

随着信息技术的飞速发展, 各个领域都收集到了海量高维的数据, 如何从这些数据中提取信息成为统计学、计算机科学及信息科学等领域关注的热点。在处理海量高维数据时, 往往面临NP-hard问题。为了克服传统算法的缺陷,Tibshirani[1]1996年提出了Lasso,该方法既实现了变量选择, 也降低了模型复杂度。在这之后,众多学者开展了基于罚函数的正则化方法研究,例如Fan等[2]提出的SCAD(smoothly clipped absolute deviation),Zhang等[3]提出的MCP(minimax concave penalty)和Xu等[4]提出的L1/2正则化。但是, 目前的数据大多具有组结构,变量选择应该以组为单位筛选出合适的组。对于此类问题,Lasso方法可能会破坏数据的组结构,导致算法失效。为了解决这个问题,Yuan和Lin[5]提出了Group Lasso正则化方法, 将所有协变量分组,在目标函数中惩罚每一组内部的l2范数,组间惩罚l1范数,实现了组间稀疏, 具备了组变量选择能力。由于Group Lasso的有效性及易推广性,带组变量选择的稀疏正则化方法被众多学者推广,如Guo等[6]提出的Group SCAD和Meier等[7]提出的基于Group Lasso的Logistic回归。
同时,对海量数据的分析和处理必然面临侵犯个人隐私的问题。统计学家Dalenius[8]于1977年首次严格定义了数据的隐私,即攻击者在访问数据库的过程中无法获取任意个体的有效信息。基于该定义,K-匿名方法[9]、L-多样性原则[10]和T-紧密性[11]等一系列隐私保护方法被提出,此类隐私保护方法存在两个主要缺陷:其一, 在面对复杂攻击模式时,这些方法不能提供足够的安全保障;其二,这些方法无法量化其隐私保护水平。不仅是理论上的缺陷, 在具体使用场景中经过这些隐私保护方法保护的数据库也已发生多起隐私泄露事件,比如Aol和Netflix的隐私泄漏事件,这些事件造成了恶劣的影响,也促进了学界对隐私保护问题的重视。为了克服这些问题,需要一种全新的隐私保护技术来抵御各种形式的攻击。Dwork[12]提出差分隐私(differential privacy)的概念,该定义将隐私泄露程度量化,确保算法的输出不会严重依赖于任何个体的数据,即便攻击者拥有外部知识,也难以识别个人隐私。差分隐私通过隐私参数ε控制隐私泄露的程度,其定义如下。
定义1(差分隐私[12]) 给定一个随机算法A,Range(·)为随机算法所有可能输出的集合,对于2个相邻数据集D、D'(即只相差一条记录的2个数据集),以及所有的S⊆Range(A),随机算法A满足ε-差分隐私,若
≤eε。
式中:P(A(D)∈S)表示随机算法A的输出属于集合S的概率;ε表示隐私保护程度,ε越小,隐私保护程度越高。
差分隐私在被提出之后, 受到了学界及工业界的广泛关注, 特别是在机器学习领域。拉普拉斯机制[13]和指数机制[14]常用于中心化差分隐私[12],在用户查询过程中添加噪声保护隐私。随机响应机制[15]常用于本地化差分隐私[16],通过随机化回答的方式让受访者在数据收集过程中保持隐私。基于随机响应的算法有RAPPOR[17]、Harmony[18]。进一步,针对高维数据差分隐私,Wang等[19]提出了差分隐私稀疏学习的知识转移框架,Smith等[20]提出了差分隐私模型选择, Talwar等[21]提出了Nearly-Optimal Private Lasso方法。但是针对组结构数据的差分隐私研究成果较少,本文主要研究基于差分隐私的组变量选择问题。
考虑到如今的数据规模, 单机容量和性能难以满足数据分析需求, 并且数据拥有方之间出于各种原因难以进行数据统一存储, 这就对许多统计估计和推断问题提出了新的挑战。例如,在给定N个样本的情况下,经典的估计方法通常会建立一个极大似然估计(maximum likelihood estimate,MLE)问题,然后用优化方法(如梯度下降法或牛顿法)求解极大似然估计。当样本量过大时,采用传统方法有两个主要问题: 其一, 单个机器没有足够的内存来一次加载整个数据集;其二,这些优化方法计算量过大, 单机处理需要大量时间。为了解决存储和计算问题, 众多学者提出了不同的分布式计算方法。较为简单的方法是平均混合(AVGM)算法,即计算机各自训练自身存储的数据,将局部训练结果根据各自的权重加权平均得到整体估计值。另一种分布式算法基于连通的计算机网络。具体地, 整个数据集被分布式存储于相互连通的J台计算机中,各计算机将存储的局部数据加载到各自的内存中,在迭代过程中与邻居交互信息(如梯度或估计量), 以此矫正自身的局部估计量。相关研究成果包括Zhang等[22]提出的分布式优化、Chen等[23]提出的多轮分布式估计方法、Wang等[24]提出的分布式Logistic回归。
本文研究分布式组变量选择问题,提出了分布式Logistic组变量选择模型,并基于ADMM(alternating direction method of multipliers)算法求解该模型;进一步,为了防止计算机交互过程中的隐私泄露,使用随机响应机制对数据进行预处理,提出分布式Logistic随机响应组变量选择算法, 并且证明其满足差分隐私;最后,通过模拟数据和真实数据实验验证了算法的有效性。
1 分布式Logistic组变量选择
作为一种分类模型,Logistic回归被广泛应用于各种场景。本节首先提出分布式Logistic组变量选择模型,其次基于ADMM算法提出分布式Logistic组变量选择算法。
1.1 分布式Logistic组变量选择模型
考虑Logistic组变量选择模型
$ \begin{aligned} \min _{\boldsymbol{\beta}} & \left\{\frac{1}{n} \sum_{i=1}^{n} \sum_{g=1}^{G} \log \left(1+\exp \left(-\boldsymbol{y}_{i} \boldsymbol{\beta}_{g}^{\mathrm{T}} \boldsymbol{x}_{i g}\right)\right)+\right. \\ & \left.\frac{\lambda}{2} \sum_{g=1}^{G}\left\|\boldsymbol{\beta}_{g}\right\|_{2}\right\} 。 \end{aligned}$
式中:xi∈Rp为输入变量;yi∈{-1,1}为输出变量;β∈Rp为模型的系数向量;n为数据量,λ为调控参数。假设xi的p个特征可以被分为G组,第g组的特征个数记为pg,p= pg,xi可被表示为xi=( , ,…, )T,其中组变量xig∈ (g=1,2,…,G),参数β=( , ,…, )T。
由于目前数据量较大,TB乃至PB级别的数据量远远超出单机容量, 单机直接解决问题(1)的算法消耗内存大,运算时间长;所以使用分布式的方法解决这个问题,在运算速度大幅提升的同时,也能够保证最终结果的准确。假设数据分别存储在J台计算机中, 这些计算机构成一个网络。Nj是计算机j的邻居集,|Nj|表示其大小。我们可以使用无向图G=(J,E)表示上述网络,其中节点集合J$\overset{d}{=}${1,2,…,J}代表J台计算机,E为J×J的邻接矩阵,表示网络中边的连接信息,若计算机i与j之间可以互相通信,那么Eij=1,否则Eij=0。如果网络中任意两台计算机之间都可互相通信,该网络就称为连通的。
假设计算机j的局部数据为Dj={xji,yji ,nj为其所储存的数据量且n= nj。依据所属计算机的不同,模型(1)可以改写为
$\begin{aligned} \min _{\boldsymbol{\beta}} & \left\{\frac{1}{n} \sum_{j=1}^{J} \sum_{i=1}^{n_{j}} \sum_{g=1}^{G} \log \left(1+\exp \left(-\boldsymbol{y}_{j i} \boldsymbol{\beta}_{g}^{\mathrm{T}} \boldsymbol{x}_{j i g}\right)\right)+\right. \\ & \left.\frac{\lambda}{2} \sum_{g=1}^{G}\left\|\boldsymbol{\beta}_{g}\right\|_{2}\right\} 。 \end{aligned}$
显然模型(2)与模型(1)等价,为了求解上述分布式模型, 使用以下的分布式正则化方法,用局部估计量{βj 代替全局估计量β,模型(2)可以改写为
$\begin{array}{l} \min _{\left\{\boldsymbol{\beta}_{j}\right\}_{j=1}^{J}}\left\{\frac{1}{n} \sum_{j=1}^{J} \sum_{i=1}^{n_{j}} \sum_{g=1}^{G} \log \left(1+\exp \left(-\boldsymbol{y}_{j i} \boldsymbol{\beta}_{j g}^{\mathrm{T}} \boldsymbol{x}_{j i g}\right)\right)+\right. \\ \left.\frac{\lambda}{2 J} \sum_{j=1}^{J} \sum_{g=1}^{G}\left\|\boldsymbol{\beta}_{j g}\right\|_{2}\right\}, \\ \text { s. t. } \boldsymbol{\beta}_{g g}=\boldsymbol{\beta}_{j^{\prime} g}, j \in \mathscr{F}, j^{\prime} \in N_{j} \text { 。 } \\ \end{array}$
式中,:Nj是计算机j的邻居集;βj=( , ,…, )T。该分布式模型加入了约束条件, 即要求每台计算机的局部估计值与相邻机器相等。由于整个计算机网络连通,模型(3)的约束可以使得每台计算机的局部变量相等, 那么每台计算机的局部估计值也相等。以下定理将表明模型(3)与模型(1)的等价性。
定理1 若无向图G=(J,E)是连通的,那么模型(3)与模型(1)等价。
证明 如果无向图G=(J,E)是连通的,那就表明任意两台计算机之间都可以交换信息,由模型(3)的约束条件可以得到,∀j,j'∈J,∃j1,j2,…,jm,s.t. = =…= = 。那么,∃ ,s.t. = =…= , 既是模型(3)的解,又是模型(2)的解(将等式带入可消去模型(3)的约束),反之亦然,则模型(3)与模型(1)等价。
1.2 分布式Logistic组变量选择算法
基于ADMM算法求解模型(3),首先增加辅助变量Zjg(j=1,2,…,J;g=1,2,…,G),模型(3)可以改写为
log(1+exp(-yji xjig))+ ‖Zjg‖2
s.t.βjg=Zjg,∀j=1,2,…,J。
s.t.βjg=Zjg,∀j=1,2,…,J。
为方便表述,模型(4)可简化为以下向量形式:
f(β)+h(Z) s.t.AZ+Bβ=0。
式中:f(β)= log(1+exp(-yji xjig));h(Z)= ‖Zjg‖2;β和Z为所有局部变量组成的向量,β=[ , ,…, ]T∈R(J×p)×1,Z=[ , ,…, ]T∈R(J×p)×1,矩阵A和B为Z和β的系数矩阵,A=[ , ,…, ]T∈R(J×J×p)×(J×p),其中A*=[Ip×p,…,Ip×p]T∈R(J×p)×(p),0∈R(J×p)×p为零矩阵,A1=[A*,0,…,0],A2=[0,A*,…,0],…,AJ=[0,…,0,A*],B=-[I(J×p)×(J×p),…,I(J×p)×(J×p)]T∈R(J×J×p)×(J×p)。
接下来给出模型(5)的增广拉格朗日函数
L(Z,β,V)=f(β)+h(Z)+<V,AZ+Bβ>+ ‖AZ+Bβ 。
式中:V∈R(J×J×p)×1为拉格朗日乘子;c>0为ADMM算法的预选参数。
算法迭代过程中,依次更新Z、β、V,直至收敛。将以上拉格朗日函数改写为如下形式:
$\begin{array}{l} L\left(\left\{\boldsymbol{Z}_{j}\right\}_{j=1}^{J},\left\{\boldsymbol{\beta}_{j}\right\}_{j=1}^{J},\left\{\boldsymbol{V}_{j}\right\}_{j=1}^{J}\right)= \\ \quad \frac{1}{n} \sum_{j=1}^{J} \sum_{i=1}^{n_{j}} \sum_{g=1}^{G} \log \left(1+\exp \left(-\boldsymbol{y}_{j i \boldsymbol{\beta}_{j g}}^{\top} \boldsymbol{x}_{j i g}\right)\right)+ \\ \quad \frac{\lambda}{2 J} \sum_{j=1}^{J} \sum_{g=1}^{G}\left\|\boldsymbol{Z}_{j g}\right\|_{2}+\frac{c}{2} \sum_{j=1}^{J} \sum_{i=1}^{J} \sum_{g=1}^{G} E_{i j}\left(\| \boldsymbol{Z}_{i g}-\right. \\ \left.\quad \boldsymbol{\beta}_{j g}+\frac{\boldsymbol{V}_{i j g}}{c}\left\|_{2}^{2}-\right\| \frac{\boldsymbol{V}_{i j g}}{c} \|_{2}^{2}\right), \end{array}$
其中Eij表示计算机之间的连接情况。
那么,对于每一台计算机j的第g组变量,ADMM的更新包括以下3个步骤。
步骤1
$\begin{array}{l} \boldsymbol{Z}_{j g}(t+1)=\underset{\boldsymbol{Z}_{j g}}{\operatorname{argmin}} \frac{\lambda}{2 J}\left\|\boldsymbol{Z}_{j g}\right\|_{2}+ \\ \frac{c}{2} \sum_{i=1}^{J} E_{i j}\left\|\boldsymbol{Z}_{j g}-\boldsymbol{\beta}_{i g}(t)+\frac{\boldsymbol{V}_{j i g}(t)}{c}\right\|_{2}^{2} 。 \end{array}$
步骤2
$\begin{array}{l} \boldsymbol{\beta}_{j g}(t+1)= \\ \underset{\beta_{j g}}{\operatorname{argmin}} \frac{1}{n} \sum_{i=1}^{n_{j}} \log \left(1+\exp \left(-\boldsymbol{y}_{j i} \boldsymbol{\beta}_{j g}^{\mathrm{T}} \boldsymbol{x}_{j i g}\right)\right)+ \\ \frac{c}{2} \sum_{i=1}^{J} E_{i j}\left\|\boldsymbol{Z}_{i g}(t+1)-\boldsymbol{\beta}_{j g}+\frac{\boldsymbol{V}_{i j g}(t)}{c}\right\|_{2}^{2} \end{array}$
步骤3
Vjig(t+1)=Vjig(t)+c(Zig(t+1)-βig(t+1))。
使用块坐标梯度下降法(block coordinate gradient descent)对步骤1进行求解,首先令
M(Zjg)=l(Zjg)+ ‖Zjg‖2,
式中
$\iota\left(Z_{j g}\right)=\frac{c}{2} \sum_{i=1}^{J} E_{i j}\left\|\boldsymbol{Z}_{j g}-\boldsymbol{\beta}_{i g}+\frac{\boldsymbol{V}_{j i g}}{c}\right\|_{2}^{2}$。
l(Zjg+djg)在Zjg的二阶泰勒近似为
l(Zjg+djg)≈l(Zjg)+ ∇l(Zjg)+ Hjgdjg。
那么
M(Zjg+djg)= + ‖Zjg+djg‖2。
式中:Hjg是l(·)在Zjg处的海森矩阵;djg∈ 。令M(Zjg+djg)关于djg的偏导等于0,
=∇l(Zjg)+Hjgdjg+ =0,
式中 是‖Zjg+djg‖2在djg处的次梯度。
下面讨论两种情况。当‖-∇l(Zjg)+HjgZjg‖2< 时,‖ ‖2≤1,那么
djg=-Zjg。
当‖-∇l(Zjg)+HjgZjg‖2> ,即当Zjg+djg≠0时, = 。
将其带入(11)式,得到
∇l(Zjg)+Hjgdjg+ =0。
直接求解得
djg= 。
综上,第j台计算机的第g组变量下降的方向为
djg=
M(·)的下降方向确定后给出步长αZ,最终得到
Zjg(t+1)=Zjg(t)+αZdjg。
下面考虑步骤2的更新,利用梯度下降法对其求解,
(t+1)= (t+1)-αβ 。
式中:u为该子问题的内循环标号;令 (t+1)=βjg(t);αβ为该子问题的梯度下降步长; = -c Eij(Zig(t+1)- (t+1)+ )。
对于步骤3,分别更新J个拉格朗日乘子
Vjig(t+1)=Vjig(t)+c(Zig(t+1)-βig(t+1)), i=1,2,…,J。
基于式(12)~(14),提出分布式Logistic组变量选择,算法如下。
| 算法1 分布式Logistic组变量选择算法 |
|---|
| 1:输入:数据D,预选参数c,步长αZ和αβ,组数量G,机器数J,迭代次数T; 2:对于所有j∈J,Zj(0)=(0,…,0)T,βj(0)=(0,…,0)T,Vj(0)=(0,…,0)T,n= nj; 3:for t=1 to T do 4:for g=1 to G do 5:每台计算机局部运行; 6:使用式(12)更新Zjg(t+1); 7:end for 8:令Zj(t+1)=( (t+1),…, (t+1))T并传输给邻居; 9:for g=1 to G do 10:for u=1 to U do 11:利用式(13)更新 (t+1),令βjg(t+1)= (t+1); 12:end for 13:end for 14:令βj(t+1)=( (t+1),…, (t+1))T并传输给邻居; 15:for g=1 to G do 16:利用式(14)更新Vjig,i=1,2,…,J; 17:end for 18:令Vji(t+1)=( (t+1),…, (t+1))T并传输给邻居; 19:end for 20:输出:β=βj(t),∀j∈J。 |
2 分布式Logistic随机响应组变量选择
本节基于随机响应机制提出分布式Logistic随机响应组变量选择算法, 并证明所提算法满足ε-差分隐私。
2.1 随机响应
Warner[15]于1965年提出随机响应机制,其主要是利用被调查者对于敏感数据响应的不确定性来对被调查者的原始数据进行隐私保护。为了便于解释,引入如下具体应用场景。
我们统计一个群体的某疾病患病比例PA时, 调查者会发出“你是否患有某疾病?”的询问,被调查者被指示执行以下步骤:
1)掷一枚硬币;
2)如果是正面, 如实回答;
3)如果是背面, 掷第二枚硬币, 如果第二枚硬币是背面回答是, 正面则回答否。
因此,疾病患者回答“是”的概率是75%,回答“否”的概率是25%。同样地,非患者回答“是”的概率为25%,回答“否”的概率为75%。那么数据收集者可以依据观测到的指标,比如回答“是”的总体比例PY。真实患病比例PA可以这样求解: 我们知道PY=PA×0.75+(1-PA)×0.25,可以依据此得到PA=(PY-0.25)/0.5。
由上例可以看出: 对于分类数据,经过随机响应机制的处理后得到的指标保护了个体参与者的隐私, 同时数据收集者也可以得到这一群体的真实患病比例。这种数据收集方式使用随机化方法, 如掷硬币(真实数据不会被观测到), 通过引入随机噪声的方法保护了被调查者的隐私。
令rand表示[0,1]之间的随机数,p为扰动概率,具体地,对于每一个数据yi,抽取一个[0,1]之间的随机数rand,若rand>p且yi=-1,那么 =1,否则 =-1;当yi=1时亦然。随机响应算法如下。
| 算法2 随机响应算法 |
|---|
| 1:输入分类数据y={yi ,概率值p; 2:for i=1 to n do 3:if yi=-1 4:if rand>p 5: =-1; 6:else 7: =-1; 8:end 9:end 10:if yi=1 11:if rand>p 12: =-1; 13:else 14: =1; 15:end 16:end 17:end for 18:输出y*={ 。 |
定理2 算法2满足ε-差分隐私,其中ε=max{ln(p/1-p),ln(1-p/p)}。
证明 令y={yi 为输入数据,y*={ 为输出数据,算法2表明
P( =1|yi=1)=p,
P( =1|yi=-1)=1-p,
P( =-1|yi=1)=1-p,
P( =-1|yi=-1)=p。
令$S=\left\{y_{i}\right\}_{i=1}^{n}, S^{\prime}=\left\{y_{i}^{\prime}\right\}_{i=1}^{n}$为$S$的相邻数据集,$S^{\prime}$与$S$仅第$j$个数据不同, 即$y_{i} \neq y_{i}^{\prime}$, 若$i=j$。令$O(S)=\left\{y_{i}^{*}\right\}_{i=1}^{n}, O\left(S^{\prime}\right)=\left\{y_{i}^{* \prime}\right\}_{i=1}^{n}$为算法2以$S$和$S^{\prime}$为输人的输出结果,$R=\left\{\bar{y}_{i}\right\}_{i=1}^{n}$为算法2任意可能的输出结果, 那么
= = 。
上式的最后一个等号是由于当i≠j时,yi=y'i。下面分情况讨论 的最大值。
=
故
≤max 。
那么 ≤eε,其中
ε=max =
2.2 分布式Logistic随机响应组变量选择算法
本小节提出基于随机响应机制的分布式Logistic组变量选择算法,具体算法如下。
| 算法3 分布式Logistic随机响应组变量选择算法 |
|---|
| 1:输入: 数据D,预选参数c,步长αZ和αβ,组数量G,机器数J,迭代次数T,概率p; 2:将y和概率p输入算法2并执行,得到y*; 3:将y*,预选参数c,步长αZ和αβ,组数量G,机器数J,迭代次数T输入算法1并执行,得到估计值β*; 4:输出β*。 |
下面给出算法3满足ε-差分隐私的证明。
定理3 算法3满足ε-差分隐私,其中ε=max{ln(p/1-p),ln(1-p/p)}。
证明 由于算法2满足ε-差分隐私,由差分隐私的Post-Processing性质[27](基于ε-差分隐私保护后的结果作为输入的算法依然满足ε-差分隐私),可得算法3也满足ε-差分隐私。
3 实验
我们用单机(2.11 GHz, 8GB RAM, Matlab 2020a)模拟分布式计算机系统,先使用了5-折交叉验证对参数λ进行选择, 然后通过模拟数据实验以及真实数据实验证明了分布式Logistic组变量算法和分布式Logistic随机响应组变量选择算法的有效性。
本文分布式系统(J=5)的邻接矩阵为
E= 。
3.1 模拟数据
本小节使用Yuan和Lin[5] model 3的数据生成方式生成模拟数据。该数据集包含16组协变量和1个响应变量,16组协变量由标准正态分布独立产生,每一组3个,真实变量值如下式,其他均为0。
D= + +X3+ - + X6。
通过以下模型生成分类数据:
p(yi=1|xi)= ,i=1,2,…,n。
式中:xi为输入变量;β∈Rp为系数向量。若p(yi=1|xi)≥0.5,yi=1;否则,yi=-1。
在研究算法有效性之前, 我们使用5-折交叉验证分别选择非分布式Logistic变量选择算法(J=1)中的参数λ,选择结果如图1所示。
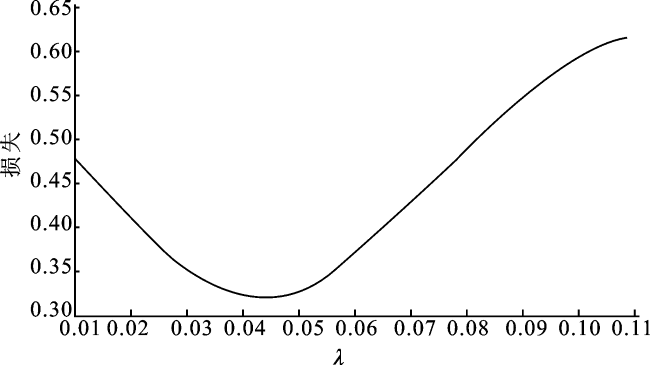
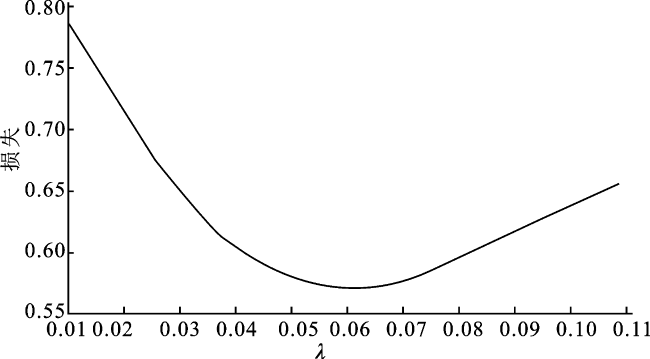
对于分布式算法, 需要使用适合分布式的交叉验证方法: 假设λ∈Λ={λ1,λ2,…,λL},将数据随机分为K部分,记作{ , , 对于计算机j,它的数据可以根据第k部分数据分为2部分,{ , }={Xj,Yj}∩{ , }(既属于第k部分又属于第j台计算机的数据)以及{ , }={Xj,Yj}/{ , }(属于第j台计算机但不属于第k部分的数据)。取{ , }为训练集,{ , }为测试集, 对每一个λ进行验证可以得到{ (λi) ,在测试集{ , }上计算模型损失, 最后选择平均损失最小的λ作为模型参数。选择结果如图2所示。
3.1.1 分布式Logistic组变量选择算法的有效性
为了研究所提算法的有效性, 我们通过实验对比分布式Logistic组变量选择算法和非分布式算法的分类准确率。分别令训练集样本量n=100,200,…,800,测试集样本量为500,研究不同样本量下2种算法的分类结果。对于非分布式实验,直接使用算法1(J=1)进行估计。对于分布式实验(J=5),将数据平均分为5个部分。算法初始值Z0=(0,…,0)T,β0=(0,…,0)T,V0=(0,…,0)T,预选参数c=0.1(J=1),c=0.01(J=5),λ(J=1)=0.08,λ(J=5)=0.102,步长αZ= ,步长αβ=0.4。对于分布式实验和非分布式实验,各运行50次求平均分类准确率, 具体结果如图3所示。
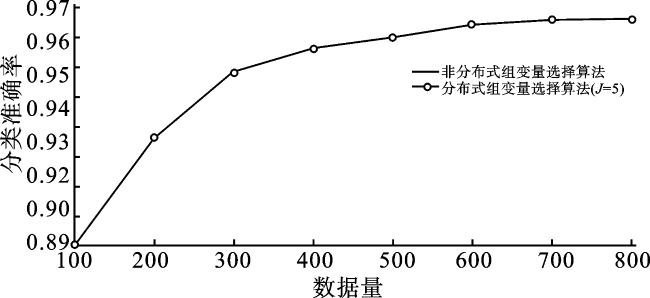
从图3可以观察到, 分布式Logistic组变量选择算法与非分布式算法的分类结果基本相同, 两种算法的分类准确率都随着样本量的增加而增加。
3.1.2 分布式Logistic组变量选择算法的高效性
为研究分布式Logistic组变量选择算法处理大量数据的高效性,分别生成n=104, p=48;n=104,p=96;n=105,p=48三组数据。在调用算法时,选择c=0.1,步长αZ=1/t,步长αβ=0.4,分别将数据不重复地划分为5、10、20个部分。当J=5时,邻接矩阵如第3节中E所示,当J=10和J=20时邻接矩阵为1J×J,即所有计算机都可以直接通信,具体结果如表1所示。
表1 分布式Logistic组变量选择算法的高效性Tab.1 Efficiency of distributed Logistic group variable selection algorithm 单位:s |
| 数据大小 | 算法1(J=5) | 算法1(J=10) | 算法1(J=20) | 算法1(J=1) |
|---|---|---|---|---|
| n=104,p=48 | 102.41 | 52.77 | 28.67 | 496.41 |
| n=104,p=96 | 197.76 | 100.96 | 55.10 | 1 003.79 |
| n=105,p=48 | 998.49 | 528.99 | 259.59 | 5 860.46 |
表1展示了随着计算机数量的增加, 每台计算机的计算时间明显减少, 体现了分布式Logistic组变量选择算法的高效性。
3.1.3 分布式Logistic随机响应组变量选择算法的有效性
3.2 真实数据
为了评估本文算法在真实数据上的表现。我们将算法应用于DNA数据集中,数据来自Meier[7]的MEMset donor数据集,该数据集训练集由8 415个真标签(编码为Y=1)和179 438个假标签(编码为Y=-1)组成,测试集由4 208个真标签(编码为Y=1)和89 717个假标签(编码为Y=-1)组成。协变量由长度为7的碱基序列(具体值为A、T、C、G)构成,我们将碱基对编码为A(1,0,0,0),T(0,1,0,0),C(0,0,1,0),G(0,0,0,1)。选择8 000个真标签数据和8 000个假标签数据作为训练集,3 792个假标签数据和4 208个真标签数据作为测试集,编码后训练集维度为16 000×29,测试集维度为8 000×29。预选参数c=0.01,步长αZ=1,步长αβ=1。图5展示了分类准确率和模型稀疏度之间的关系。
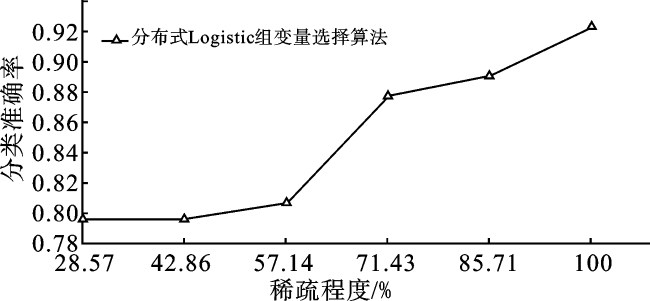
由图5观察到, 算法在模型稀疏的同时也能达到较高的准确率。
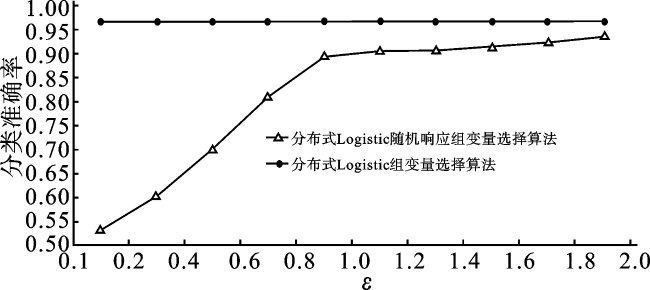
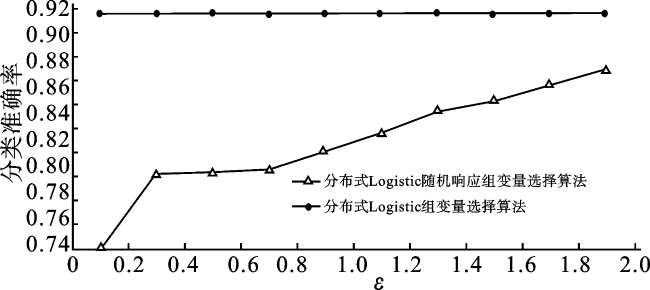
为验证分布式随机响应组变量选择算法在真实数据上的有效性, 本小节使用MEMset donor数据集, 训练集样本量n=16 000,测试集样本量为8 000。我们将训练集随机分为5个部分(J=5),预选参数c=0.01,步长αZ=1,步长αβ=1。比较隐私预算ε大小变化的情况下,分布式Logistic随机响应组变量选择算法(算法3)分类准确率在真实数据上的变化状况,同样取ε={0.1,0.3,0.5,0.7,0.9,1.1,1.3,1.5,1.7,1.9},重复运行50次求平均分类准确率。具体结果如图6所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
从图6可以观察到,对MEMset donor数据进行随机响应操作后,随着ε的增大,分布式Logistic随机响应组变量选择算法(算法3)分类准确率也在增大,隐私保护算法和非隐私保护算法的分类准确率差别逐渐缩小。
4 结语
本文开展基于差分隐私的分布式组变量选择研究。首先,提出了分布式组变量模型, 证明了分布式组变量模型与非分布式组变量选择模型的等价性。其次,基于ADMM算法提出了分布式Logistic组变量选择算法。最后,基于随机响应机制提出了随机响应算法和分布式Logistic随机响应组变量选择算法,并证明其满足ε-差分隐私。实验表明,本文算法能够有效地处理分布式存储的组结构数据并对其提供差分隐私保护。当不同计算机需要不同的隐私保证时,可给不同计算机分配不同的隐私预算。基于此,可推广自适应分布式隐私保护算法,进一步提高算法实际可用性。