

在金融科技场景中,数字化凭证被广泛使用。凭证涵盖身份类如身份证、学生证等;资产类如房产证、银行流水、公积金截屏等;事实证明类如贫困证明、医疗证明、失业证明、拘留证明等。不同凭证的用途不同,例如身份证明类图像用于用户身份核查,资产证明类图像用于用户增信,事实证明类图像用于逾期协商还款、征信异议等。本文主要讨论在贷后服务过程中的事实证明类图像篡改检测技术。基于社会责任和人文关怀考虑,金融机构会对特殊原因导致无法按时还款的客户采取延期还款、利息减免、停息挂账等处置机制。少数用户出于获取不当利益的目的,会篡改凭证图像。在金融机构审核不严格的情况下,容易误判并接受篡改过的凭证。
凭证图像常见的篡改手段包括文本内容和印章篡改。文本内容篡改主要对用户姓名、电话、身份证号、地址等个人信息进行修改,达到非法占用他人证明信息的目的。印章篡改采用Copy-Move真实证明印章、生成假印章、私刻公章等方法,达到滥用凭证开具机构公信力的目的。凭证图像的篡改成本相对较低,行业中篡改现象呈现上升趋势。同时,凭证图像的篡改手法越来越精细,基于人工智能的篡改区域定位方法相较于人工审核,精度更高,成本更低。凭证篡改检测存在三类难点:1)相较于自然场景图像,金融凭证图像篡改区域一般为文字或印章,面积较小,篡改手段精细,一般情况下人工难以识别,同时当前的图像篡改检测方法针对自然场景检测篡改,对于凭证场景下的细微篡改常常出现漏检;2)金融凭证图像来源广泛,不同用户提交的凭证图像质量参差不齐;当前领域相关公开数据稀少,且人工打标成本高昂;3)现实场景中凭证文件的纸张常常存在褶皱、波纹等痕迹,同时存在拍照时的强光、阴影及复杂背景的干扰,当前检测方法抗背景干扰能力不足,存在大量由背景干扰导致的误检。
针对上述难点,本文提出了一种利用上下文语义的凭证篡改检测方法。主要创新点如下:
1)引入上下文语义信息,将凭证中特定元素(文本、印章)的位置和元素之间的关联信息引入模型。缩小篡改检测区域,降低背景噪声对于模型的干扰,提高模型篡改检测精度。
2)细粒度篡改特征提取,通过反卷积模块将HRNet[1]中的高分辨率表征上采样获取更大尺度的特征,从而提取凭证图像中更细粒度的篡改信息。
3)提出了一种端到端的凭证篡改检测方法,在2022年《天池真实场景篡改图像检测挑战赛》数据集和实际场景数据集中结果优于当前主流模型。
1 相关工作
图像篡改检测方法主要分为:基于篡改痕迹检测的方法、基于成像设备固有属性的方法、基于图像内在统计特征的方法、基于深度学习的方法。
基于篡改痕迹检测的方法。首先将图像分块后逐块提取特征(如DCT、PCA、SVD等),再比较图像块之间的特征相似度以判断图像的真实性和定位篡改区域。此类方法可以对加入了噪声和经过压缩的图像进行篡改检测。在2003年,针对数字图像中的Copy-Move问题,Fridrich等[2]提出了一种基于精确匹配的算法,该算法通过图像块分割技术增强了对有损压缩图像的检测能力。Lukas等[3]提出了一种从双重压缩JPEG 图像中估计主量化矩阵的方法。该方法首先识别由双重压缩出现在单个系数DCT 直方图中的特征,然后从二重压缩图像中估计原始量化矩阵,最后对比量化矩阵来进行图像取证。基于图像篡改会扰乱图像自身潜在统计特性的假设,Popescu等[4]提出多种量化检测篡改图像中统计特征扰动的方法,如图像重采样、双JPEG压缩、重复区域检测、噪声模式检测等。
基于成像设备固有属性的方法。真实场景用户使用的成像设备不同,产生图片固有的属性(如CFA特性、JPEG量表等)也不同。当图像中的某个属性呈现多种不同的分布时,可以判断这张图像受到过篡改。Popescu和Farid[5]提出了一种检测量化滤色器阵列(color filter array,CFA)插值引入的特定相关性的方法,该方法在图像的任意部分自动检测这些相关性,并由此判断图像的篡改区域。
基于图像内在统计特征的方法。在图像内容的篡改过程中,往往会产生大量的非线性、不稳定的特性。Shi等[6]利用马尔可夫模型和MBDCT变换捕获这些异常特征并输入SVM进行图像分类。
基于深度学习的方法。在图像取证、图像哈希检索方向中表现出优于传统方法的性能。Wu等[7]首次提出端到端的神经网络用于篡改区域定位。该方法首先通过神经网络从图像块中提取特征,计算不同图像块之间的自相关性,再使用像素级别的特征提取器定位匹配点,最后通过反卷积网络重构篡改掩码。Bunk等[8]提出了利用重采样特征的深度学习图像篡改检测方法。该方法采用重采样特征的拉东变换(Radon transformer)、及长短期记忆(long short-term memory,LSTM) 的网络来捕捉修改区域和非修改区域边界的异常特征。Dong等[9]提出了MVSS-Net,该方法利用RGB流和噪声流分别学习篡改区域周围的边界伪影和噪声分布,同时改进了提取边界的卷积网络,取得了较好的篡改检测效果。Kwon等[10]提出CATNet,该方法引入了HRNet进行多尺度训练,并在训练中保持高分辨率的特征图层,同时通过卷积步长进行下采样操作来避免平滑操作损失信息。凭证篡改场景存在目标区域小,噪声少的特点,本文借鉴了文献[10]中引入HRNet作为主干网络的方法来检测细微的篡改痕迹。
2 方法原理
2.1 公式化表达
设有N张图像Ψ= ,网络首先利用不同分支分别学习特征:
{|1≤j≤n}n=f(xi;Pm),
m∈{R,D,M},n∈{4,3,1}。
式中:R、D、M分别代表RGB、DCT及MASK分支;Pm表示该分支网络的可训练参数;n表示特征集合中的特征图层数量。
之后,将RGB分支特征图层集合{|2≤j≤4}4与DCT分支特征图层集合{|1≤j≤3}3在相同尺度上拼接特征图层,得到特征图层集合{|1≤j≤4}4,经过上采样及卷积处理后得到特征图层 。网络引入反卷积网络,提取包含更多细粒度信息超高分辨率特征图层
vi=d(C({|j=1}4, ,{|j=1}4),Pdeconv),
式中:C(·)表示拼接操作;d(·)表示分卷积网络及后续的卷积操作;Pdeconv表示该模块的可训练参数。
最后,高分辨率特征图层 经由上采样之后和超高分辨率特征图层vi加权平均得到网络输出,可用于不同的下游任务。
2.2 模型结构
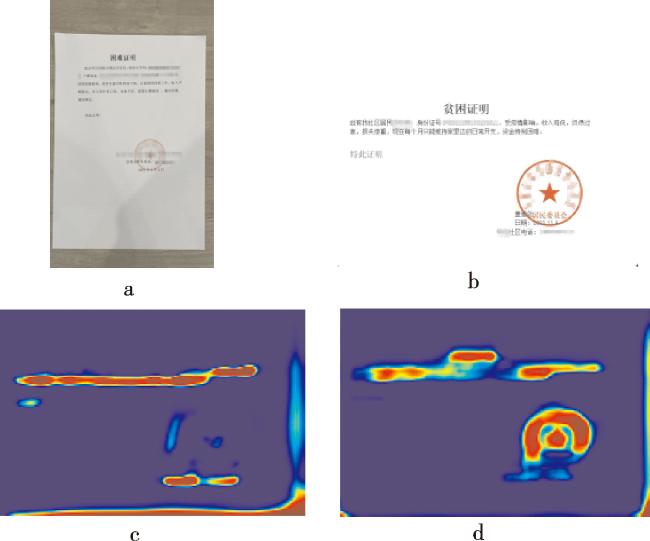
针对环境及背景信息干扰问题,本文通过两点来优化:1)增强数据多样性,用随机生成高光、阴影等方法模拟环境干扰,在此基础上再进行随机裁剪、翻转、亮度变换、色度变换等数据增强;2)引入额外的信息,例如元素位置等上下文语义信息。针对篡改区域面积较小及篡改痕迹隐蔽的问题,本文引入反卷积模块将CATNet中的高分辨率特征图层上采样产生更大尺度的特征图层,有助于模型发现更细微的篡改痕迹。
模型结构如图3所示,主要包括特征提取模块、高分辨率特征处理模块及下游任务模块。
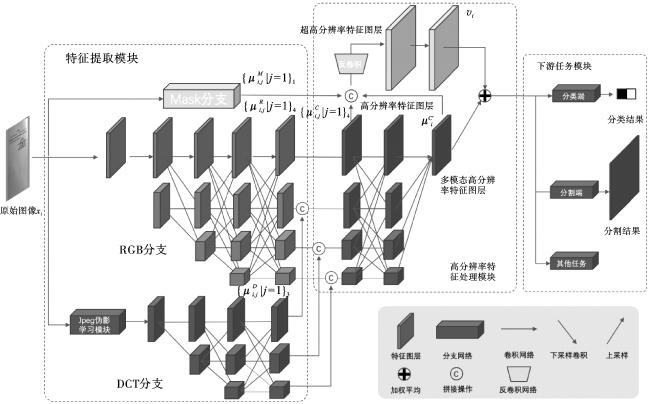
特征提取模块用于在不同纬度上提取图像信息,由三个分支组成。
1)RGB分支,用于提取图像中的视觉信息。在篡改检测任务中,常用的主干网络(如ResNet、VGGNet)会逐步降低特征图层分辨率。这种结构不利于处理位置敏感、目标较小的视觉任务。本方法在RGB分支中使用HRNet作为主干网络,HRNet会在整个特征提取的过程中保持高分辨率的特征图层(设原始输入图像长为H,宽为W;高分辨率特征图层的长H/4,宽为W/4;超高分辨率特征图层的长为H/2,宽为W/2),再并行地将结果传入多个尺度的低分辨率卷积流中,最后融合多个尺度的特征图层。该主干网络学习到的高分辨率表征兼顾空间位置精准和语义表达能力,适用于对空间位置精度要求较高的篡改区域定位任务。
2)DCT分支,用于提取JPEG图像中人眼不可见的压缩伪影信息。由于篡改图像一般会经历多次压缩,而JPEG图像压缩过程中的信息损失会产生各种压缩伪影,可以帮助定位篡改区域。该分支分为两个部分:①提取图像Y通道DCT系数和Y通道量化表作为输入,由JPEG伪影学习模块提取压缩伪影信息并将结果转换为RGB分支中的特征图层形式。②为了不同分支之间的信息交互,本文通过处理提取的压缩伪影信息,确保该分支的HRNet主干网络与RGB分支在不同尺度上对齐。
3)Mask分支,用于提取凭证图像中上下文语义信息(即特定元素的位置信息)。该分支为文字及印章检测网络,输出原始图像中的文字及印章掩码。掩码会在特征融合阶段拼接到高分辨率特征图层中,再通过反卷积得到超高分辨率图层,并进行信息提取,得到各个元素的关联关系。上下文语义信息的引入,可以使得网络根据实际场景需要注意某些特定区域和关联关系,降低复杂背景信息的干扰,进而提升模型篡改的检测精度。
高分辨率特征处理模块用于融合多个特征提取分支的输出,并进行多尺度特征融合及信息抽取,最终得到超高分辨率表征信息。该模块由两个部分组成:
1)多源特征融合组件。该组件用于融合不同特征提取分支的输出。首先根据不同分辨率尺度将RGB分支和DCT分支的输出进行拼接,再将拼接结果进行不同尺度的信息交互,之后对所有尺度的特征图层进行上采样并拼接,最后经由卷积神经网络进行信息抽取得到多模态高分辨率特征图层。
2)超高分辨率处理组件。凭证图像中的篡改体积小、特征少。CATNet网络对很多实际场景的图像存在漏检及误检的情况。基于相关研究[11],不同分辨率的特征图层代表的是不同尺度的信息,分辨率高的特征图层中蕴含了更多细节。本文引入反卷积网络将高分辨率图层上采样为超高分辨率图层,可以提升模型对于小目标及细微篡改痕迹的检测能力。
将HRNet的高分辨率特征图层、多模态高分辨率特征图层及Mask分支掩码拼接作为输入,由反卷积模型得到超高分辨率特征图层,再通过卷积神经网络进行特征提取,并上采样多模态高分辨率特征图层并进行加权平均,最后得到原始图像的超高分辨率表征信息。
下游任务模块主要根据实际任务的需求,利用上述超高分辨率表征输入到下游任务端,例如图像分类、篡改区域定位等。
2.3 目标函数
针对篡改检测场景常见的篡改区域定位任务及实际场景的分类任务,本文使用的损失函数如下。
对于篡改区域定位任务,首先使用像素级别的交叉熵提供监督信息,公式如下:
Lce=-[ylog()+(1-y)log(1- )]。
式中:y表示像素点的标签; 表示网络对像素点的预测值。
由于凭证图像中的篡改较小,对原始图像进行随机裁剪之后的结果通常正负样本分布极不均匀,甚至不包含正样本,所以需要加入Dice损失函数来平衡正负样本,挖掘这种较小的前景区域,公式如下:
LDice=1- 。
式中:|X∩Y|表示X与Y的交集;|X|、|Y|分别表示分割的标签掩码及预测掩码之中像素点的个数。
最终的目标函数如式(3)所示:
L=αLce+βLDice。
式中:α及β为交叉熵损失函数及Dice损失函数的权重。
对于分类任务,本文主要使用图像级别的交叉熵作为目标函数。
3 实验环节
3.1 数据集
本文使用天池2022年“真实场景篡改图像检测挑战赛”的图像数据集,该数据集共2 004张图像。本文将其划分为训练集1 603张图像,测试集401张图像。与CASIA v2等不同的是,本数据集来源于金融领域的篡改场景,包含大量伪造的证书文档类图像、营业执照、资质、文书、截图等。篡改图像包括如Screen Shot、Splicing、Copy-Move、Object Removal等任意操作。在此基础上,部分篡改图像模拟真实场景进行后处理,包括JPEG压缩、重采样、裁剪边缘,社交传输等。该数据集与实际场景较为贴合,可以比较不同模型对凭证图像篡改检测的能力。数据集下载链接为 https://aistudio.baidu.com/aistudio/datasetdetail/129288。
3.2 对比模型
为了保证公平性和可复现性,本文选取的对比模型需要满足以下条件之一:1)论文公布了模型预训练参数;2)论文提供可复现的开源代码。
代码可用。MFCN[14]使用官方开源代码的默认超参数及预训练参数,在本文数据集中进行了100个轮次的模型微调。Swin-Transformer[15]使用开源项目MMSeg实现的swin-transformer-large网络,在本文数据集上进行了100个轮次的模型微调。Segformer[16]模型微调逻辑同Swin-Transformer。CATNet[10]使用官方提供的源码,输入输出图像不做尺寸变换。对于像素级别的篡改区域定位,为了客观地体现不同方法的性能,根据先前的工作[9-10],本文计算像素级别的平均交并比(mIoU)和像素准确率(Pixel_ACC)作为衡量指标。像素级别的mIoU指标及Pixel_ACC指标除特殊说明外,默认阈值为0.5。对于分类任务,由于实际场景准确率要求较高,本文以图像级别的ACC指标衡量模型检测凭证篡改的准确率。
3.3 对比实验
为了综合衡量篡改检测能力,本文进行了实际场景的分类实验和篡改区域定位实验。篡改区域定位实验将篡改检测视为一个语义分割任务,首先将数据集按照5∶1∶1的比例划分为训练集、验证集及测试集。再将上述代码可用和预训练参数可用的算法在篡改数据集上参数微调。最后比较不同方法在测试集图像上的mIoU指标和Pixel_ACC指标。
表1 篡改区域定位对比实验结果Tab.1 Tamper area segmentation comparison experimental results |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3.4 消融实验
为了验证本文创新点的有效性,本文进行了消融实验,结果如表3所示,Mask分支及反卷积模块的引入,都提升了模型在实际场景数据集上的分类能力。
表3 消融实验结果Tab.3 Ablation experiment results |
| 方法 | ACC |
|---|---|
| CATNet | 0.941 5 |
| CATNet+Mask Branch | 0.968 2 |
| CATNet+Mask Branch+Deconv Module | 0.977 0 |
3.5 实现细节
实验使用PyTorch框架,在NVIDIA Tesla V100 GPU上进行训练。SGD优化器初始学习率参数为5×10-4、学习率衰减为5×10-6。模型训练过程中随机裁剪原始图像512×512的子图作为输入,并进行了随机翻转、模糊、颜色空间、色温、亮度变换的数据增强操作。
4 结语
根据实验对比可知,本文提出的方法应用在贷后协商还款场景中,相对于之前方法,提升了3.7%的篡改图像分类正确率。该方法不仅利用了空域和频域的信息,还引入了上下文语义及超高分辨率细粒度信息。从而,降低了复杂的背景干扰,获取了更丰富的细节特征,提升了对于篡改区域的定位能力。
随着生成式神经网络的发展,凭证图像篡改能力会持续提高。本文所采用的数据集为基于人工篡改,未来将会出现生成式的篡改。当前GAN训练的生成式图像模型在某些场景能生成高质量的篡改图像,比如Deepfake作为一种GAN生成方法,能够融合噪声,区域内容以及边缘信息,达到人眼难辨的程度。这对篡改检测提出了极高的要求,因此需要持续优化篡改检测方法。同时,凭证反作弊不是单一金融机构的问题,更多地需要整个金融行业的协同。比如,建立一套凭证篡改数据共享机制,在保护用户隐私的同时,形成产业联盟,与执法部门联动打击作弊团伙,净化金融行业营商环境。