

决策行为是人类在社会生活中最基本的思维和认知活动,任何复杂任务的完成都离不开科学决策。在金融、医疗等领域中,决策者面临的决策问题主要为对于风险的识别和确定,并据此做出对应的最优决策,从而降低风险和损失[1-2]。银行需要处理信贷申请,根据历史信息和申请者的个体信息判断其违约风险并决定是否同意贷款;医生需要结合患者检查的已知信息和关于病症的病例信息进行疾病诊断,确定患者是否患病和有健康风险。
信用风险评估的核心是分析企业或个人的历史信息建立模型,进而预测其未来违约状态。Orgler[3]采用线性回归模型评估个人的信用评分。Wiginton[4]在信用评分模型中引入逻辑回归模型用于消费者信用评分。陈耸等[5]提出新的基于半监督支持向量机的信用评分模型以解决有标记样本获取的问题。Dumitrescu等[6]通过结合非线性决策树以改进逻辑回归方法,从而取得较好的信用评价模型效果。Furkan等[1]结合机器学习方法提出一种基于聚类的模糊分类方法来进行信用风险评估。对于医疗诊断过程中的疾病风险预测,传统的就医流程不利于早期干预和预防。随着医学进步和信息技术的发展,许多学者针对患病风险的识别和判断进行相关研究。马孝斌等[7]通过优化决策树对慢性阻塞性肺疾病患者的肺功能检测指标数据进行建模,构建了疾病预测模型。江爱娟等[8]提出病证结合模式,构建由现代医学理化指标和中医证候学资料的核心指标体系以进行疾病风险预测。Yan等[9]利用冠心病患者的电子病历数据设计了基于机器学习的风险预测系统。Hoyos等[10]结合模糊认知映射开发三种联合学习方法,用于预测严重登革热的死亡率并制定治疗处方。面对海量数据和高维度特征的挑战,风险评级作为决策问题中的重要类别,在信用评级和疾病风险预测等实际应用场景中,专家主要根据领域知识进行主观判断,存在评级决策错误和风险预测不准确的局限,因此如何结合历史业务数据辅助专家决策近年来受到学者关注[11-12]。
随着利益相关者参与意识的提高和信息通信技术的发展,为了提高决策水平与效率并避免单个决策者造成的决策失误,多个决策主体参与并集结其评价信息的群体决策行为成为必要和可能。群体决策(group decision-making,GDM)旨在解决需要专家或决策者参与的非结构化决策问题,通过决策者间的协商形成一致性意见,最后确定的方案选择作为决策结果[13]。传统群体决策研究中,专家评价意见的一致性是研究核心,但近来有学者指出,决策者主要基于自身的经验认知做出主观评估,只考虑评价信息的一致性并不能保证决策质量[11,14]。随着群体决策的研究逐步深入,研究重点逐渐向三支群体决策、考虑社会网络和大规模参与的方向转变。三支决策可以有效应对决策过程中的不确定性和高风险[15-16],许多学者将三支决策引入群体决策以解决现代决策问题日趋增加的复杂性。Liang等[17]提出了新的考虑决策者和参与者组成的分层社交网络三支群体共识模型。Huang等[18]在不完全多尺度决策信息系统下,通过充分考虑决策过程中的损失和效用,开发了一个基于前景后悔理论的具有直觉模糊数的三支群体决策模型。Wang等[19]建立了一个具有排序和分类功能的模型,以解决基于三支决策的犹豫模糊多属性群体决策问题。对于社会网络的考虑,学者利用网络信息确定决策者属性特征并分析通过网络关系的信息交互行为。Wu等[20]基于社交网络下的信任关系,提出了一个两阶段信任网络划分模型以处理大规模决策。Wang等[21]将外部性效应引入调整机制,并设计了相应的优化模型来实现共识。Liu等[22]提出了一种基于信任关系的冲突检测和消除决策模型,用于解决社交网络环境中的大规模群体决策。在大规模群体参与的情况下,学者将风险决策与大规模群体决策结合进行研究,以适应更现实的情境[23]。Hu和Lin[24]针对执法过程中的财产隐匿风险,提出新的基于Z-范数的多准则群体决策方法。Liu等[25]提出了一种基于共识的失效模式和影响分析方法,探究该过程中风险因素的不完全权重信息对于决策过程的影响。
综上所述,现有对于风险评级问题的研究主要集中于利用机器学习的方法,通过真实数据结合专家的主观评估改进和提升评估准确性和模型效果。群体决策的研究开始关注决策质量的量化和评估,同时传统群体决策、三支决策和风险决策的结合可以有效迁移至风险评级背景,实现基于历史数据辅助专家决策,并为金融医疗等应用场景提供一定的实践意义,降低决策风险,丰富风险评级的研究。本文的主要贡献总结如下:1)通过引入数据驱动和三支决策的思想,基于真实历史数据利用K-means聚类分析建立专家评估发现规则,实现客观评估意见的获得;2)为了量化和评估决策质量,结合专家客观评估,在群体决策的框架下构建三支群体分类算法,并在UCI和Kaggle的信贷风险和疾病诊断数据集上验证算法效果。
1 预备知识和数据预处理
1.1 三支决策(TWD)理论
Yao[16]于2010年基于决策粗糙集理论提出三支决策方法(three-way decision,TWD),并证明这是一种处理决策过程中不确定性和高风险的有效方法。该方法的主要思想是将一个系统划分为三个不相交的区域:正域、边界域和负域,并分别对应于接受、推迟和拒绝三种行动。这一分类是基于分而治之的思想,体现为对三个相关的整体的理解、表示和处理[15-16]。随着TWD被广泛应用于GDM中,损失函数的形式表征专家评估意见的三支群体决策成为经典模型。基于贝叶斯决策理论框架,三支决策理论由{C,┐C}两个状态和{aP,aB,aN}三个动作组成。具体而言,对于备选项x,模型表述为它在C或┐C状态中,aP、aB、aN表示x被决策为属于的区域。因此,可以得到备选项在不同状态和不同行动的对应损失函数,如表1所示。λPP、λBP、λNP表示真实状态为C的对象采取aP、aB、aN动作的对应损失。类似地,λPN、λBN、λNN是真实状态为┐C的对象采取aP、aB、aN动作的对应损失,其中损失函数满足λPP≤λBP<λNP,λNN≤λBN<λPN的相互关系[11,17]。
表1 三支决策的损失函数矩阵Tab.1 Loss function matrix of three-way decision |
| 行动 | C(P) | ┐C(P) |
|---|---|---|
| aP | λPP | λPN |
| aB | λBP | λBN |
| aN | λNP | λNN |
进而,根据损失评估来计算采用不同行动的期望损失[11],公式如下:
R(aP|x)=λPPPr(C|x)+λPNPr(┐C|x),
R(aB|x)=λBPPr(C|x)+λBNPr(┐C|x),
R(aN|x)=λNPPr(C|x)+λNNPr(┐C|x),
式中Pr(C|x)和Pr(┐C|x)分别表示备选项属于C和┐C状态的概率。属于某一状态的概率可由专家评估意见计算得到,公式如下:
Pr(C|x)=[(λBP-λPP)+(λNP-λPP)/[(λBP-λPP)+(λNP-λPP)+(λBN-λNN)+(λPN-λNN)]。
最后基于上述确定的各行动的期望损失,利用三支决策计算三个区域决策的概率阈值[26],公式如下:
α= ,
β= ,
γ= 。
进而可以确定三支决策区域分类的决策规则(P1)~(N1):
(P1)如果Pr(C|x)≥α且Pr(C|x)≥γ,则x∈POS(C);
(B1)如果Pr(C|x)≤α且Pr(C|x)≥β,则x∈BND(C);
(N1)如果Pr(C|x)≤β且Pr(C|x)≤γ,则x∈NEG(C)。
1.2 K-means聚类算法
聚类分析是通过将给定的样本集合按照数据的相似性系数或距离等属性,划分归并为若干个“类”或“簇”的数据分析过程[27]。通过对样本数据集进行聚类,能够发现相关性高的样本点子集,从而挖掘数据内部潜在的结构关联。可以采用轮廓系数、簇内平方和CH指标衡量聚类效果的好坏,从而调整初始聚类点和模型参数。聚类分析作为一种无监督学习算法,常处理无标签信息的数据集。Macqueen[28]在1967年基于前人的研究成果提出了K-means聚类算法,并通过数学方法验证其想法的准确性,并归纳出实现K-means算法的详细步骤。该算法基于样本点与聚类中心的距离,将数据集划分成K个具有明显特征差异的类别。K-means聚类理论具有简单清晰、计算速度快、聚类效果明显等优点,被广泛使用于多个领域。因此,本文结合风险评级问题背景,采取K-means聚类算法对真实数据集进行处理,聚类结果作为后续专家评估意见的客观参照并进行群体意见优化。K-means聚类算法思想大致为:先从样本集中随机选取K个样本作为簇中心,并计算所有样本与这K个簇中心的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的簇中心[27-28]。
1.3 数据预处理与特征选择
信用数据和医疗数据的主要特征是对象个人信息变量类型的多样性和复杂性,网络上的金融和疾病诊断公开数据集为经过脱敏处理后的真实数据,能够用于本文实验。本文使用4个数据集,通过收集并梳理其数据特征,以用于后续研究。在4个数据集中,由于存在缺失值和异常值,首先进行数据清理,重点是检测和修复缺失的单元格和异常值。对于不完整的属性特征,如果缺失数据率大于95%,则删除该特征。对于类别型数据特征,采用类别编码的方法,依次编码为非负整数。数据集Bank fears loanliness原始数据量50余万条,计算耗时长,所以采用随机抽样的方法抽取其中3万条数据用以后续分析。同时,由于信用违约或确诊疾病的对象数量为观察样本中的少数,类别数据呈现不均衡分布,所以数据集中存在标签不平衡的问题,不利于后续分类器的建立和特征提取。本文采用过采样中的synthetic minority oversampling technique (SMOTE)方法对原数据集进行采样使得数据平衡[29]。然后,对于数据采取标准化,使得处理的数据符合标准正态分布,处理公式如下:
= 。
式中:μ是所有样本数据的均值;σ是所有样本数据的标准差。
表2 清洗后的数据集Tab.2 The cleaned datasets |
| 数据集 | 样本数量 | 特征数量 | 类比(分布) |
|---|---|---|---|
| Heart failure data | 406 | 4 | 2(203/203) |
| German credit data | 1 400 | 4 | 2(700/700) |
| Credit-card classification data | 16 852 | 5 | 2(8 426/8 426) |
| Bank fears loanliness data | 46 072 | 10 | 2(23 036/23 036) |
2 基于聚类分析的专家评估规则发现和三支分类算法
本节结合数据驱动的思想,可以将清洗后的数据集进行K-means聚类,得到聚类后的簇中心点和簇内样本点信息,通过将簇视为具备领域知识的决策者个体,并利用簇的信息确定决策者的评估意见和计算优化群体意见;进而对数据集进行机器学习,辅助支持群体意见以构建分类算法,实现三支风险评级。
2.1 基于聚类分析的专家评估发现规则
基于第1节的数据处理和表2结果可以发现,实验所使用的4个数据集均为有标签数据,进而本节采用预备知识中的K-means方法对数据进行聚类。相较于传统的无监督方法,本文考虑样本的标签作为分类目标,继而将聚类结果视为经过专家领域知识的评估经验来实现有监督学习。将数据集划分为训练集和测试集,首先对训练集的样本数据进行聚类分析。
K-means聚类建模的第一步便需要预设聚类的类别数目K,模型后续的一切计算都是基于K值展开的,这对聚类效果具有重要影响。取值可以凭借业务知识以及经验确定,为了克服K-means算法中聚类簇数K与聚类效果的依赖关系,采用轮廓系数、簇内平方和CH指标等评价指标确定初始聚类中心数量。同时结合聚类可视化的方法对不同聚类数量的聚类结果进行可视化,可以有效辅助确定K值,优化算法效果。由于使用的数据集存在高维性,需要采取降维方法将数据降至二维,以进行观察,降低特征维度、构造新的特征变量的同时尽量减少信息损失。常用的降维方法有主成分分析法(principal component analysis,PCA)、t分布随机邻居嵌入(t-distributed stochastic neighbor embedding,t-SNE)和统一流形逼近和投影(uniform manifold approximation and projection, UMAP)等方法,对于不同的数据特征和适用场景,其效果存在差异。因此,本文基于评估指标的结果,再通过对数据集分别采用上述三种降维方法,并对应不同聚类数量展示,最终确定聚类数量K=3时适合大多数情况,进而根据每轮聚类结果确定数据集适宜的降维方法、聚类中心和每个簇中标签为1的概率。
表3 基于聚类结果的三支决策损失函数Tab.3 The loss function of TWD based on clustering results |
| 行动 | C(P) | ┐C(P) |
|---|---|---|
| aP | λPP=0 | λPN=fq,0 |
| aB | λBP=θ1×λNP | λBN=θ2×λPN |
| aN | λNP=fq,1 | λNN=0 |
2.2 群体三支分类模型
Pur=Gq×ds(q=1,2,…,k)。
式中:Gq=2fq,1(1-fq,1);ds=,在优化模型中受到阈值限制以控制竞争强度。关于群体意见$ \lambda^{n}_{. 。} $,可以通过采用加权计算得到,计算公式如下:
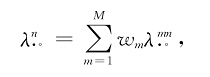
式中决策者权重wm=|Cm|/ |Cq|,为各簇的样本数量占所有样本数据的比例。因此,可以构建群体意见优化模型(6):
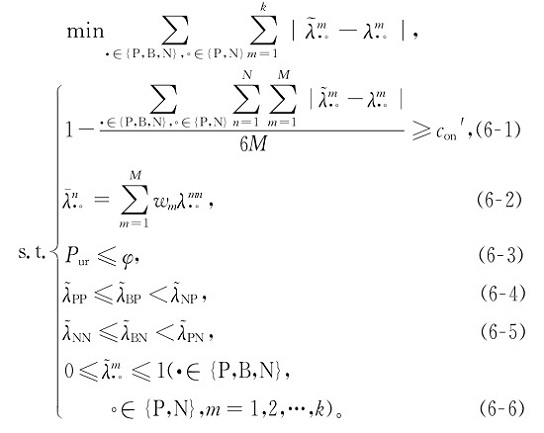
在优化模型(6)中,目标函数是参照文献[21]确定的最小调整公式模型;约束(6-1)是群体决策过程中的共识约束,体现专家意见达成一致;(6-2)是基于公式(5)得到的聚合群体意见;约束(6-3)表示考虑专家领域知识后,通过约束簇的纯度作为簇与簇之间在社会网络中竞争关系的体现;而约束(6-4)~(6-6)分别体现的是三支决策中损失函数的相互关系和作为决策变量的损失函数的取值范围。

在分类过程中为了体现专家对于历史决策结果的自主学习,从而提升决策质量的认知过程,借鉴ML中的增量学习思想[31],测试集中每经过f次测试,将数据原始标签反馈至优化模型(6)进行修正。具体而言,更新各簇的权重使得决策者在社会网络中的重要性趋于合理,同时通过历史决策的原始标签反馈提升决策者对于决策问题的经验认知,从而提升决策质量即分类准确度,权重更新公式如下:
wq= 。
式中:C'q是聚类后的第q个簇;|C'q|则是第q个簇中样本数量。
本文的分类器重点关注样本数据中难以识别的数据,尤其是分类概率处于0.5左右的样本,通过延迟这部分数据的决策,等待后续补充更多信息再判断,从而实现分类效果的提升和决策风险的降低。此处结合ML中逻辑回归方法,通过学习数据特征和sigmoid激活函数计算新样本属于1的概率。对于传统逻辑回归阈值为0.5的判别方式进行调整,利用决策规则(P1)~(N1)进行三支决策分类。对于逻辑回归的训练,对训练集的所有维度特征进行训练,并基于网格搜索确定最优的参数,进而结合上述公式(3)~(7)和优化模型(6),实现基于群体决策的风险评级分类器的建立,整个决策流程如算法1所示。根据算法1的过程,算法由K-means聚类、逻辑回归和群体决策组成,时间复杂度分别对应为O(nkld)、O(nd2)和O(n),进而可以得到算法1的时间复杂度为O(n×(kld+d2+1)。其中:n是样本数量;k是聚类簇的数量;l是聚类的迭代次数;d是特征维度。
2.3 数据实验分析
由于除共识阈值con'以外的超参数对数据集的特征分布敏感,为了验证对比实验效果和实验可重复性,本文首先基于三支风险评级算法1,分别通过超参数搜索进行调参,并结合交叉验证的方法评估算法的性能效果,进而确定表现最好的超参数,具体的超参数设置如表4所示。对于经典的机器学习方法,均采用网格搜索的方法确定最优参数。
表4 超参数设置Tab.4 The settlement of hyperparameters |
| 数据集 | 谨慎态度θ1和θ2 | 纯度阈值φ | 共识阈值con' |
|---|---|---|---|
| Heart failure data | θ1=[0.58,0.45,0.68] | 0.5 | 0.99 |
| θ2=[0.58,0.55,0.45] | |||
| German credit data | θ1=[0.32,0.28,0.28] | 0.2 | 0.99 |
| θ2=[0.32,0.30,0.35] | |||
| Credit-card classification data | θ1=[0.220.15,0.32] | 0.3 | 0.99 |
| θ2=[0.22,0.22,0.42] | |||
| Bank fears loanliness data | θ1=[0.12,0.42,0.33] | 3 | 0.99 |
| θ2=[0.42,0.28,0.16] |
为了评估分类器在预测实例中类别标签方面的效果,本文结合风险评级背景使用准确率(accuracy,记作Acc)、错分率(misclassification rate,记作Rm)、精确率(precision,记作Pre)、召回率(recall,记作Rc)和F1-score(式中记作F1)进行评估。具体评估公式如下所示:
Acc= ,
Rm= ,
Pre= ,
Rc= ,
F1= 。
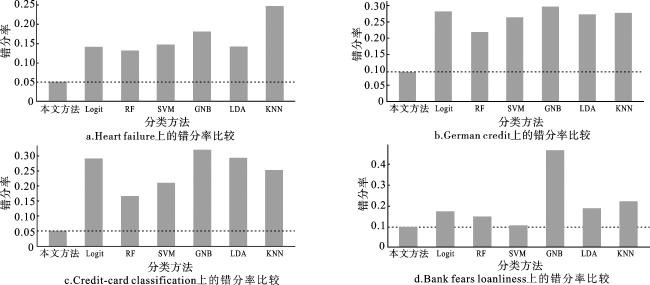
进一步,本文将所提出算法与传统逻辑回归(Logit)、随机森林(RF)、支持向量机(SVM)、高斯朴素贝叶斯方法(GNB)、线性判别分析(LDA)和K近邻(KNN)6种经典机器学习方法在4个数据集上进行分类效果对比,对所提出算法运行10次取平均以降低聚类过程中随机性的影响,相关评估结果如表5~8所示,其中各评估指标中效果最好的用粗体显示,进而通过分别对分类效果在各评估指标上进行排名,并对比各分类器在不同数据集上的错分率,如图1~2所示,可以进一步确定和分析本文所提出算法的效果和对决策风险规避的关注。图1是本文所提出方法和对比方法在准确率、错分率、精确率、召回率和F1-score五个评估指标上得到的模型性能的排序平均值,即各评估指标上效果最优则排序为1,最差为7,进而计算所有指标排名的平均值作为纵坐标值,均值越低说明模型的分类性能和泛化性效果越好。
表5 Heart failure数据集上各方法分类效果对比Tab.5 The performance comparison in Heart failure dataset |
| 分类方法 | 准确率 | 错分率 | 精确率 | 召回率 | F1-score | 运行时间 |
|---|---|---|---|---|---|---|
| 本文所提出方法 | 0.908 7 | 0.050 8 | 0.904 2 | 0.930 2 | 0.912 9 | 1.39 s |
| 逻辑回归(Logit) | 0.860 7 | 0.139 3 | 0.863 8 | 0.860 7 | 0.860 8 | 2.65 s |
| 随机森林(RF) | 0.868 9 | 0.131 1 | 0.871 0 | 0.868 9 | 0.869 0 | 20.4 s |
| 支持向量机(SVM) | 0.852 5 | 0.147 5 | 0.854 6 | 0.852 5 | 0.852 6 | 41.8 ms |
| 高斯朴素贝叶斯方法(GNB) | 0.819 7 | 0.180 3 | 0.826 8 | 0.819 7 | 0.819 7 | 2.4 ms |
| 线性判别分析(LDA) | 0.860 7 | 0.139 3 | 0.862 0 | 0.860 7 | 0.860 8 | 437 ms |
| K近邻(KNN) | 0.754 1 | 0.245 9 | 0.767 3 | 0.754 1 | 0.753 3 | 8.02 ms |
表6 German credit数据集上各方法分类效果对比Tab.6 The performance comparison in German credit dataset |
| 分类方法 | 准确率 | 错分率 | 精确率 | 召回率 | F1-score | 运行时间 |
|---|---|---|---|---|---|---|
| 本文所提方法 | 0.804 9 | 0.091 4 | 0.821 4 | 0.733 5 | 0.774 9 | 3.02 s |
| 逻辑回归(Logit) | 0.719 0 | 0.281 0 | 0.719 0 | 0.719 0 | 0.718 9 | 6.62 s |
| 随机森林(RF) | 0.783 3 | 0.216 7 | 0.784 8 | 0.783 3 | 0.782 8 | 25.2 s |
| 支持向量机(SVM) | 0.738 1 | 0.261 9 | 0.738 3 | 0.738 1 | 0.737 8 | 249 ms |
| 高斯朴素贝叶斯方法(GNB) | 0.702 4 | 0.297 6 | 0.702 3 | 0.702 4 | 0.702 3 | 7.96 ms |
| 线性判别分析(LDA) | 0.728 6 | 0.271 4 | 0.729 0 | 0.728 6 | 0.728 2 | 17.5 ms |
| K近邻(KNN) | 0.723 8 | 0.276 2 | 0.740 6 | 0.723 8 | 0.717 5 | 35.1 ms |
表7 Credit-card classification数据集上各方法分类效果对比Tab.7 The performance comparison in Credit-card dataset |
| 分类方法 | 准确率 | 错分率 | 精确率 | 召回率 | F1-score | 运行时间 |
|---|---|---|---|---|---|---|
| 本文所提方法 | 0.834 4 | 0.049 7 | 0.831 8 | 0.818 4 | 0.824 9 | 31.2 s |
| 逻辑回归(Logit) | 0.707 7 | 0.292 3 | 0.708 3 | 0.707 7 | 0.707 4 | 513 ms |
| 随机森林(RF) | 0.834 1 | 0.165 9 | 0.836 7 | 0.834 1 | 0.833 7 | 120 s |
| 支持向量机(SVM) | 0.790 5 | 0.209 5 | 0.790 5 | 0.790 5 | 0.790 5 | 32.7 s |
| 高斯朴素贝叶斯方法(GNB) | 0.681 8 | 0.318 2 | 0.685 3 | 0.681 8 | 0.680 2 | 13.1 ms |
| 线性判别分析(LDA) | 0.705 5 | 0.294 5 | 0.706 5 | 0.705 5 | 0.705 1 | 40.5 ms |
| K近邻(KNN) | 0.750 4 | 0.249 6 | 0.750 4 | 0.750 4 | 0.750 4 | 986 ms |
表8 Bank fears loanliness数据集上各方法分类效果对比Tab.8 The performance comparison in Bank fears loanliness dataset |
| 分类方法 | 准确率 | 错分率 | 精确率 | 召回率 | F1-score | 运行时间 |
|---|---|---|---|---|---|---|
| 本文所提方法 | 0.884 9 | 0.091 6 | 0.908 9 | 0.858 6 | 0.883 0 | 87 s |
| 逻辑回归(Logit) | 0.829 4 | 0.170 6 | 0.830 8 | 0.829 4 | 0.829 2 | 5.01 s |
| 随机森林(RF) | 0.854 7 | 0.1453 | 0.860 0 | 0.854 7 | 0.854 1 | 167 s |
| 支持向量机(SVM) | 0.896 0 | 0.104 0 | 0.897 6 | 0.896 0 | 0.895 9 | 199 s |
| 高斯朴素贝叶斯方法(GNB) | 0.531 3 | 0.468 7 | 0.690 0 | 0.531 3 | 0.406 0 | 38.6 ms |
| 线性判别分析(LDA) | 0.812 0 | 0.188 0 | 0.814 9 | 0.812 0 | 0.811 6 | 129 ms |
| K近邻(KNN) | 0.780 7 | 0.219 3 | 0.784 9 | 0.780 7 | 0.779 9 | 8.22 s |
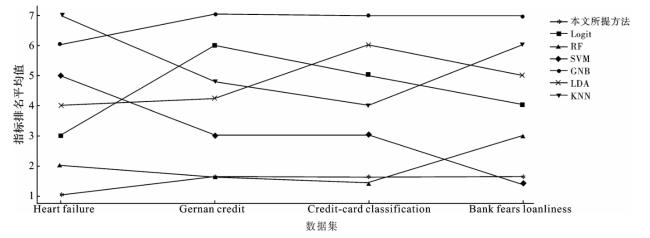
图1 各分类器在多个评估指标的平均排名Fig.1 Average rank of classifiers on different evaluation indices |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
通过对表5~8和图1~2中各模型在各数据集上的分类效果和评估指标的分析可以看出,本文所提方法在Heart failure数据集上的所有评估指标均为最优,在German credit、Credit-card classification和Bank fears loanliness中的准确率、错分率和精确率指标最优,同时所有数据集上的实验结果表明基于群体决策的三支分类方法在所有数据集上的错分率最低,可以有效降低决策风险和减少损失。同时可以发现,传统机器学习中的支持向量机和K邻近方法在不同数据集中表现差异波动较大,对于数据集的特征和分布敏感,不能很好地应用于多领域背景的问题中,而本文方法在各个数据集上均表现稳定且性能较优,在图1中指标排名平均值均小于等于2。在代码运行时间方面,高斯朴素贝叶斯和线性判别分析运行速度较快,但模型精度较差;支持向量机和随机森林方法由于分类效果较好,随着数据集样本数量的增加,计算复杂性增加以致运行时间快速增长;本文算法整体运行时间居中,能够在实现良好模型性能的同时保证代码的时间消耗可接受。
3 总结与展望
本文引入数据驱动的思想,通过信贷评级和疾病诊断的真实数据集,在三支决策理论的框架下考虑决策质量,利用聚类分析构建数据辅助专家决策的风险评级算法。实验结果表明,本文所提算法在多个数据集上对风险分类准确,同时明显降低错分概率,并具有良好的泛化性。
3.1 总结
1)与经典的机器学习方法相比,本文所提方法更加关注决策风险的规避。在风险评级的背景下,尤其是在信贷评级和疾病诊断中,当考虑到错误决策和正确决策分别对应的损失(前者通常极大地高于后者),可以发现避免错误决策对企业的效益更有帮助,并且近似最优的准确率也保证了企业收益。通过考虑超参数谨慎程度θ1和θ2的调整,可以控制收益与风险的权衡。
2)不同数据集由于数据特征和分布的差异,不同分类方法的效果差异明显,泛化性能弱。而本文提出的基于群体决策的三支分类方法,在各个数据集上的分类表现均有稳定且较优的结果,说明通过发现专家领域知识,利用数据的客观信息辅助专家评估风险有助于解决不同背景的决策问题。
3)对于分类信心不足的样本,后续随着更多信息的补充,通过序贯三支决策对其进行更准确的决策和判断,可以进一步提升分类准确率,增强风险评级问题的模型效果。
3.2 展望
本文通过真实数据集来发现专家的评估意见,进而在三支决策理论框架下优化群体意见,完成风险评级,实现了决策质量的可量化,但是总体来说,还存在以下不足。
1)本文虽然设计了结合数据的专家评估发现规则,但未过多关注复杂的决策环境尤其是开放的动态决策环境。对于开放动态环境如何影响专家评估,有待后续进一步深入研究。同时,对于真实环境中风险和收益的权衡考虑较少,本文后续将把正确分类、错误分类和延迟决策的实际效益纳入讨论,阐释本文方法对企业实际决策的实践意义。
2)本文虽然在评估群体决策结果的质量方面进行探索和尝试,但是提出的风险评级三支分类算法主要采用延迟决策来降低风险,对于分类器的自身分类效果关注不足,导致对于某些特定数据集效果相较于经典方法提升不大。此外,后续会对K-means聚类进行改进以提升对评估信息的挖掘发现能力,进一步地改进优化分类算法自身的准确度,实现高性能分类和决策风险降低的优良表现。