-CE | 1 | 1 | 1 | 2/2 | 2 | 0.748 | 0.698 | 0.666 | 4/3 | 2 | ||
| FKNN-DPC | 0.917 | 0.629 | 0.665 | 2/2 | 3 | 0.951 | 0.870 | 0.874 | 4/4 | 4 | ||
| KNN-DPC | 1 | 1 | 1 | 2/2 | 3 | 0.950 | 0.867 | 0.869 | 4/4 | 4 | ||
| DPC | 1 | 1 | 1 | 2/2 | 2 | 0.903 | 0.825 | 0.778 | 4/4 | 2 | ||
| DBSCAN | 1 | 1 | 1 | - | 0.79/2 | 0.762 | 0.601 | 0.602 | - | 0.59/2 |
需要说明的是:对基因数据集St.Jude Leukemia、Leukemia、Novartis、CNS tumors和Mouse lung均采用式(11)的z-score进行标准化,对于Multi-A数据集采用log2进行标准化,式(10)计算样本间距离。对Normal tissues数据集不进行数据标准化,距离度量采用式(10)的余弦距离度量。对Lung cancer数据集采用式(9)的最小最大化预处理数据,距离度量采用式(10)的余弦距离。DPC-CE算法对所有基因数据集的距离度量均采用欧氏距离度量。
dij=1-cos(θ(xi,xj))=1- 。
式中:样本xi、xj间的夹角余弦cos(θ(xi,xj))取值范围为[-1,1],该值越大表示样本xi、xj间的夹角越小,该值越小,表示样本xi、xj之间的夹角越大;样本间的夹角越小表示他们越相似。所以,定义样本间的余弦距离为1-cos(θ(xi,xj)),其中,i,j=1,2,…,n,n是样本数。
z(xij)= 。
式中:xij表示第i个样本在第j个特征的取值; 表示第j个特征在所有样本的平均值;n表示样本总数。
表8各算法在各基因数据集的聚类结果表明,除Normal tissues数据集外,ESDTS-DPC可以正确地检测出其他每个基因数据集的类簇中心,并且聚类效果都较好。在St.Jude leukemia数据集,KNN-DPC的聚类准确率最好,ESDTS-DPC的聚类效果仅次于KNN-DPC,准确率达到98%。
在Leukemia数据集,除DPC-CE和DBSCAN外,其他各算法都能完全发现该数据集的原始分布。
在Novartis数据集,DPC-CE不能发现正确的类簇中心,聚类效果较差,其他算法的聚类准确率都达到了99%,且ESDTS-DPC、ESD-DPC、FKNN-DPC、KNN-DPC和DPC均能发现该数据集的真实类簇中心和类簇数。
在Lung cancer数据集,ESDTS-DPC和FKNN-DPC的聚类结果最优,远优于ESD-DPC、DPC-CE、KNN-DPC、DPC和DBSCAN算法,且各基于密度峰值聚类的算法也都能发现该数据集的正确类簇数和类簇中心。
在Normal tissues数据集,DPC的聚类结果略优于ESDTS-DPC,所有算法都不能发现该数据集的正确类簇中心,其中ESDTS-DPC、ESD-DPC、FKNN-DPC、KNN-DPC和DPC均从12个类簇中发现了13个类簇中心,DPC-CE算法从该数据集的8个类簇中发现了15个类簇中心,效果最差。
在CNS tumors数据集,ESD-DPC的聚类结果最优,且发现了数据集的正确类簇数和类簇中心,DPC-CE和DPC都未能发现该数据集的5个类簇中心,其中DPC从3个类簇中正确发现了3个类簇中心。而DPC-CE算法从2个类簇中发现了6个类簇中心,导致聚类效果最差。
在Mouse lung数据集,除FKNN-DPC外,其他所有算法都能发现该数据集的正确分布。
在Multi-A数据集,ESD-DPC聚类效果最优,然后依次是ESDTS-DPC、FKNN-DPC、KNN-DPC、DPC、DBSCAN和DPC-CE算法。ESDTS-DPC、FKNN-DPC、KNN-DPC和DPC算法均能发现该数据集的4个类簇中心和类簇数,聚类结果远优于DPC-CE。DPC-CE从该数据集的3个类簇中发现了4个类簇中心,聚类效果最差。
综上基因数据集的聚类结果分析可见,尽管ESDTS-DPC和ESD-DPC算法在多数基因数据集的聚类结果优于DPC,但在部分数据集上,DPC的聚类结果优于或等于ESDTS-DPC或ESD-DPC。这表明,提出的样本局部密度定义方式和样本分配策略确实改进了DPC算法,但原始DPC算法在某些特殊情况下仍然表现良好。
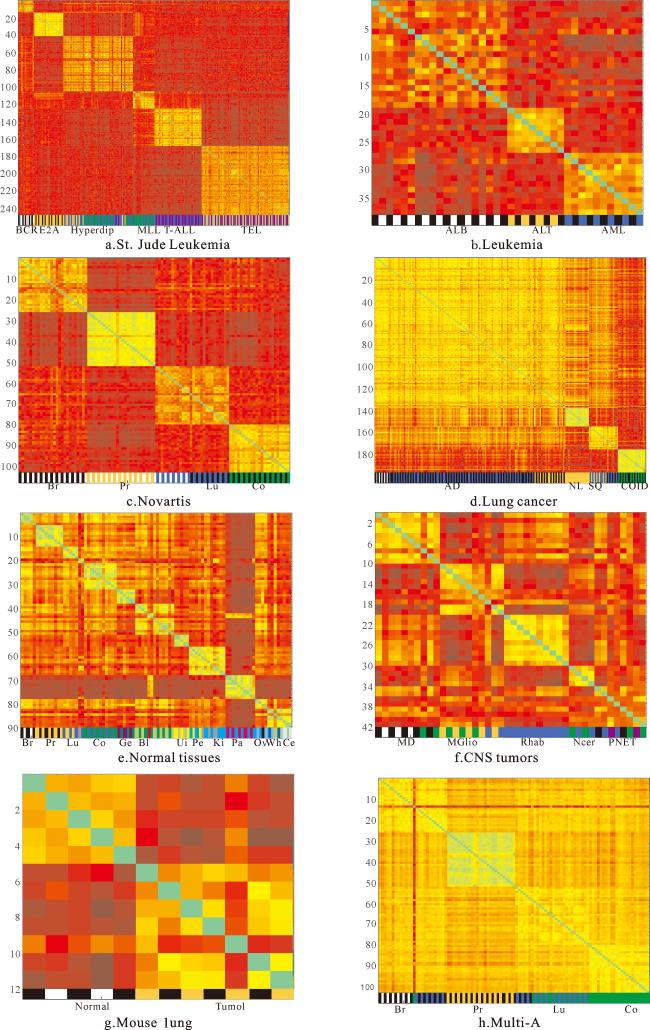
从图7展示的本文ESDTS-DPC算法在8个基因数据集的聚类结果可以看到,ESDTS-DPC算法在Leukemia数据集和Mouse Lung数据集都可以做到没有任何误差地发现数据集的原始分布,说明该方法能够正确检测不同类型的白血病细胞以及小鼠的肿瘤肺和正常肺。
对Novartis数据集,ESDTS-DPC可以检测不同的癌症,包括乳腺癌(breast,Br)、前列腺癌(prostate,Pr)、肺癌(lung,Lu)和结肠癌(colon,Co),但它将一个肺癌(Lu)样本误识别为乳腺癌(Br)样本。
对Multi-A数据集,除了将2个乳腺癌(Br)样本分别错误地识别成肺癌(Lu)和结肠癌(Co)以及将2个肺癌(Lu)样本错误识别为乳腺癌(Br)样本外,ESDTS-DPC能正确识别其他样本。
对St.Jude Leukemia数据集,ESDTS-DPC将5个Hyperdip样本错分到了其他簇中,其中3个Hyperdip样本识别为混合系白血病(mixed lineage leukemia,MLL)样本,1个Hyperdip样本识别为急性T淋巴细胞白血病(T-cell acute lymphoblastic leukemia,T-ALL)样本,1个Hyperdip样本识别为E2A样本,但对Hyperdip簇以外的其他样本均能正确识别。
对CNS tumors数据集,ESDTS-DPC算法将6个样本错误地分组到其他簇中,其中1个髓母细胞瘤(medulloblastomas,MD)样本和1个原始神经外胚层肿瘤(primitive neuroectodermal tumors,PNET)样本被检测为正常小脑(normal cerebellum,Ncer)样本,1个恶性胶质瘤(malignant gliomas,MGlio)样本被检测为横纹肌肿瘤(rhabdoid tumors,Rhab)样本,2个正常小脑(Ncer)样本和1个原始神经外胚层肿瘤(PNET)样本被检测为髓母细胞瘤(MD)样本。
对Lung cancer数据集,ESDTS-DPC将6个样本错误地划分为其他类簇,其中将4个腺癌(adenocarcinomas,AD)样本检测成鳞状细胞癌(Squamous cell carcinomas,SQ)样本,1个腺癌(AD)样本检测为正常肺(normal lung,NL)样本,1个鳞状细胞癌(SQ)样本检测为腺癌(AD)样本,但ESDTS-DPC能够正确地检测出正常肺(NL)样本和类癌(carcinoids,COID)样本。
对包含13种不同组织类型的90个样本和每个样本1 277个特征的Normal-tissues数据集,ESDTS-DPC算法的聚类结果存在较多错误,仅正确检测出乳腺癌(Br)、前列腺癌(Pr)、结肠癌(Co)、生发中心细胞癌(germinal center cells,Ge)、子宫癌(uterus,Ut)、胰腺癌(pancreas,Pa)和小脑癌(cerebellum,Ce)7个类簇,其他类簇包括肺癌(Lu)、膀胱癌(bladder,Bl)、外周血单核细胞癌(pe-ripheral blood monocytes,Pe)、肾癌(kidney,Ki)、卵巢癌(ovary,Ov)和全脑癌(whole brain,Wh)均未能正确检测识别。
3.5 算法的统计性检验
对实验比较的7种聚类算法ESDTS-DPC、ESD-DPC、DPC-CE、FKNN-DPC、KNN-DPC、DPC和DBSCAN进行统计重要性检验,以验证提出的ESDTS-DPC算法与其他6个对比算法相比,是否更具有统计意义的重要性,即提出的ESDTS-DPC与对比算法是否具有统计意义上的显著不同。首先采用Friedman’s检验来检测这7种算法之间是否存在显著性差异,一旦Friedman’s检验检测出各算法之间有显著性差异,则继续使用Nemenyi’s检验作为事后检验,来检测各算法两两之间是否存在统计意义上的显著差异。
基于各算法在人工数据集、UCI数据集以及基因数据集上的ACC、AMI和ARI聚类结果,在α=0.05的统计重要度水平进行Friedman’s检验,检验结果如下:对于ACC,χ2=64.47,df=6,p=1.648 84×10-13;对于AMI,χ2=61.7,df=6,p=2.029 73×10-11;对于ARI,χ2=64.7,df=6,p=5.546 51×10-12。各算法的ACC、AMI和ARI的Friedman’s检验的p值都远小于α,因此,可以得出这7种聚类算法之间存在显著性差异。因此,我们进一步进行Nemenyi’s检验来检测各算法两两之间是否存在显著性差异。
如果两种算法的平均秩差小于阈值CD,则在1-α的置信水平下接受“两种算法之间没有显著差异”的零假设;否则就拒绝零假设,接受“两种算法之间存在显著性差异”的非零假设。阈值CD的计算方式如式(12)所示,式中:M为参与对比的算法数量;N为数据集数量;qα为Tukey分布的阈值。
CD=qa 。
本文的Nemenyi’s检验中,M=7,N=23,qα=q0.05=2.948,通过式(12)计算得到CD=1.877 9。在置信度为0.95时,Neimenyi’s检验的结果如图8所示。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
以上在人工数据集、UCI数据集和基因数据集实验结果的统计检验表明,ESDTS-DPC算法优于ESD-DPC、DPC-CE、FKNN-DPC、KNN-DPC、DPC和DBSCAN算法,且与DPC、DPC-CE和DBSCAN算法具有统计意义上的显著不同。这表明本文提出的基于标准差的样本局部密度定义,以及TWO-STEP分配策略都是非常有效的,显著改善了DPC算法的性能。
4 结论
提出了基于K最近邻样本局部标准差的样本局部密度,以及TWO-STEP分配策略,得到一种新的密度峰值聚类算法ESDTS-DPC。ESDTS-DPC算法充分利用了局部标准差能反映周围样本分布密集程度的本质,定义样本局部密度,尽可能地反映数据集样本的真实分布状态;并充分利用了分而治之和半监督学习思想,先分配不易出错的样本,再分配易出错的样本,确保尽可能正确地分配每一个样本到最合适的类簇,发现数据集中隐藏的模式。
人工数据集的消融实验、UCI真实数据集和基因数据集与同类算法的对比实验均表明,本文ESDTS-DPC算法的样本局部密度定义和样本分配策略分别克服了DPC算法的样本局部密度定义缺陷和样本一步分配策略带来的“多米诺骨牌效应”,提升了DPC算法的聚类性能。统计重要性检验进一步证实了提出的ESDTS-DPC算法明显优于同类算法。
但是,本文ESDTS-DPC算法的样本局部密度定义使用了样本的局部标准差,其中的参数K通过实验确定,还缺少理论指导。如何更合理地定义样本局部密度,还有待进一步研究。