

混合型属性数据在医学健康、金融、营销等众多领域中应用广泛。为解决混合型属性数据聚类问题,研究者们在传统聚类算法上做出改进,改进思路分为两种策略:一种是将数据集通过各种各样的方式转化为同一种类型的数据集,进而应用现有算法进行聚类;另一种则是对相似度度量进行设计。
对于第一种策略,David等[1]提出SpectralCAT算法,通过将数据自动转换为分类型数据,再使用谱聚类实现聚类;Barcelo-rico等[2]使用极坐标将分类特征编码成数值特征后使用传统k-means算法实现聚类;文献[3]提出一种基于互信息的无监督特征转化方法,将分类特征转换为数值特征后使用k-means算法进行聚类。这些改进与对混合型属性数据直接使用经典算法聚类相比确实提升了聚类效果,但数据转换过程难免造成信息损失。
在通过第二种策略进行改进的算法中,针对混合型属性数据聚类最经典的2种算法是由Huang提出的Kprototypes算法[4]和McParland等提出的ClustMD算法[5]。Kprototypes算法通过结合k-means算法和k-modes算法来实现对混合型属性数据的聚类,但该方法易收敛到局部最优,运行结果不稳定;ClustMD算法使用潜在变量模型对混合型属性数据进行聚类,并使用EM算法对ClustMD的参数进行估计;刘超等[6]证明了数据相关性强、缺失值多、分类型数据所占比重较大时,Kprototypes的效果要优于ClustMD。Chatzis[7]通过假设数据符合高斯分布,对Kprototypes算法进行扩展提出了KL-FCM-GM算法,该算法在Honda和Ichihashi[8]提出的FCM型模糊聚类成本函数中采用了概率差异函数;Cheung等[9]提出OCIL算法;赵兴旺等[10]提出基于信息熵的混合数据属性加权聚类算法,解决了高维混合数据聚类中属性加权的问题。这些算法改善了簇归属的问题,但由于是基于迭代的方法,故对初始聚类中心十分敏感,更适合凸簇数据。
谱聚类是一种现代聚类方法,能够适合于任意形状数据的聚类问题且能收敛于全局最优解。研究者们主要从相似矩阵的构造、特征向量的选取、聚类数目的确定、参数的优化设置等方面对谱聚类算法进行改进且取得了不错的效果[11⇓⇓-14],但以上改进都是适用于数值型数据的。近年来,有研究者利用谱聚类的优势,将其扩展到混合型属性数据聚类中。马恒等[15]提出SCBMDSM算法,通过实验验证了该算法的准确率与SBAC和Kprototypes算法相比确实有所提升;姜智涵等[16]提出EBSCMD算法,并通过实验与Kprototypes、KL-FCM-GM、OCIL算法对比验证了所提算法的有效性;Mbuga等[17]用不同的不相似度度量代替了传统谱聚类中的欧氏距离度量,采用加权和全局不相似度测量的方式构建相似度矩阵,并将他们的实验结果与Kprototypes和KAMILA进行对比,验证了他们所提方法的有效性。以上改进避免了数据类型转换带来的信息损失,且能够适应于任意形状数据,但依旧存在某些不足。例如,有些设计没有考虑到数值型数据之间的关联及其本身重要度对于聚类结果的影响,故对于混合型属性数据谱聚类方法相似性度量的设计仍有改进空间。
基于以上讨论分析,本文提出了一种针对于混合型属性数据的改进谱聚类算法(improved Jaccard and Mahalanobis-spectral clustering, IJM-SC)。基于改进的Jaccard系数、马氏距离,设计了一个新的相似性度量,该相似性度量不需要对数值型数据或分类型数据进行转换,避免了类型转换带来的信息损失,且能够消除数值型数据量纲的影响,提高分类型数据的相似度计算的精确度和稳定性。最后,根据谢娟英等[18]提出的一种运行时间更短的全局k-means聚类算法得到最终的聚类簇。
本文的主要贡献包括3个方面:
1)设计了一种适用于混合型属性数据的相似度距离,能够更合理地衡量该类型数据集样本间相似度。
2)将设计的相似度距离扩展到谱聚类相似度矩阵、拉普拉斯矩阵的构建中,提出IJM-SC算法。该算法适用于任意形状数据,且通过形成更贴切的相似度矩阵,达到提升谱聚类算法对于混合型属性数据的聚类效果的目的。
3)将提出的算法应用于UCI机器学习数据库混合型属性数据集的聚类中,并将聚类效果与现有文献中的算法进行对比,验证了本文所提算法的有效性、优越性。
1 预备知识
本节主要对相似度度量和谱聚类算法的相关知识做出介绍。
1.1 相似度度量
聚类算法中常见的相似性度量有闵氏距离、余弦相似度、马氏距离、Jaccard距离、汉明距离等。对于样本数据集X={x1,x2,…,xn},n代表样本数目,xi=(xi1,xi2,…,xim)样本维数为m,对于任意两点xi,xj∈X常见的度量方式有如下形式[19-20]。
闵氏距离:
$ d\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left(\sum_{q=1}^{m}\left|x_{i q}-x_{j q}\right|^{p}\right)^{\frac{1}{p}}$。
闵氏距离把各个属性量纲等同对待且没有考虑各个属性分布特征,可能会对聚类结果产生消极影响。
Jaccard距离:对于两个集合A、B,他们之间的相似度定义为
$\begin{aligned}J(A, B)= & \frac{|A \cap B|}{|A \cup B|}= \\& \frac{|A \cap B|}{|A|+|B|-|A \cap B|^{\circ}}\end{aligned}$。
由于该相似性度量方式更关注于样本间具有的共同特征是否一致,无法衡量具体差异大小,故该相似度衡量方式主要应用于计算二元属性对象的相似性,常被用于文本相似度计算。
马氏距离:
$ d_{\mathrm{m}}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\sqrt{\left(\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right)^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}\left(\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right)}$。
式中,Σ-1表示样本协方差矩阵的逆矩阵。该相似性度量可以消除不同属性间量纲差异较大带来的影响,亦可克服数据多重线性相关的缺点,但协方差矩阵的逆矩阵可能不存在,此时需要使用其他办法进行处理。
以上相似度度量各有其优缺点且只适用于单类型数据的相似性衡量,对于混合型属性数据难以达到好的效果。
1.2 谱聚类算法
谱聚类算法是基于谱图理论的聚类算法,它将原始数据X={x1,x2,…,xn}的聚类问题转化为图最优划分问题,把任意的数据样本xi视为图中的顶点vi∈V,点之间用带有权重的边连接,即对于vi,vj∈V,以eij∈E表示这两个顶点之间的边,以wij∈W表示边eij的权重,故而得到无向图G=(V,E)。距离较远的点之间边权重低,距离较近的点间边权重高,按照一定的划分准则对形成的原图G进行切图,可得到k个交集为空的子图g1,g2,…,gk,并通过使不同子图gi和gj间边的权重之和尽可能低,子图内边的权重之和尽可能高,达到最终聚类的目的[21]。
对称正则化的谱聚类算法目标函数为[22]
$ \begin{aligned}\min _{F} \operatorname{tr}\left(\boldsymbol{F}^{\mathrm{T}} \boldsymbol{L}_{\mathrm{sym}} \boldsymbol{F}\right), \\\text { s. t. } \boldsymbol{F}^{\mathrm{T}} \boldsymbol{F}=\boldsymbol{I}\end{aligned}$。
式中:F∈Rn×k包含k个正交向量;Lsym为对称正则化的拉普拉斯矩阵。
谱聚类算法在继承了传统聚类算法思想的基础上,结合了图谱优化理论,使聚类算法的普适性大幅提高。但一方面,谱聚类算法聚类效果很大程度上依赖于依据相似性度量生成的拉普拉斯矩阵,另一方面,谱聚类在数值型数据上表现效果很好,而在实际应用中许多数据集是混合类型的,故此时需要设计更合适的相似性度量才能使谱聚类发挥更好的效果。本文在谱聚类算法框架下,通过相似性度量的设计,提高谱聚类算法对于混合型属性数据的聚类效果。
2 改进的谱聚类算法
本节主要介绍对于相似度度量的设计以及本文改进算法的原理,实现谱聚类的混合型属性数据聚类扩展。
设输入的数据空间为X={x1,x2,…,xn}表示n个混合型属性数据对象的样本集。对于每一个xi,i∈{1,2,…,n},都有M=(Ms+Mt)个属性 , ,…, , ,…, 。在数据集中以 , ,…, 代表Ms个分类型数据, , ,…, 代表Mt个数值型数据。 代表 的第k个属性, 表示分类型数据部分; 代表 的第k个属性, 表示数值型数据部分。与传统的相似度测量方式不同,本文构建了一个关于混合型属性数据的相似性度量矩阵,该矩阵需要融合分类型数据的相似度矩阵和数值型数据的相似度矩阵。
2.1 相似度矩阵的生成
2.1.1 分类型数据相似度矩阵的生成
本文定义 和 之间的相似性度量为S'( , )具体表示如下:
$ S^{\prime}\left(\boldsymbol{x}_{i}^{(s)}, \boldsymbol{x}_{j}^{(s)}\right)=\frac{\delta_{i, j}}{\left|\boldsymbol{x}_{i}^{(s)} \cup \boldsymbol{x}_{j}^{(s)}\right|},$
$ \delta_{i, j}=\sum_{k=1}^{M_{s}} \delta_{i, j, k}$
$ \delta_{i, j, k}=\left\{\begin{array}{ll}1x00026; x_{i, k}^{(s)}=x_{j, k}^{(s)} \\0& x_{i, k}^{(s)} \neq x_{j, k}^{(s)}\end{array}\right.$
式中:δi,j表示两个数据样本分类型数据对应位置元素相同与否的结果;| ∪ |表示 和 中所有元素取并集后元素总个数,也可以写成如下形式:
$ \left|\boldsymbol{x}_{i}^{(s)} \cup \boldsymbol{x}_{j}^{(s)}\right|=\left|\boldsymbol{x}_{i}^{(s)}\right|+\left|\boldsymbol{x}_{j}^{(s)}\right|-\left|\boldsymbol{x}_{i}^{(s)} \cap \boldsymbol{x}_{j}^{(s)}\right| 。$。
由此构建出的分类型数据的相似度矩阵如下:
$\begin{array}{l}\boldsymbol{S}^{\prime}=\left(\begin{array}{ccc}S^{\prime}\left(\boldsymbol{x}_{1}^{(s)}, \boldsymbol{x}_{1}^{(s)}\right) & \cdots & S^{\prime}\left(\boldsymbol{x}_{1}^{(s)}, \boldsymbol{x}_{n}^{(s)}\right) \\\vdots & \ddots & \vdots \\S^{\prime}\left(\boldsymbol{x}_{n}^{(s)}, \boldsymbol{x}_{1}^{(s)}\right) & \cdots & S^{\prime}\left(\boldsymbol{x}_{n}^{(s)}, \boldsymbol{x}_{n}^{(s)}\right)\end{array}\right)- \\\left(\begin{array}{ccc}1 & \cdots & 0 \\\vdots & \ddots & \vdots \\0 & \cdots & 1\end{array}\right)_{n \times n}= \\\left(\begin{array}{ccc}0 & \cdots & S^{\prime}\left(\boldsymbol{x}_{1}^{(s)}, \boldsymbol{x}_{n}^{(s)}\right) \\\vdots & \ddots & \vdots \\S^{\prime}\left(\boldsymbol{x}_{n}^{(s)}, \boldsymbol{x}_{1}^{(s)}\right) & \cdots & 0\end{array}\right)\end{array}$
S'是一个n×n的矩阵,公式(1)中减去单位阵的原因在于每个 与其自身的相似度为1,但从图的角度看 与自身之间没有边连接,自然没有边权重值,故需在原始的邻接矩阵后减去一个n×n的单位阵,使其满足对角线上的元素全部为0, 从而符合实际意义。
2.1.2 数值型数据相似度矩阵的生成
对于数值型数据,传统的谱聚类算法使用欧氏距离生成高斯核函数矩阵作为相似度矩阵。考虑到欧氏距离忽略数据量纲之间的差异、将样本的不同属性之间的差别等同对待的缺点和马氏距离计算建立在总体样本基础上、不受量纲的影响、且能排除属性之间相关性的干扰的优点,本文考虑使用马氏距离生成的高斯核函数矩阵来构建数值型数据的相似度矩阵。由于协方差矩阵可能是奇异矩阵,因此本文采用样本数据协方差矩阵的广义逆矩阵来替代协方差矩阵的逆矩阵。
伪逆矩阵是逆矩阵的广义形式,是通过SVD计算得到。由相关定理知对于任意一个矩阵Y,Y的伪逆矩阵一定存在且满足
$ \boldsymbol{A} \boldsymbol{Y} \boldsymbol{A}=\boldsymbol{A}, \boldsymbol{Y} \boldsymbol{A} \boldsymbol{Y}=\boldsymbol{Y}$。
对于伪逆矩阵的计算,在矩阵Y为奇异矩阵时,需先对其进行奇异值分解:
$ \boldsymbol{Y}=\boldsymbol{U} \boldsymbol{D} \boldsymbol{V}^{\mathrm{T}}$。
式中:U、V是正交阵;D是对角阵。另取对角阵Z,如果D(i,i)=0,那么Z(i,i)=0, 如果D(i,i)≠0,那么Z(i,i)=1/D(i,i)。此时矩阵Y的伪逆矩阵为
$ \boldsymbol{Y}=\boldsymbol{V} \boldsymbol{Z} \boldsymbol{U}^{\mathrm{T}} \text { 。 }$。
本文定义 和 之间的相似性度量为S″( , ),具体为
$ \begin{array}{c}S^{\prime \prime}\left(\boldsymbol{x}_{i}^{(t)}, \boldsymbol{x}_{j}^{(t)}\right)=\mathrm{e}^{-\frac{d_{m}^{2}\left(x_{i}^{(t)}, x_{j}^{(t)}\right)}{2 \sigma^{2}}}= \\\mathrm{e}^{-\frac{\left(x_{i}^{(t)}-x_{j}^{(t)}\right)^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}\left(x_{i}^{(t)}-x_{j}^{(t)}\right)}{2 \sigma^{2}}}= \\\mathrm{e}^{-\frac{\left(x_{i}^{(t)}-x_{j}^{(t)}\right)^{\mathrm{T}} \boldsymbol{V Z U} U^{\mathrm{T}}\left(x_{i}^{(t)}-x_{j}^{(t)}\right)}{2 \sigma^{2}}} 。\end{array}$
由此,仿照公式(1)即可构建出数值型数据的相似度矩阵。
2.1.3 混合型属性数据相似度矩阵的生成
通过式(1)、(2)生成的分类型数据和数值型数据的相似度矩阵,可以构建整体混合型属性数据的相似度矩阵。考虑到分类型数据属性个数与数值型数据属性个数不同,直接将这两种类型数据的相似性矩阵进行相加不合理,且分类型数据相似度衡量时没有用到高斯核函数。因此,引入两个系数α和γ,分别以分类型数据和数值型数据中所含属性个数在属性总个数中的占比作为α、(1-α),计算公式为
$ \alpha=\frac{M_{s}}{M},$
γ则作为分类型数据相似度的一个控制因子,可以对分类型数据相似度进行一定程度的放缩,本文设计的γ为
$ \gamma=\mathrm{e}^{-\frac{\max \left(\boldsymbol{S}^{\prime \prime}\right)-\min \left(\boldsymbol{S}^{\prime}\right)}{2 \sigma^{2}}}.$
式中:max(S″)表示生成的数值型数据相似度矩阵全部元素中的最大值;min(S')表示生成的分类型数据相似度矩阵全部元素中的最小值;二者之差代表着两种形式计算相似性度量的最大差异,作为分子,二者差异越大,则参数值越小,分类型数据未使用高斯核函数所带来的影响也会变小;另一方面,在实际代码运算实验的过程中发现,用数值型相似矩阵全局最大值与分类型数据相似矩阵的全局最小值之差要略优于用数值型相似矩阵全局最小值与分类型数据相似矩阵的全局最大值之差。参数σ与公式(2)中σ取值相同。γ用来削弱在分类型数据相似度计算时没有使用高斯核函数而带来的影响。本文定义xi和xj之间的相似性度量为S(xi,xj),计算公式为
S(xi,xj)=α·γ·S'( , )+
(1-α)·S″( , )=
α·γ· +
(1-α)·
谱聚类算法将数据样本用图G=(V,E)表示,其中V代表节点集合,E代表边集,边eij的权值用wij表示。本文相似图构造采用全连接方式,wij表示为
$w_{i j}=\left\{\begin{array}{l}\alpha \cdot \gamma \cdot S^{\prime}\left(\boldsymbol{x}_{i}^{(s)}, \boldsymbol{x}_{j}^{(s)}\right)+ \\\quad(1-\alpha) \cdot S^{\prime \prime}\left(\boldsymbol{x}_{i}^{(t)}, \boldsymbol{x}_{j}^{(t)}\right),(i, j) \in E, \\0,(i, j) \notin E 。\end{array}\right.$
由此构建出的混合型属性数据的相似度矩阵S为
$\begin{aligned}\boldsymbol{S}= & {\left[\alpha \cdot \gamma \cdot S^{\prime}\left(\boldsymbol{x}_{i}^{(s)}, \boldsymbol{x}_{j}^{(s)}\right)+\right.} \\& \left.(1-\alpha) \cdot S^{\prime \prime}\left(\boldsymbol{x}_{i}^{(t)}, \boldsymbol{x}_{j}^{(t)}\right)\right]_{n \times n \circ}\end{aligned}$
根据得到的相似度矩阵S,生成度矩阵D,由于本文的W=S,故得到的对称正则化拉普拉斯矩阵为
$\begin{aligned}\boldsymbol{L}_{\mathrm{sym}}= & \boldsymbol{D}^{-\frac{1}{2}} \boldsymbol{L} \boldsymbol{D}^{-\frac{1}{2}}=\boldsymbol{D}^{-\frac{1}{2}}(\boldsymbol{D}-\boldsymbol{S}) \boldsymbol{D}^{-\frac{1}{2}}= \\& \boldsymbol{I}-\boldsymbol{D}^{-\frac{1}{2}} \boldsymbol{S} \boldsymbol{D}^{-\frac{1}{2}}\end{aligned}$
针对本文形成的拉普拉斯矩阵,使用对称正则化的谱聚类进行聚类求解。聚类的目标函数为
$\min _{\operatorname{tr}} \operatorname{tr}\left(\boldsymbol{F}^{\mathrm{T}} \boldsymbol{L}_{\mathrm{sym}} \boldsymbol{F}\right) \text {, s. t. } \boldsymbol{F}^{\mathrm{T}} \boldsymbol{F}=\boldsymbol{I}$
式中:F∈Rn×k包含k个正交向量f1,f2,…,fk,fk∈Rn;Lsym为对称正则化的拉普拉斯矩阵。对于目标函数的求解,通过计算Lsym=D-1/2LD-1/2的前k个最小的特征值对应的特征向量所得到的结果即为最优解,之后使用k-means算法将得到的实值矩阵F转换为离散的簇指示矩阵,即可得到聚类结果。对于k值的选取,则依据传统的本征间隙法进行确定。
2.2 算法实现流程步骤
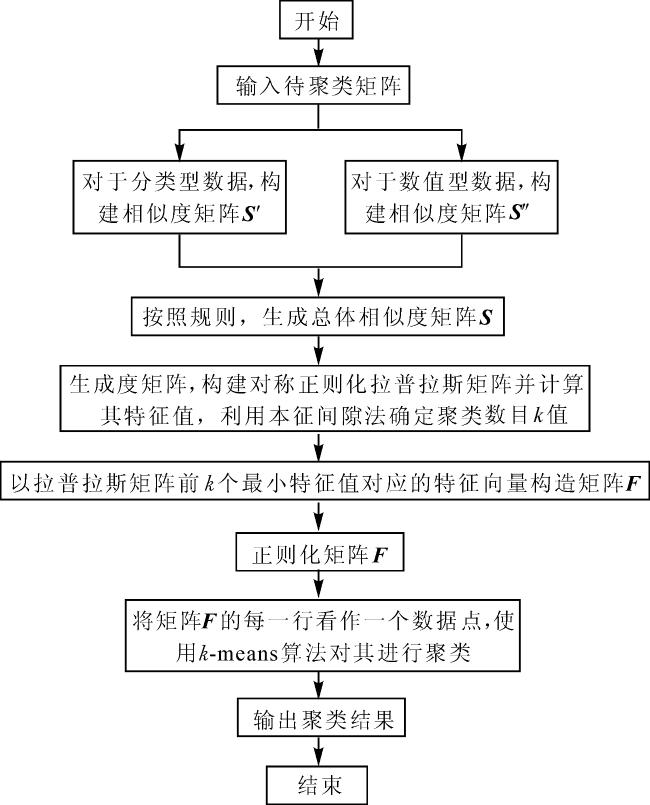
IJM-SC聚类算法具体实现流程如下:
1)输入待聚类的数据集X={x1,x2,…,xn}。
2)对于分类型数据利用改进的Jaccard相似度构建分类型数据的相似度矩阵S',对于数值型数据利用使用伪逆进行计算的马氏距离高斯核相似度构建数值型数据相似度矩阵S″。
3)根据分类型相似度矩阵和数值型相似度矩阵,按照本文给定的规则得到总体混合型属性数据的相似度矩阵S。
4)根据相似度矩阵S生成度矩阵D,构建拉普拉斯矩阵Lsym=I-D1/2SD-1/2,计算Lsym的特征值,利用本征间隙法,将第一个极大本征间隙出现的位置作为聚类簇数k值。
5)以Lsym的前k个最小的特征值对应的特征向量f1,f2,…,fk构造F∈Rn×k。
6)正则化矩阵F的每一行,使每一行元素平方和为1。
7)将矩阵F的每一行看作一个数据点,使用k-means算法对F进行聚类。
8)输出聚类结果。
算法实现流程图如图1所示。
2.3 算法时间复杂度分析
对于样本规模为n聚类簇数为k的数据集,IJM-SC算法的时间复杂由7部分组成:
1)构建分类型数据的相似度矩阵S';
2)构建数值型数据的相似度矩阵S″;
3)构建总体混合型数据的相似度矩阵S;
4)计算拉普拉斯矩阵Lsym的特征值;
5)构造特征向量矩阵F;
6)正则化矩阵F;
7)使用k-means算法进行聚类。
1)、2)、3)部分的时间复杂度均为O(n2),4)部分的时间复杂度为O(n3),5)部分的时间复杂度为O(k2),6)部分的时间复杂度为O(nk),7)部分的时间复杂度为O(nkid),i是迭代次数, d是数据维度。因此,本文谱聚类算法的时间复杂度为O(n3)。
3 心脏病数据集实验
心脏病是指心脏发生病变的疾病的总称,由心脏结构受损或功能异常引起,在全球范围内是发病率最高的危险疾病之一。
通常对于前来就诊的潜在心脏病患者,医生会根据自己的实践经验对其是否患有心脏病做出判断,而对于相对落后的地区,医生经验不足可能会导致无法给出准确判断,从而影响患者的及时就医或者发生误诊情况。随着科学技术的不断发展,医院的信息管理系统能获得个体的大量高价值问诊信息或诊断数据信息,便于医疗工作者使用机器学习的各种分类、聚类方法挖掘数据中潜在的价值规律,从而辅助医务人员做出判断决策,提高心脏病预测的准确度。
为验证本文构建的IJM-SC算法的合理性和有效性,实现对心脏病数据的聚类,提升心脏病预测诊断的准确度,本文采取同时具有数值型属性和分类型属性的心脏病数据集进行聚类实验,数据来源于UCI机器学习数据库[23],且该数据具有标签,可以将聚类得到的结果与真实标签结果进行对比来评估本文构建的算法的效果。
3.1 心脏病数据集实验过程
本文采取心脏病数据集中共270组数据进行聚类分析。数据集包含13个属性,其中有8个分类型属性,5个数值型属性。
首先,依据本文设计的IJM-SC算法的分类型数据的相似性度量公式(1)和实际的心脏病数据集中的分类型数据,构建分类型数据相似度矩阵S'具体过程使用Python实现,通过计算得到一个270×270的矩阵,截取该矩阵中的4×4部分如下:
。
接下来,根据数值型数据的相似性度量公式(2)构建数值型数据相似度矩阵S″。得到一个270×270的矩阵,截取该矩阵中的4×4部分如下:
。
根据公式(3)、(4)得到参数α、γ的值,保留4位小数分别为0.615 4、0.626 3, 按本文设计的总体数据相似性度量可得相似度矩阵,从而得到混合型属性数据所对应的拉普拉斯矩阵。计算拉普拉斯矩阵的特征值,依照从小到大的顺序,即矩阵D-1/2SD-1/2的特征值从大到小的顺序进行排列,部分特征值及该部分特征值的本征间隙值如表1所示。
表1 部分特征值及相应本征间隙值Tab.1 Part of the eigenvalues and corresponding eigengap values |
| 参数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 特征值 | 1.000 0 | 0.208 9 | 0.099 6 | 0.083 4 | 0.076 9 | 0.072 3 | 0.061 1 | 0.053 5 | 0.048 5 |
| 差值 | 0.791 1 | 0.109 3 | 0.016 2 | 0.006 5 | 0.004 6 | 0.011 2 | 0.007 6 | 0.005 0 |
根据本征间隙法由表1知k取值应为2, 这也符合该数据集的真实情况,即应被聚成患有心脏病和无心脏病2类。接下来取前2个特征值所对应的特征向量,形成F矩阵,并使用k-means作用于正则化后的F矩阵便得到了最终的聚类结果。
3.2 聚类效果评估指标
由于该心脏病数据集真实标签值是已知的,故使用准确率(ACC)值和调整兰德系数(ARI,记作IAR)值这两个评估指标对聚类效果进行评估。其中ACC计算公式[19]为
$ P(\Omega, C)=\frac{1}{n} \sum \max \left|\omega_{k} \cap C_{j}\right|$
式中:Ω={ω1,ω2,…,ωk}表示真实样本类别;ωk表示第k个类别中的全部真实样本;C={C1,C2,…,Ck}表示使用相应聚类算法聚类得到的簇;Cj表示聚类形成的第j个簇中的所有样本,ACC值是聚类正确的样本数目与总体样本数目的比值,最后得到的纯度值越高表明聚类效果越接近真实结果。
ARI计算公式[19]为
$ I_{\mathrm{AR}}=\frac{2(a d-b c)}{(a+b)(b+d)+(a+c)(c+d)}.$
式中:a为真实标签和聚类所得结果都属于同一类别的数据样本个数;b为真实标签属于同一类别而聚类得到结果不属于同一类别的数据样本个数;c表示真实标签不属于同一类别而聚类所得结果属于同一类别的数据样本数目;d表示真实标签和聚类所得结果都不属于同一类别的数据样本个数。ARI值通过计算数据样本位于同一类别和不同类别的个数来衡量真实标签和聚类所得结果之间的接近程度,取值范围为[-1,1],且值越大表明聚类结果越接近于真实标签结果,聚类效果越好。
3.3 心脏病数据集聚类结果
使用本文构建的IJM-SC聚类算法得到的心脏病数据聚类的评估指标结果如表下:ACC值为0.840 7,ARI值为0.462 4。
IJM-SC算法在构建完相似度矩阵后,得到混合型属性数据所对应的拉普拉斯矩阵并计算其特征值,确定聚类的簇数k, 以拉普拉斯矩阵前k个最小特征值对应的特征向量构造矩阵F, 对正则化后的F矩阵进行聚类。心脏病数据集利用正则化后的F矩阵进行可视化方法绘制真实聚类标签以及估计聚类标签的分布,绘制散点图如图2所示。
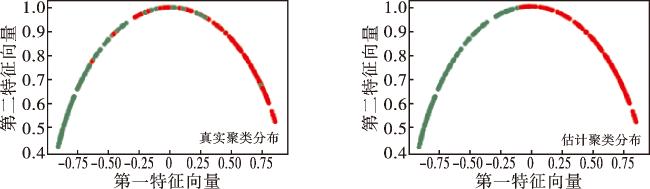
图2结果显示,心脏病数据集利用IJM-SC算法聚类成2簇时,真实的聚类标签分布与估计聚类标签分布大致相同,这表明IJM-SC算法能够大致捕捉到数据的真实分布情况。估计聚类标签的边缘部分与真实聚类标签的边缘部分稍有不同,反映出IJM-SC算法对边界数据点的估计精度不高。
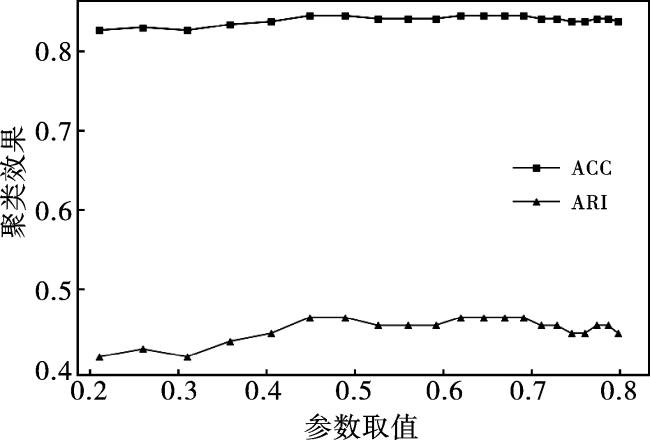
表2 心脏病数据集不同参数取值得到的结果值Tab.2 Result obtained from different parameter values on the heart dataset |
| σ取值 | γ取值 | ACC值 | ARI值 |
|---|---|---|---|
| 0.500 0 | 0.215 9 | 0.822 2 | 0.413 1 |
| 0.550 0 | 0.265 3 | 0.825 9 | 0.422 8 |
| 0.600 0 | 0.315 1 | 0.822 2 | 0.413 1 |
| 0.650 0 | 0.363 7 | 0.829 6 | 0.432 5 |
| 0.700 0 | 0.410 3 | 0.833 3 | 0.442 4 |
| 0.750 0 | 0.453 9 | 0.840 7 | 0.462 4 |
| 0.800 0 | 0.494 5 | 0.840 7 | 0.462 4 |
| 0.850 0 | 0.531 9 | 0.837 0 | 0.452 3 |
| 0.900 0 | 0.566 3 | 0.837 0 | 0.452 3 |
| 0.950 0 | 0.597 7 | 0.837 0 | 0.452 3 |
| 1.000 0 | 0.626 3 | 0.840 7 | 0.462 4 |
| 1.050 0 | 0.652 5 | 0.840 7 | 0.462 4 |
| 1.100 0 | 0.676 3 | 0.840 7 | 0.462 4 |
| 1.150 0 | 0.698 0 | 0.840 7 | 0.462 4 |
| 1.200 0 | 0.717 8 | 0.837 0 | 0.452 3 |
| 1.250 0 | 0.735 9 | 0.837 0 | 0.452 3 |
| 1.300 0 | 0.752 4 | 0.833 3 | 0.442 4 |
| 1.350 0 | 0.767 6 | 0.833 3 | 0.442 4 |
| 1.400 0 | 0.781 5 | 0.837 0 | 0.452 4 |
| 1.450 0 | 0.794 2 | 0.837 0 | 0.452 4 |
| 1.500 0 | 0.805 9 | 0.833 3 | 0.442 4 |
注:加粗表明本文采用的γ取值下效果最好。 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3.4 心脏病数据集实验对比与分析
表3实验结果揭示,在心脏病数据集上IJM-SC算法的ACC值比SBAC算法高出58.503 0%, 比SCBMDSM_1算法高出0.743 0%, 比SCBMDSM_2算法高出1.155 1%, 比EBSCMD算法高出0.888 0%, 比Kprototypes算法高出7.369 1%, 比OCIL算法高出13.439 5%, 比KL-FCM-GM算法高出6.068 6%。由此可见,本文构建的IJM-SC算法的聚类效果要好于其他7种算法,证明了本文算法在处理混合型属性数据时的有效性。
IJM-SC算法在心脏病数据上的实验结果与真实情况最为接近,能够有效地对心脏病患者进行分类和预测。IJM-SC算法的成功验证为心脏病预测诊断提供了新的思路和方法,有望成为未来医疗领域的重要辅助工具,帮助医务人员提高心脏病患者的诊断准确度和治疗效果。
4 两组信贷审批数据集实验
为了验证本文构建的IJM-SC算法的可扩展性和稳健性,将IJM-SC算法用于信贷审批数据集和澳大利亚信贷审批数据集上进行实验,数据来源于UCI机器学习数据库[23],详细的实验过程参见前文,只对实验结果进行分析。
4.1 信贷审批数据集实验结果分析
信贷审批数据集在去掉含有缺失值的样本后,对653个样本进行聚类分析,该数据集包含9个分类型属性、6个数值型属性和一个2分类标签。实验过程中选取的超参数值为1.30, 控制因子γ的值为0.743 9, 得到的评估指标结果如下:ACC值为0.825 4,ARI值为0.422 7。与其他7种算法进行对比实验得到的聚类结果如表4所示。
表4实验结果揭示,在信贷审批数据集上IJM-SC算法的ACC值比SBAC算法高出50.154 6%,比SCBMDSM_1算法高2.077 7%,比SCBMDSM_2算法高出4.454 6%,与EBSCMD算法持平, 比Kprototypes算法高2.956 2%, 比OCIL算法高24.419 7%,比KL-FCM-GM算法高39.567 1%。IJM-SC算法在该数据集上聚类效果与EBSCMD算法持平,优于其他6种算法,说明IJM-SC算法具有可行性,为处理信贷审批领域的应用提供了有利的支持和验证。
4.2 澳大利亚信贷审批数据集实验结果分析
对澳大利亚信贷审批数据集的690个样本进行聚类分析,该数据集合包含8个分类型属性、6个数值型属性和一个2分类标签。实验过程中选取的超参数 值为1.25, 控制因子 的值为0.726 1, 得到的评估指标结果如下:ACC值为0.834 8,ARI值为0.447 3。与其他7种算法实验得到的聚类结果对比如表5所示。
表5实验结果揭示,澳大利亚信贷审批数据集上,IJM-SC算法的ACC值比SBAC算法高61.376 4%,比SCBMDSM_1算法高3.792 1%, 比SCBMDSM_2算法高3.049 0%, 比EBSCMD算法高0.348 6%, 比Kprototypes算法高4.940 3%, 比OCIL算法高25.195 0%, 比KL-FCM-GM算法高0.348 6%。IJM-SC算法在该数据集上整体的聚类效果最好,与真实聚类情况最为接近,说明IJM-SC算法在信贷审批领域具有潜在的应用价值,能够为金融机构提供更准确和可靠的信贷决策支持。
5 结论
本文基于谱聚类算法的数学原理基础以及经典相似性度量的相关知识,通过合适的相似性度量设计,构建了IJM-SC算法。与现有的大多数利用谱聚类算法通过设计相似性度量对混合型属性数据聚类的算法相比,IJM-SC算法性能较好的原因在于:一方面该算法避免了分类型数据与数值型数据进行转换带来的信息损失,另一方面本文设计的相似性度量比较具有针对性,能够提高分类型数据的相似性度量精度、克服数值型数据量纲间差异较大以及数据多重线性相关带来的影响,且能合理地将分类型数据相似度矩阵与数值型数据相似度矩阵进行融合。
通过与经典的混合型属性数据聚类算法以及其他几种改进算法对比实验,本文构建的算法展现出了很好的聚类效果,达到了较高的ACC值,验证了本文算法的合理性、有效性和可扩展性,以及良好的鲁棒性。由于获得使用的数据集规模有限,未来在大规模数据集上如何缩减运行时间,将算法真正运用到实践中,还有待进一步探究。下一步,将进一步考虑数据相似性度量中参数的设计以及进行数据特征处理后聚类的研究,以达到更好的聚类效果。