

知识空间理论(knowledge space theory,KST)由Doignon和Falmagne于1985年首次提出[1-3],该理论的初衷在于知识评估。迄今为止, KST已被成功应用于辅助学习和自适应测试等多个领域[4-6]。该理论自问世以来, 持续演进, 取得了显著的发展[7-10], 李金海等[11] 对KST的发展历程及研究成果进行了详尽的综述。其中, Doignon等[12]与Düntsch等[13] 引入技能映射与技能函数的概念。技能函数描述特定技能水平与外在表现之间的直接关系, 而技能映射刻画问题和技能之间的对应关系。Heller等[14-15]指出技能函数具有两种特殊情形, 即析取技能函数和合取技能函数。这使原有的知识空间理论得到了拓展, 形成基于能力的知识空间理论(competence based KST, Cb-KST)[16]。
知识结构[1]是KST中的重要概念之一, 其为建立特定领域或学科知识之间的关系并评估学习者掌握的知识提供依据。如何构建知识结构是KST的核心问题之一, 也是进一步规划学习路径的前提和基础。针对这一问题, 许多学者结合其他学科方法来构建知识结构。Rusch等[17]提出了应用形式背景构建知识结构的方法, 有效地结合了形式概念分析与KST。李进金等[18] 提出了基于知识基构建知识结构的方法, 进一步丰富了形式概念分析与KST的联系。Yao等[19]利用粗糙集理论的近似思想构建知识结构。Liu[20]以双论域粗糙集为背景, 研究了技能函数的合取模型与析取模型, 并证明了技能函数通过两种模型构建的知识结构分别为简单闭包空间和知识空间。周银凤等[21-22]基于技能映射和技能背景的对应关系, 从析取模型和合取模型两方面, 讨论构建知识结构的问题。
在Cb-KST中,可以通过合取模型、析取模型和能力模型构建知识结构。从合取模型视角来看, 要求学生完全掌握解决问题需要的所有技能, 才能确保正确解答。而在析取模型下, 学生则只需掌握解决问题所包含的技能中的部分技能, 便有可能成功作答。在能力模型中, 解决问题的能力往往是由多种不同的能力交织而成的,在这种模型中, 学生若完全掌握了其中任意一种能力, 便足以应对问题。但值得注意的是, 这些能力本身又是学生长期学习多种技能后自然形成的。因此, 在能力模型的严格要求下, 学生需要全面掌握某种能力的所有技能, 方能顺利解决问题。
上述方法均侧重于评价学生能否成功解答问题, 却难以深入剖析不同学生在解决相同问题时背后可能存在的独特知识结构。为了弥补这一不足, 杨桃丽等[23]创新性地提出了能力包含度的概念, 并基于此构建了α-变精度能力模型。这一模型不仅有效避免了在评估学生解题能力时可能出现的过于严苛或宽松的问题, 还探索了技能函数通过α-变精度能力模型构建知识结构的极小技能子集族。然而, 值得深思的是, 该模型在不同语义背景下的解释、阈值的设定以及模型本身的动态变化, 都可能对最终构建的知识结构产生影响。因此, 亟待解答的问题是: 阈值取值范围不同, 模型该如何变化?当模型发生变化时, 其构建的知识结构是否会随之发生变化?这些问题的深入探讨, 将有助于我们更全面地理解模型的本质, 为优化教学方法提供有力支持。
因此, 本文基于能力包含度提出了三种构建知识结构的变精度能力模型, 并研究了三种变精度能力模型构建知识结构的相关性质以及与原有变精度能力模型的联系。在引入的最大包含度矩阵概念的基础上, 本文提出了变精度能力模型构建知识结构的矩阵方法, 并设计相应算法;还利用该方法有效地提取了构建知识结构的极小技能子集族; 最后通过实验验证了算法的有效性和在运行时间上的优越性。
1 预备知识
知识状态是KST的基本概念, 个体在理想条件下能正确回答问题集Q中的问题全体K(K⊆Q)称为知识状态(knowledge state).
定义1[1] 设Q为非空有限问题集,K是由知识状态K(K⊆Q)构成的集族,且K中至少包含⌀和Q,称(Q,K)为知识结构。
设(Q,K)是一个知识结构, 若∀Ki,Kj∈K, 都有Ki∪Kj∈K,称(Q,K)为知识空间; 若∀Ki,Kj∈K都有Ki∩Kj∈K,称(Q,K)为简单闭包空间。若(Q,K)既是知识空间又是简单闭包空间, 则称(Q,K)为拟序空间。
定义2[13] 三元组(Q,S,μ)为技能多映射,其中Q、S分别为非空有限问题集和技能集,μ是从Q到 \{⌀}的映射。
在(Q,S,μ)中,∀q∈Q,若满足以下条件:
1)μ(q)≠⌀;
2)∀M∈μ(q),M≠⌀;
3)μ(q)中的能力关于集合包含关系不可比较,则称(Q,S,μ)为技能函数。问题集与技能集给定时,可直接称μ为技能函数。∀q∈Q,称C∈μ(q)是解决问题q的一个极小能力。
设三元组(Q,S,μ)为技能函数,对T⊆S,称KT={q∈Q|∃C∈μ(q),C⊆T}为T通过能力模型诱导的知识状态。当T遍历S的子集时, 得到的知识状态的集合K={KT|T⊆S}称为μ通过能力模型构建的知识结构。
技能函数包含析取与合取两种特殊技能函数。设(Q,S,μ)为技能函数, 若∀q∈Q,都有μ(q)={M},其中⌀⊂M⊆S,则称(Q,S,μ)为合取技能函数;若∀q∈Q,都有μ(q)={{s}|s∈M},则称(Q,S,μ)为析取技能函数。合取技能函数通过能力模型构建的知识结构满足交封闭, 是简单闭包空间; 析取技能函数通过能力模型构建的知识结构满足并封闭,是知识空间。
定义3[23] 设三元组(Q,S,μ)为技能函数。对q∈Q,C∈μ(q),T⊆S,称
D(T/C)=
为问题q关于C和T的能力包含度。
我们将D(T/C)记为 。称D(μ)={ |q∈Q,C∈μ(q),T⊆S}为μ的能力包含度集。将D(μq)={ |C∈μ(q),T⊆S}称为关于问题q的能力包含度集。
设三元组(Q,S,μ)为技能函数。对q∈Q,C∈μ(q),T⊆S,关于能力包含度有如下结论[23]:
1) = ;
2) + =1;
3)D(μ)是有限集, 将其表示为D(μ)={β1,…,βi,βi+1,…,βn},其中0=β1<…<βi<βi+1<…<βn=1,则βi+βn-i+1=1。
例1 设三元组(Q,S,μ)为技能函数,其中Q={q1,q2,q3},S={s1,s2,s3},μ(q1)={{s1},{s2}},μ(q2)={{s1,s2},{s1,s3}},μ(q3)={{s2,s3}}。根据定义3,得到能力包含度如表1。将技能子集简记,如{s1,s2}简记为s1s2;μ(qi)(i=1,2,3)中的能力记为 (l=1,2,…,|μ(qi)|)。
表1 能力包含度Tab.1 Competence inclusion |
| ⌀ | 0 | 0 | 0 | 0 | 0 |
| s1 | 1 | 0 | 0 | ||
| s2 | 0 | 1 | 0 | ||
| s3 | 0 | 0 | 0 | ||
| s1s2 | 1 | 1 | 1 | ||
| s1s3 | 1 | 0 | 1 | ||
| s2s3 | 0 | 1 | 1 | ||
| S | 1 | 1 | 1 | 1 | 1 |
2 γ-变精度能力模型与知识结构
定义4[23] 设三元组(Q,S,μ)为技能函数。对q∈Q,C∈μ(q),T⊆S, 是问题q关于C和T的能力包含度。对α∈(0,1],称 ={q∈Q|∃C∈μ(q): ≥α}为T通过α-变精度模型诱导的知识状态。
设三元组(Q,S,μ)为技能函数。注意到 =0时,则 =⌀; =1时, =Q。则Kα={ |T⊆S}为μ通过α-变精能力模型构建的知识结构。
α-变精度能力模型在区间(0,1],若α=0,则∀T∈S,都有 =Q,表明该模型此时无法构建知识结构。那么阈值在0处取得, 模型该如何变化?构建的知识结构是否会发生变化? 阈值在1处是否取得, 模型如何构建、对模型构建的知识结构有何影响, 这些问题需进一步探究。
定义5 设三元组(Q,S,μ)为技能函数。对q∈Q,C∈μ(q),T⊆S, 是问题q关于C和T的能力包含度。对于γ1∈[0,1),γ2,γ3∈(0,1),则T通过γ1,γ2,γ3-变精度能力模型诱导的知识状态分别为
={q∈Q|∃C∈μ(q): >γ1};
={q∈Q|∃C∈μ(q): >γ2};
={q∈Q|∃C∈μ(q): ≥γ3}。
定理1 设三元组(Q,S,μ)为技能函数。则L ={ |T⊆S}、H ={ |T⊆S}与 ={ |T⊆S}均为知识结构。
证明 由已知,∀q∈Q,当T=⌀时,有 =0,则 = = =⌀;当T=S时, =1, = = =Q。故L 、H 、G 均为知识结构。
定理2 设三元组(Q,S,μ)为技能函数,D(μ)为能力包含度集。当γ1∈[βi,βi+1)(1≤i≤n-1)时,则有L =L 。
证明 由γ1∈[βi,βi+1),∀T⊆S,有 ⊆ ={q∈Q|∃C∈μ(q): >γ1},因βi与βi+1之间无其他能力包含度值,则 ={q∈Q|∃C∈μ(q): >βi}= ,故L =L 得证。
定理3 设三元组(Q,S,μ)为技能函数,D(μ)为能力包含度集。当γ2∈[βi,βi+1)(2≤i≤n-1)时,则有H =H 。
定理4 设三元组(Q,S,μ)为技能函数,D(μ)为能力包含度集。当γ3∈(βi,βi+1](1≤i≤n-2)时,则有 = 。
定理3、4的证明与定理2证明类似。定理3、4中,因两参数取值范围的特殊性, 故未将γ2、γ3分别在区间(β1,β2)与(βn-1,βn)一并考虑在内。由上述结论易知,∀γ2∈(β1,β2),由γ2-变精度能力模型构建的知识结构是相同的,记为 ;同样地,∀γ3∈(βn-1,βn),由γ3-变精度能力模型构建的知识结构也是相同的,记为G 。
定理5 设三元组(Q,S,μ)为技能函数,D(μ)为能力包含度集。则有
=L (1≤i≤n-1)。
证明 ∀q∈Q,T⊆S,由定义4则有 ={q∈Q|∃C∈μ(q): ≥βi+1}, ∈ ;因βi与βi+1之间没有其他能力包含度值,则 ={q∈Q|∃C∈μ(q): >βi},而 ={q∈Q|∃C∈μ(q): >βi},由定理2得 ∈L 。故 =L 。
例2 设三元组(Q,S,μ)为技能函数。其中Q={q1,q2,q3},S={s1,s2,s3,s4},μ(q1)={{s1,s2,s4}},μ(q2)={{s2,s3},{s3,s4}},μ(q3)={{s1,s3},{s1,s4}}。技能函数μ的能力包含度如表2,以及通过α-变精度能力模型与γ1-变精度能力模型构建的知识结构如下。
={⌀,{q1,q2},{q1,q3},{q2,q3},Q}=L0, ={⌀,{q2},{q3},{q2,q3},Q}= , ={⌀,{q1},{q2},{q3},{q1,q2},{q1,q3},Q}=L ,K1={⌀,{q2},{q3},{q1,q3},{q2,q3},Q}=L 。
表2 μ的能力包含度Tab.2 Competency inclusion of μ |
| ⌀ | 0 | 0 | 0 | 0 | 0 | s1 | 0 | 0 | |||
| s2 | 0 | 0 | 0 | s3 | 0 | 0 | |||||
| s4 | 0 | 0 | s1s2 | 0 | |||||||
| s1s3 | 1 | s1s4 | 0 | 1 | |||||||
| s2s3 | 1 | 0 | s2s4 | 0 | |||||||
| s3s4 | 1 | s1s2s3 | 1 | 1 | |||||||
| s1s2s4 | 1 | 1 | s1s3s4 | 1 | 1 | 1 | |||||
| s2s3s4 | 1 | 1 | S | 1 | 1 | 1 | 1 | 1 |
通过上例, 技能函数μ通过α-变精度能力模型与γ1-变精度能力模型构建的知识结构总有对应相同, 那么四种变精度模型分别构建的知识结构是否都存在对应相同?
注:α-变精度能力模型和γj-变精度能力模型构建的知识结构族分别记为(j=1,2,3):
Rα={Kα|α∈(0,1]},
={L |γ1∈[0,1)},
={H |γ2∈(0,1)},
={ |γ3∈(0,1)}。
由定理2~4,Rα, , , 可分别记作
Rα={ ,…, ,…, },
={L ,…,L ,…,L },
={H ,H ,…,H ,…,H },
={ ,…, ,…, , }。
式中: ∈(β1,β2); ∈(βn-1,βn)。
定理6 设三元组(Q,S,μ)为技能函数,Rα, , , 分别为技能函数通过α-变精度能力模型和γj-变精度能力模型构建的知识结构族(j=1,2,3),则有Rα= = = 。
证明 1)由定理5,显然有Rα= ;
2)根据定义4、定义5及定理3,要证明 = ,仅证明L =H 即可,∀T⊆S,有H ={q∈Q|∃C∈μ(q): > },因为β1与β2之间没有其他能力包含度值,则 可改写为{q∈Q|q∈Q|∃C∈μ(q): >β1},而 ={q∈Q|∃C∈μ(q): >β1},则有 = ,故L =H ,证得 = ;
3)再由定义5与定理4,要证明Rα= ,仅证明 = 即可,∀T⊆S,有 ={q∈Q|∃C∈μ(q): ≥ },因为βn-1与βn之间无其他能力包含度值,则 可改写为{q∈Q|∃C∈μ(q): ≥βn},而 ={q∈Q|∃C∈μ(q): ≥βn},则有 = ,故 = ,从而Rα= ;证得Rα= = = 。
由定理6知, 本文提出的三种变精度模型与α-变精度能力模型, 技能函数相同时,具有相同构建知识结构的效果, 但构建相同知识结构的阈值条件存在差异。
定理7[23] 设三元组(Q,S,μ)为合取技能函数,D(μ)为能力包含度集。则有
1)当α∈(β1,β2]时,技能函数μ通过α-变精度能力模型诱导的知识结构Kα是一个知识空间;
2)当α∈(βn-1,βn]时, 技能函数μ通过α-变精度能力模型诱导的知识结构Kα是一个简单闭包空间。
推论1 设三元组(Q,S,μ)为合取技能函数,D(μ)为能力包含度集。则有
1)当γ1∈[β1,β2)时, 技能函数μ通过γ1-变精度能力模型诱导的知识结构L 为知识空间;
2)当γ1∈[βn-1,βn)时,技能函数μ通过γ1-变精度能力模型诱导的知识结构L 为简单闭包空间;
3)当γ2∈(β1,β2)时,技能函数μ通过γ2-变精度能力模型诱导的知识结构H 为知识空间;
4)当γ2∈[βn-1,βn)时,技能函数μ通过γ2-变精度能力模型诱导的知识结构H 为简单闭包空间;
5)当γ3∈(β1,β2]时,技能函数μ通过γ3-变精度能力模型诱导的知识结构 为知识空间;
6)当γ3∈(βn-1,βn)时,技能函数μ通过γ3-变精度能力模型诱导的知识结构 为简单闭包空间。
设三元组(Q,S,μ)为合取技能函数,D(μ)为能力包含度集。则γj-变精度能力模型是析取与合取模型的推广(j=1,2,3),γ1∈[β1,β2),γ2∈(β1,β2),γ3∈(β1,β2]时,相当于析取模型;γ1∈[βn-1,βn),γ2∈[βn-1,βn),γ3∈(βn-1,βn)时,相当于合取模型。并且,析取与合取模型通过同一技能映射构建的知识结构互为对偶。
推论2 设三元组(Q,S,μ)为合取技能函数,D(μ)为能力包含度集。则有
1)知识结构L 与L 互为对偶;
2)知识结构H 与H 互为对偶;
3)知识结构 与 互为对偶。
推论3 设三元组(Q,S,μ)为合取技能函数,D(μ)为能力包含度集。则有
1)L 与L (i=1,…,n-1)互为对偶;
2)H 与H (i=2,…,n-2)互为对偶;
3) 与 (i=3,…,n-1)互为对偶。
3 构建知识结构的矩阵方法与极小技能子集族
3.1 构建知识结构的矩阵方法
前文得到了4种变精度能力模型可构建相同知识结构族的结论, 本节统称其为变精度能力模型。由于在文献[23]中的算法2介绍了基于技能函数获取极小技能子集族和知识结构的算法, 而该算法具有较大的时空复杂度, 因此本节基于最大包含度矩阵概念,提出变精度能力模型构建知识结构的矩阵方法, 并设计相应算法, 以期提高算法效率。
一般技能函数可以看作是多个合取技能函数的合成,故对一般技能函数我们要将其分解成多个合取技能函数处理, 以便解决相关问题。
定义6 设三元组(Q,S,μ)为技能函数。问题集Q={q1,…,qi,…,qn}与技能集S={s1,…,sj,…,st}均为非空有限集,则(Q,S,μ1),(Q,S,μ2),…,(Q,S,μρ)是由技能函数(Q,S,μ)通过分解得到的p个合取技能函数。其中p= |μ(q)|,后文一致。
为利用合取技能函数的特点求解一般技能函数通过变精度能力模型构建的知识结构, 下面定义了合取技能函数布尔矩阵表示形式。
定义7 设三元组(Q,S,μ)为技能函数。问题集Q={q1,…,qi,…,qn}与技能集S={s1,…,sj,…,st}均为非空有限集,由(Q,S,μ)分解的合取技能函数(Q,S,μ1),(Q,S,μ2),…,(Q,S,μp)的矩阵为Mh=( )n×t,其中i=1,2,…,n;j=1,2,…,t;h=1,2,…,p,后文一致。
=
=( ,…, ,…, )为问题qi在合取技能函数(Q,S,μh)下关于S的行向量。类似地,也将技能子集Tl表示为布尔列向量。
定义8 设三元组(Q,S,μ)为技能函数。技能集S={s1,…,sj,…,st}为非空有限集,S的幂集P(S)={T1,…,Tl,…, },则Tl的列向量为 =(Tl(s1),…,Tl(sj),…,Tl(st))',其中
Tl(sj)=
则P(S)的矩阵为P=( ,…, ,…, ),后文一致l=1,2,…,2t。
定理9 设三元组(Q,S,μh)是由技能函数(Q,S,μ)分解的合取技能函数。则在合取技能函数μh下,问题qi关于技能集Tl的能力包含度为
= , ∈μh(qi)。
证明 由能力包含度定义知,证明 =| ∩Tl|即可。因 表示问题qi关于S的行向量, 表示技能集Tl的列向量,故 =| ∩Tl|。
推论4 由定理9,对于合取技能函数μh有如下结论:
1)问题qi关于P(S)的能力包含度行向量为 , ∈μh(qi);
2)技能集Tl关于问题集Q=(q1,…,qi,…,qn}的能力包含度列向量为
= Mh ,
∈μh(qi);
3)合取技能函数μh的能力包含度矩阵Dh为
Dh=( )= MhP,
= , ∈μh(qi)。
例3 由例2,技能函数(Q,S,μ)可分解为4个合取技能函数,其中
μ1(q1)={{s1,s2,s4}},
μ1(q2)={{s2,s3}},
μ1(q3)={{s1,s3}};
μ2(q1)={{s1,s2,s4}},
μ2(q2)={{s2,s3}},
μ2(q3)={{s1,s4}};
μ3(q1)={{s1,s2,s4}},
μ3(q2)={{s3,s4}},
μ3(q3)={{s1,s3}};
μ4(q1)={{s1,s2,s4}},
μ4(q2)={{s3,s4}},
μ4(q3)={{s1,s4}}。
则4个合取技能函数与S幂集的矩阵分别为 M1= ; M2= ; M3= ; M4= ;
P= 。
则4个合取技能函数的能力包含度矩阵为
Dh= MhP。
通过计算分别为
D1= ;
D2= ;
D3= ;
D4= 。
由定义7与定义8,合取技能函数μh下,Tl关于问题集Q的能力包含度列向量 中的元素依次为问题q1,…,qi,…,qn关于Tl的能力包含度。那么Tl通过变精度能力模型诱导的知识状态可利用 变换获得其列向量 =( ,…, ,…, )'。其中
= (i=1,2,…,n)。
定义9 设三元组(Q,S,μh)为合取技能函数。Dh=( )为μh的能力包含度矩阵,称 =( )为技能函数μh通过γ1-变精度能力模型构建知识结构的余矩阵。其中
= (i=1,…,n;l=1,…,2t)。
推论5 设三元组(Q,S,μh)为合取技能函数。 =( )为技能函数通过γ1-变精度能力模型构建知识结构的余矩阵。若将 =( )中相同的列仅保留其一,其余删去,得到矩阵 ,则 各列互异,且 为技能函数通过γ1-变精度能力模型构建知识结构的矩阵.
然而,大多情形下需得到技能函数μ通过γ1-变精度能力模型构建的知识结构。因此, 下面介绍利用矩阵方法求解变精度能力模型构建知识结构的过程。
设三元组(Q,S,μh)为合取技能函数,∀q∈Q,对于技能子集T(T⊆S)通过变精度能力模型诱导的知识状态中若含有q, 则说明C∈μh(q)使得C与T的能力包含度满足阈值条件。
定理10[24] 设三元组(Q,S,μ)为技能函数,将其分解为p个合取技能函数(Q,S,μ1),…,(Q,S,μh),…,(Q,S,μp)。∀T⊆S在技能函数(Q,S,μ)下,T通过变精度能力模型诱导的知识状态为K;在合取技能函数(Q,S,μh)下,T通过变精度能力模型诱导的知识状态Kh(h=1,2,…,p)。则有
K= Kh。
证明 由已知,T⊆S时,T通过变精度能力模型诱导的知识状态有Kh⊆K成立;∀q∈K,总存在一个合取技能函数μh,使得在该合取技能函数下, T通过变精度能力模型诱导的知识状态有q∈Kh成立;故K= Kh得证。
例4(续例3) 取T={s3},γ1=0.4,则技能函数(Q,S,μ)下,技能子集T⊆S通过变精度能力模型诱导的知识状态的特征列向量为(0,1,1),即知识状态为{q2,q3};合取技能函数(Q,S,μh)(h=1,2,3,4)下,技能子集T⊆S通过变精度能力模型诱导的知识状态的列向量分别为(0,1,1),(0,1,0),(0,1,1),(0,1,0),对应知识状态分别为{q2,q3},{q2},{q2,q3},{q2}。故有
{q2,q3}={q2,q3}∪{q2}∪{q2,q3}∪{q2}。
通过例3、例4, 我们能通过矩阵方法得到技能函数(Q,S,μ)通过变精度能力构建知识结构, 利用技能函数(Q,S,μ)分解的所有技能函数的能力包含度矩阵实现。下面给出技能函数的最大能力包含度矩阵的概念,以求得(Q,S,μ)通过变精度能力构建的知识结构。
定义10 设三元组(Q,S,μ)为技能函数。(Q,S,μ1),…,(Q,S,μh),…,(Q,S,μp)是由技能函数(Q,S,μ)通过分解得到的p个合取技能函数。Dh=( )为合取技能函数(Q,S,μh)的能力包含度矩阵。则技能函数(Q,S,μ)的最大能力包含度矩阵为Dmax=(dil),其中dil=max{ |h=1,2,…,p}。
定义11 设三元组(Q,S,μ)为技能函数。Dmax=(dil)为(Q,S,μ)的最大能力包含度矩阵,称 =(bil)为技能函数通过γ1-变精度能力模型构建知识结构的余矩阵,其中
bil=
推论6 设三元组(Q,S,μ)为技能函数。Dmax为技能函数(Q,S,μ)的最大能力包含度矩阵, 则有
1)Tl通过γ1-变精度能力模型诱导的知识状态的列向量 为 的第l列;
2)技能函数(Q,S,μ)的通过γ1-变精度能力模型构建的知识结构的矩阵 ,可通过将 中相同的列仅保留其一, 其余删去而得到。
下面给出通过矩阵方法求得技能函数(Q,S,μ)的通过变精度能力模型构建的知识结构族的算法(以γ1-变精度能力模型为例)。
| 算法1 基于变精度能力模型获取知识结构族 输入:技能映射(Q,S,μ); 输出:知识结构族R。 ①计算求得Dmax; ②从D(μ)中取值γ1i(i=1,2,…,|D(μ)|); ③根据定义11求得 ,进而求得 ,R{i}= (R{i}储存γ1i时的知识结构); ④遍历D(μ),并重复步骤②、③可获得。 |
我们用以下例子来说明上面的算法。
例5 例3中技能函数(Q,S,μ)的最大能力包含度矩阵为 Dmax= 。
γ1=0.5时,得到技能函数(Q,S,μ)的通过γ1-变精度能力模型构建的知识结构的余矩阵如下:
B0.5= 。则技能函数(Q,S,μ)的通过γ1-变精度能力模型诱导的知识结构矩阵为
= 。
对应的知识结构为
L ={⌀,{q1},{q2},{q3},{q1,q2},{q1,q3},Q}。
当γ1遍历D(μ)= 时(取1时为空集), 即可得到。
可以看到, 算法1是可行的, 且提高了求解时运算的并行性, 另外由于变精度能力模型构建的知识结构的余矩阵 和知识结构矩阵 均为布尔矩阵, 可以减少算法对存储空间的需求。
3.2 极小技能子集族
在由技能函数通过变精度能力模型构建知识结构的过程中,可以看到不同技能子集Tl(l=1,2,…,2t)诱导的知识状态可能相同,这说明在构建知识结构时不用遍历所有的技能子集。因此, 对于任意的技能函数, 都存在保持其通过变精度能力模型构建知识结构不变的极小技能子集族。
定理11 设三元组(Q,S,μ)为合取技能函数。 为技能函数通过γ1-变精度能力模型构建知识结构的余矩阵。 中相同的列仅保留其一, 其余删去, 同时保留P中对应列, 得到矩阵 即为技能函数通过γ1-变精度能力模型构建知识结构的极小技能子集族矩阵。P (S)为技能函数通过γ1-变精度能力模型构建知识结构的极小技能子集族。
证明 由推论6得证。
例6 例5中γ1=0.5时, 求得技能函数(Q,S,μ)通过γ1-变精度能力模型构建的知识结构的余矩阵B0.5。保留其第2、6、7、8、9、12、15列, 得到构建知识结构的矩阵
= 。
保留P(S)矩阵P的相应列, 得到极小技能子集族的矩阵
P0.5= 。
则γ1=0.5时,求得技能函数(Q,S,μ)的通过γ1-变精度能力模型构建知识结构的极小技能子集族
P (S)={{s1},{s1,s2},{s1,s3},{s1,s4},{s2,s3},{s1,s2,s3},{s2,s3,s4}}。
注意 1)技能函数(Q,S,μ)的通过γ1-变精度能力模型构建知识结构的矩阵 不唯一, 故构建知识结构的极小技能子集族矩阵 不唯一,且构建知识结构的极小技能子集族P (S)不唯一。
2)γ1取不同的能力包含度值时, 构建知识结构的极小技能子集族矩阵 不相等,亦即构建知识结构的极小技能子集族不同。
例如,γ1= 时, 极小技能子集族的矩阵
= 。
构建知识结构的极小技能子集族P (S)={{s1},{s1,s3},{s2,s3},{s1,s2,s3},{s1,s2,s4},S}与P (S)不相等。
可以看到, 在寻找极小技能子集族时, 涉及技能子集的选择问题。这是由于当用变精度能力模型诱导一个知识状态时, 对应的技能子集可能有多个, 对于具有相同知识状态的不同的个体, 他们能解决的问题一样, 但内在的技能掌握情况还是会有不同, 反映到他们在学习新知识的过程中可能具有不同的接受能力。那么,针对不同个体如何选择技能学习从而改变外在表现是值得进一步研究的。
注 设L 是技能函数(Q,S,μ)通过γ1-变精度能力模型构建的知识结构,对L∈L ,诱导知识状态L的所有技能集矩阵记为 (相应地,集族记为P )。根据例6,我们可以求出知识结构L0.5内所有知识状态对应的技能集矩阵
= ;
= ; = ; = ;
= ; = ;
= 。
通过知识状态对应的技能集矩阵发现, 知识结构L0.5中存在包含关系的知识状态之间, 诱导它们的技能集,可能不存在包含关系。如{q3}⊂{q1,q3},而诱导{q3}的技能集{s1,s3}与诱导{q1,q3}的技能集{s1,s4}或{s1,s2,s4}不存在包含关系。这说明变精度模型构建知识结构时, 知识状态之间若存在包含关系, 会出现个体表现层次跳跃的情形。如先假设某个体的知识状态为{q3}, 个体通过学习技能s4,其状态未经历{q1,q3}而直接表现为Q。下面介绍有效学习路径和有效技能学习路径的定义,并通过例7简单讨论有效学习路径与有效技能学习路径不一定能同步的情况,它们之间的进一步联系有待今后继续研究。
定义12[1] 设三元组(Q,S,μ)为技能函数。技能函数通过变精度模型构建的知识结构L ,其中L1,L2∈L ,有L1⊂L2且不存在L3∈L ,使得L1⊂L3⊂L2成立。则称满足从⌀到Q这样的链为有效学习路径。
定义13[23] 设三元组(Q,S,μ)为技能函数. 技能函数通过变精度模型构建的知识结构L ,其中L1,L2∈L ,有L1⊂L2,∀P ,P ,取T'∈P ,T″∈P 且T'⊂T″,则称…⊂T'⊂T″⊂…为有效技能学习路径。P 表示诱导知识状态L的技能子集族。
以下根据有效学习路径和有效技能学习路径的定义举出例子说明它们的差别。
例7 例6中的知识结构L ={⌀,{q1},{q2},{q3},{q1,q2},{q1,q3},Q}。根据定义12、13规划出个体的技能学习路径如图1。在图中, 知识状态和技能记为向量形式。如{q3}记为(0,0,1),{s1,s3}记为(1,0,1,0)。
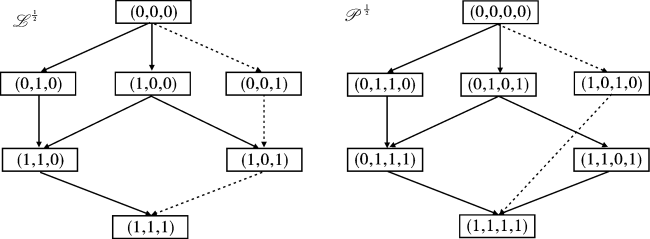
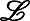
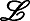
图1中左图为基于L 的有效学习路径图, 其中箭头表示知识状态之间的包含关系; 右图为左图对应的有效技能学习路径图之一, 其中箭头表示技能子集之间的包含关系。图中从⌀到Q的学习路径,不一定有对应的有效技能学习路径, 如⌀→{q3}→{q1,q3}→Q,没有对应有效技能学习路径, 即图中虚线链⌀→{s1,s3}→S。即个体处于状态{q3}时, 不存在技能使得个体学习该技能后状态前进为{q1,q3}。可以发现, 同一知识结构存在多条学习路径, 但与这些学习路径对应的有效技能学习路径不一定都存在。故已知个体知识状态时, 其可根据相应的有效技能学习链, 选择合适的技能进行学习。如图中虚线的路径是不被推荐的。
4 实验与数据分析
为了验证本文研究变精度模型构建知识结构矩阵算法的有效性, 从UCI (http://archive.ics.uci.edu/ml/datasets.php)数据库中选取了6个数据集进行实验分析, 具体详情如表3所示.所有实验运行环境为Windows 7 操作系统,硬件环境为 Inter(R)Core(TM)i7-6700 CPU @3.40 GHz, 运行内存8.00 GB 内存,软件环境为 MATLAB(R2021b)。
表3 数据集Tab.3 Datasets |
| 名称 | 对象个数 | 属性个数 |
|---|---|---|
| Ecoli | 336 | 8 |
| Pima | 768 | 9 |
| Lenses | 26 | 4 |
| StoneFlakes | 79 | 8 |
| Hayes | 132 | 5 |
| Post | 90 | 8 |
各技能函数通过变精度能力模型构建的知识结构会因参数取值的变化而不同。根据前文所得结论, 6个技能函数通过变精度能力模型构建知识结构的个数如表4。
表4 技能函数Tab.4 Skill function |
| (Qi,Si,μi) | |Qi| | |Si| | 知识结构个数 |
|---|---|---|---|
| (Q1,S1,μ1) | 187 | 8 | 18 |
| (Q2,S2,μ2) | 401 | 9 | 22 |
| (Q3,S3,μ3) | 9 | 6 | 6 |
| (Q4,S4,μ4) | 32 | 8 | 12 |
| (Q5,S5,μ5) | 8 | 6 | 6 |
| (Q6,S6,μ6) | 17 | 9 | 18 |
表5 算法运行时间Tab.5 Algorithm runtime 单位:s |
| (Qi,Si,μi) | 文献[23]算法 运行时间 | 本文算法 运行时间 |
|---|---|---|
| (Q1,S1,μ1) | 3.346 7 | 0.084 9 |
| (Q2,S2,μ2) | 14.287 6 | 0.133 4 |
| (Q3,S3,μ3) | 0.085 0 | 0.011 8 |
| (Q4,S4,μ4) | 0.831 0 | 0.034 3 |
| (Q5,S5,μ5) | 0.092 9 | 0.012 9 |
| (Q6,S6,μ6) | 0.895 0 | 0.047 0 |
注:加粗表示最优。 |
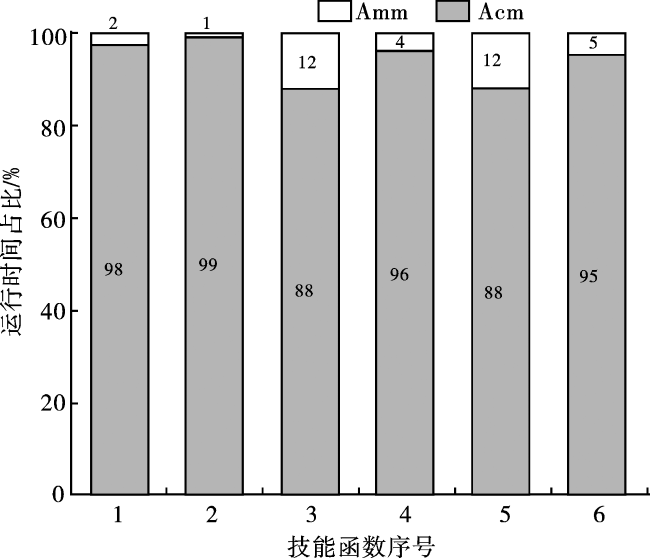
实验结果表明, 本文提出的矩阵方法是可行的, 与原有的实验方法相比, 该方法不仅在算法运行时间方面具有优越性, 而且优化了数据的存储方式。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5 结语
本文基于能力包含度提出了三种变精度能力模型用于构建知识结构, 研究了三种模型构建知识结构的性质, 讨论了四种变精度能力模型的联系, 并证明四种变精度能力模型在同一技能函数下构建知识结构族的效果是相同的。此外, 本文还提出了技能函数通过变精度能力模型构建知识结构的矩阵方法, 设计了相应算法, 且该方法适用于四种变精度能力模型。最后, 通过本文给出的技能函数最大能力包含度矩阵的概念,给出了寻找技能函数通过变精度能力模型构建知识结构的极小技能子集族的方法, 并实验验证了矩阵方法构建知识结构的优越性。本文变精度能力模型没有考虑学习成本问题,即问题的难易程度、技能的重要程度等都会影响知识结构的构建,综合这些因素如何构建更切合实际的知识结构是一个至关重要的课题。另外, 本文中未进一步探讨个体的学习路径规划, 使得其有效学习路径能对应有效技能学习路径,且本文也未考虑模糊情形下变精度能力模型构建知识结构的方法, 这些都将作为后期的研究内容。