

活性肽是源于蛋白质的多功能化合物,在抗感染、调节身体功能和神经递质等方面发挥着重要作用,鉴定这些具有治疗效果的活性肽有助于癌症、炎症和病毒性等疾病的治疗[1⇓⇓-4]。随着高通量测序技术和实验数据采集技术的发展,越来越多的多功能活性肽被鉴定出来[5⇓-7]。多功能活性肽可以影响不同靶标来传递多种生理效果,对不同的疾病都有治疗效果,已成为肽类药物开发的重点[8]。传统湿实验鉴定活性肽的方法耗时耗力,需要对活性肽测序、设计体外实验和体内实验等,无法满足日益增长的活性肽鉴定需求[9]。研究表明,通过基于序列的计算方法辅助识别多功能活性肽,有助于对大规模多功能活性肽的鉴定[10-11]。因此,基于计算方法辅助鉴定多功能活性肽是必要的,有助于多功能活性肽的鉴定和肽类药物的开发,同时为临床研究提供参考价值。
深度学习方法不需要研究人员手动选择特征,可以直接将肽序列作为输入用于模型的训练和预测,已广泛用于预测活性肽。Tang等[10]提出了一种基于卷积神经网络(convolutional neural network,CNN)和双向门控循环单元(bidirectional gated recurrent unit,Bi-GRU)的深度学习方法MLBP,将活性肽序列作为模型的特征输入,用于预测多功能活性肽;Li等[11]提出基于多分支CNN和双向长短期记忆网络(bidirectional long short-term memory,Bi-LSTM)的深度学习方法MPMABP,将活性肽序列作为模型特征输入,用于预测多功能活性肽。上述方法构建基于深度学习方法的多功能活性肽预测模型,直接将肽序列作为模型的特征输入来训练和预测模型,提高了研究人员对多功能活性肽的鉴定效率。然而,上述研究将肽序列作为模型的特征输入时,忽略了活性肽序列中氨基酸之间的关联性,这些关联性可以更好地表征活性肽序列,从而提高模型对肽序列特征的表征能力[12]。Transformer编码器由位置编码、多头自注意力机制等组成,可以有效提取活性肽序列中氨基酸之间的关联性。Ma等[13]提出了一种基于Transformer和动态路由的穿透肽预测模型,结果表明通过Transformer编码器提取氨基酸之间的关联性有效地提高了穿透肽的预测准确率;Cheng等[14]提出一种基于端到端Transformer的孪生网络检测方法PepFormer,结果表明采用Transformer编码器提取氨基酸之间的关联性可以提高肽的可检测性。因此,本文引入Transformer编码器来提取活性肽序列中氨基酸之间的关联性,将活性肽序列作为特征输入Transformer编码器来捕获上下文信息,用于提高模型对肽序列的表征能力,从而提高模型对活性肽序列特征的学习能力。
在用于鉴定活性肽的深度学习模型中,常使用CNN和循环神经网络(recurrent neural network,RNN)来提取活性肽序列的局部特征和全局特征,通过级联这两种网络可以提高模型的预测性能[10-11]。CNN和RNN之间通常会加入池化层,用于减少模型的参数数量,并防止过拟合等问题[15]。Yan等[16]提出了一种基于多头自注意力机制和类别权重优化算法的深度学习模型PrMFTP,利用CNN、最大池化(Max Pooling)和RNN来学习局部特征和全局特征,用于预测多功能活性肽。Lv等[17]提出了一种具有深度表示学习特征的抗癌肽预测模型,通过RNN结合平均池化(Average Pooling)来学习肽序列特征,用于预测抗癌肽。研究表明,池化层虽然可以减少模型的参数数量,但也可能会在池化的过程中损失重要的信息[15]。最大池化用于提取局部区域内的最大特征值,但会忽略背景、平滑区域等信息的提取;平均池化可以平滑局部区域内的特征值,但会忽略纹理、边缘等信息的提取。Yu等[18]为解决最大池化和平均池化存在的不足,提出一种混合池化(Mix Pooling)用于兼顾最大池化和平均池化对不同区域信息的提取,不仅可以减少模型参数数量,还可以保留更多区域的特征信息。因此,本文引入混合池化来构建特征提取网络,通过在CNN和RNN之间加入混合池化,在减少模型参数数量的同时,最大程度上保留和提取局部特征和全局特征,用于提高模型对肽序列的特征提取能力。
预测多功能活性肽是多标签分类问题,而根据对多标签分类任务的不同处理方式,需要设计不同的损失函数来进行模型的反向传播[20]。已有多功能活性肽研究中,大多是利用交叉熵损失函数(cross entropy loss,CEL)将多标签分类任务转换为多个独立的二元分类任务,并通过手动设置阈值来获得标签或直接输出排名靠前分数的类别作为目标标签[10-11]。然而,这种转换方式忽略了多标签分类问题中各标签之间的潜在依赖性,并且这种二阶段预测法增加了模型的复杂性和训练的不稳定性[19]。研究表明,多功能活性肽的功能之间存在依赖性,即存在标签之间的潜在依赖性,通过捕获这些潜在依赖性可以提高模型的预测精度[16]。Su等[21]为解决多标签分类中标签依赖性等问题,通过结合二元相关性和标签排序的优点,提出了一种ZLPR(zero-bounded log-sum-exp & pairwise rank-based,ZLPR) 损失,用于更好地捕获标签依赖性和自适应地确定目标类别的数量,并且通过这种损失可以直接得到目标标签。因此,本文引入ZLPR 损失函数来捕获多功能活性肽多个功能之间潜在的标签依赖性,用于提高模型的预测性能。此外,模型通过ZLPR 损失可以直接输出预测分数,进一步降低了模型的复杂度。
本文提出了一种基于标签依赖性的多功能活性肽预测模型TCLD(Transformer、CNN、LSTM、DNN),模型结构如图1所示。该模型将活性肽序列转换为数字序列后输入Transformer编码器,通过学习氨基酸之间的关联性来强化模型对活性肽序列的特征表示能力,再通过由多尺度CNN、Mix pooling和Bi-LSTM构建的多尺度特征网络(multi-scale feature network, MSFN)来提取活性肽序列的局部特征和全局特征,引入密集Dropout块防止模型过拟合,并引入了ZLPR损失函数来捕获活性肽多个功能之间对应的标签依赖性,最后通过全连接层输出预测分数。为了验证TCLD的预测性能,本文将原始数据划分为训练集和测试集,并通过与其他方法进行对比。实验结果表明,TCLD在预测多功能活性肽的性能上优于现有方法。
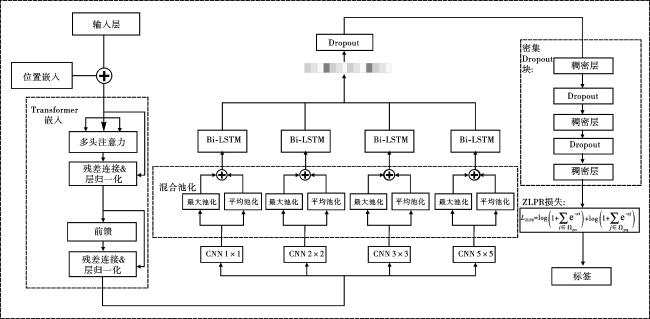
1 数据与方法
1.1 数据集及数据预处理
本文实验选择短肽和长肽两个数据集进行模型的训练和测试,长肽数据集来源于文献[10],该数据集包含5种功能的活性肽,肽段长度在5~517个残基;短肽数据集来源于文献[16],该数据集解决了长肽数据集中存在活性肽种类较少和序列长度差异过大等问题,包含21种功能的活性肽,肽段长度在5~50个残基。为了避免每类肽中重复的冗余序列,使用CD-HIT删除数据集中具有90%序列相似性的肽。经过CD-HIT处理后,结合数据集为活性肽分配多标签功能,并获得基准数据集。短肽基准数据集中,8 415个肽具有1种功能,981个肽具有2种不同功能,329个肽具有3种不同功能,91个肽具有4种不同功能,31个肽具有5种不同功能,27个肽具有5种以上不同功能。长肽基准数据集中,6 150个肽具有1种功能,198个肽具有2种不同功能,基准数据集中肽段分布如表1所示。
表1 各类活性肽分布信息表Tab.1 Dataset of various active peptides |
| 短肽数据集 | 长肽数据集 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 类型 | 数量 | 类型 | 数量 | 类型 | 数量 | 类型 | 数量 | ||||||||
| AAP | 135 | AHIVP | 109 | BBP | 119 | AMP | 2 409 | ||||||||
| ABP | 2 469 | AHP | 948 | BIP | 339 | ACP | 646 | ||||||||
| ACP | 1 052 | AIP | 2 049 | CPP | 462 | ADP | 514 | ||||||||
| ACVP | 137 | AMRSAP | 173 | DPPIP | 313 | AHP | 868 | ||||||||
| ADP | 509 | APP | 319 | QSP | 220 | AIP | 1 678 | ||||||||
| AEP | 70 | ATP | 246 | SBP | 104 | ||||||||||
| AFP | 2 324 | AVP | 736 | THP | 651 | ||||||||||
为了评估本文模型TCLD在多功能活性肽上的预测性能,本文在短肽数据集上选择了具有代表性的4种对比方法,这些方法均选择80%的活性肽样本用作训练数据集,其余20%样本作为独立测试集。在实验过程中为确保与其他方法比较的公平性,本文采用与对比方法相同的划分方式进行模型的训练和性能比较。本文模型和对比模型均在同一训练集上进行模型训练,并在同一测试集上进行独立测试。
1.2 Transformer编码器
本文所使用数据集中的肽段采用大写的英文字母表示,短肽数据集中肽段长度从5个残基到50个残基不等,长肽数据集中肽段长度从5个残基到517个残基不等。由于模型的输入需要统一长度的肽向量,本文采取将各数据集中小于最长序列残基数的肽段使用特定字符“X”在末端填充,采用One-of-21编码方式对肽段序列进行编码。
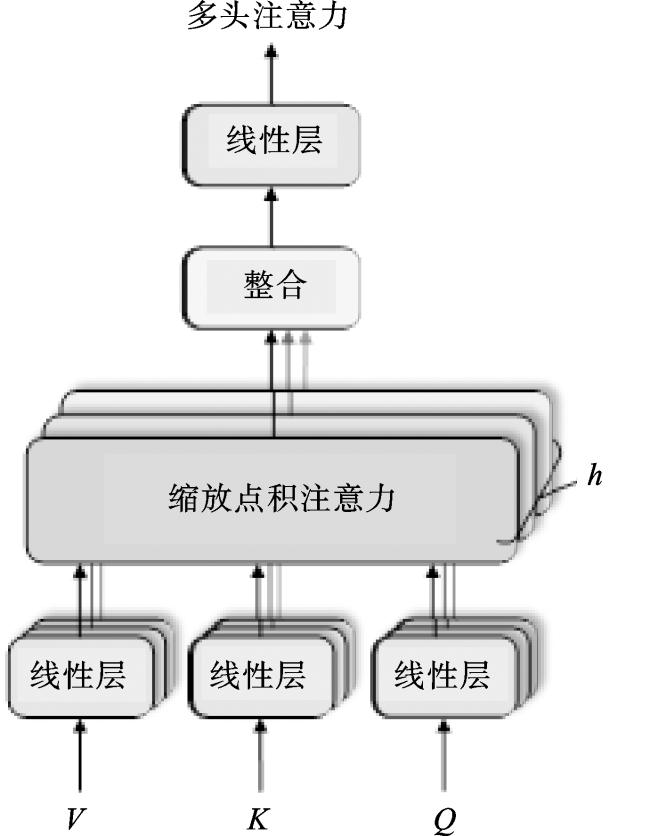
氨基酸与氨基酸之间存在较强的关联性,主要体现在氨基酸之间的相互作用和排列顺序,这些关联性可以影响活性肽与靶标的结合能力和功能作用。本文引入Transformer编码器提取氨基酸之间的关联性,用于强化模型对活性肽序列的特征编码,从而提高模型的特征表示能力。Transformer编码器的核心为多头注意力(multi-head attention)机制,如图2所示。多头注意力中的每个注意力头都能独立学习并关注活性肽序列的不同语义信息,通过整合来自不同注意力头的信息,可以得到全面且丰富的注意力表示,有助于模型在处理复杂任务时做出更准确的决策。通过多头注意力机制,模型能够聚焦于对活性肽功能或靶标结合起关键作用的氨基酸,进而提高其预测准确性。
1.3 多尺度特征网络
为进一步提取活性肽序列特征,本文构建多尺度特征网络(multi-scale feature network, MSFN)作为本模型的特征提取主干网络,如图3所示。
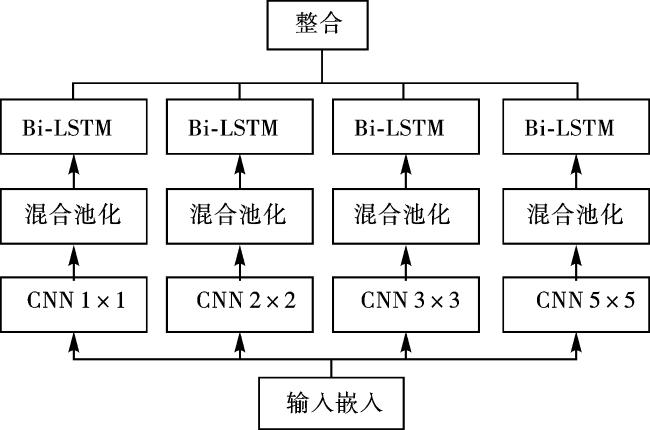
本文使用大小为1、2、3和5的卷积核并行提取活性肽序列多种尺度的特征,帮助模型全面分析和提取活性肽序列特征。在多尺度特征网络MSFN中,CNN单元为一维卷积网络(1D-CNN),包含一个卷积层、一个ReLU层和两个池化层。现有方法使用最大池化对特征进行降维操作,用于减少模型参数数量。最大池化本质是从特定区域内选择最大的特征值,但一些非局部最大值也可能包含对预测功能至关重要的信息。为解决单一池化方法存在的问题,本文结合最大池化和平均池化提出混合池化方法,在减少模型参数的同时最大程度地保留活性肽特征信息。考虑到不同氨基酸之间的顺序相关性,本文采用Bi-LSTM进一步提取活性肽序列中氨基酸之间的长距离依赖信息,用于增强活性肽序列特征学习过程中的信息流。
1.4 ZLPR损失
现有的多功能活性肽预测方法利用Sigmoid激活函数将多标签分类转换为多个二分类问题,并使用二分类的交叉熵之和作为损失。然而,这种做法忽略了标签之间的关联,还可能会面临着严重的类别不均衡问题,并且需要根据验证集来进一步确定最优的阈值。为解决上述问题,Su等[21]提出一种ZLPR 损失,如公式(1)所示。通过引入一个额外的0类,让目标类的分数尽可能都大于s0,非目标类的分数都小于s0,即得到交叉熵函数在多标签分类任务中的推广。
$\log \left(\mathrm{e}^{-s_{0}}+\sum_{i \in \Omega_{\text {pos }}} \mathrm{e}^{-s_{i}}\right)+\log \left(\mathrm{e}^{s_{0}}+\sum_{j \in \Omega_{\text {neg }}} \mathrm{e}^{s_{j}}\right).$
当指定阈值为0时,上式简化为公式(2):
$L_{\mathrm{LLZPR}}=\log \left(1+\sum_{i \in \Omega_{\mathrm{pos}}} \mathrm{e}^{-s_{i}}\right)+\log \left(1+\sum_{j \in \Omega_{\text {neg }}} \mathrm{e}^{s_{j}}\right).$
式中:si、sj代表目标类别和非目标类别的得分;Ωpos和Ωneg代表样本的正负类别集合。
多标签分类问题中不仅存在特征和目标标签之间的依赖性,也存在标签与标签之间的依赖性。当损失函数在最小化经验风险过程中依赖于多个标签之间的联合分布信息时,意味着这种损失可以捕获标签依赖性[20]。ZLPR损失函数经验风险的梯度表示如公式(3)所示。
$\begin{aligned}\frac{\partial R_{\text {ZLPR }}}{\partial s} & =E_{\boldsymbol{y} \sim P(\boldsymbol{y} \mid x)}\left[-\frac{\boldsymbol{y} \odot \mathrm{e}^{-s}}{1+\left\langle\boldsymbol{y}, \mathrm{e}^{-s}\right\rangle}+\right. \\& \left.\frac{(1-\boldsymbol{y}) \odot \mathrm{e}^{s}}{1+\left\langle 1-\boldsymbol{y}, \mathrm{e}^{s}\right\rangle}\right].\end{aligned}$
式中:P(y|x)表示随机变量y在给定条件x下的概率分布;s是分类模型输出的原始分数;<·,·>表示内积运算;☉是Hadamard乘积算子。
将梯度设为零时,对于所有的时间步t∈{1,2,…,L},有
$s_{t}=\frac{1}{2} \underbrace{\log \frac{P\left(y^{(t)}=1 \mid x\right)}{P\left(y^{(t)}=0 \mid x\right)}}_{T_{1}}+\frac{1}{2} \underbrace{\log \frac{E_{\tilde{y}^{(t)}}^{(t)} \sim P\left(\tilde{y}^{(t)} \mid y_{=1, x}^{(t)}\right)\left[\varphi_{1}\left(s, \tilde{y}^{(t)}\right]\right.}{E_{\tilde{y}^{(t)} \sim P\left(\tilde{y}^{(t)} \mid y_{=0, x}^{(t)}\right)}\left[\varphi_{0}\left(s, \tilde{y}^{(t)}\right)\right]}}_{T_{2}}.$
式中:y(t)∈{0, 1}表示类别的二元状态变量; 表示其他类别的状态变量集合;在公式(4)的右侧,T1是对应类别的边界预测值;T2是依赖耦合项。
1.5 评估指标
本文使用五折交叉验证和独立测试集验证测试模型在基准数据集上的性能,本文提出的多标签分类模型通过精度(precision,记作Pr)、覆盖率(coverage,记作Cv)、准确率(accuracy,记作Ac)、绝对真(absolute true,记作At)、绝对假(absolute false,记作Af)来评估性能,其中准确率、绝对准确率是最重要的指标[24]。这些评估指标广泛应用于各种多标签分类模型的性能评估,其数学描述如下:
$P_{\mathrm{r}}=\frac{1}{N} \sum_{i=1}^{N} \frac{\left\|L_{i} \bigcap L_{i}^{*}\right\|}{\left\|L_{i}^{*}\right\|}$
$C_{\mathrm{v}}=\frac{1}{N} \sum_{i=1}^{N} \frac{\left\|L_{i} \cap L_{i}^{*}\right\|}{\left\|L_{i}\right\|},$
$A_{\mathrm{c}}=\frac{1}{N} \sum_{i=1}^{N} \frac{\left\|L_{i} \cap L_{i}^{*}\right\|}{\left\|L_{i} \bigcup L_{i}^{*}\right\|},$
$A_{\mathrm{t}}=\frac{1}{N} \sum_{i=1}^{N} \Delta\left(L_{i}, L_{i}^{*}\right)$
$A_{\mathrm{f}}=\sum_{i=1}^{N} \frac{\left\|L_{i} \cup L_{i}^{*}\right\|-\left\|L_{i} \cap L_{i}^{*}\right\|}{M}$
式中:N为多功能生物活性肽的总数;M表示低冗余数据集的功能类型;∪表示集合论中的并集;∩表示集合论中的交集;‖‖表示计算元素数量;Li表示第i个样本的真实标签子集; 表示第i个样本的预测标签子集。
1.6 模型训练
本文的预测模型是使用Tensorflow 2.5.0和Keras 2.5.4 实现的,通过五折交叉验证来调整训练集上的超参数,最后以批处理大小batch size=192和迭代次数epochs=200来训练模型。本文采用密集dropout块防止模型过拟合,将dropout率和学习率分别设置为0.5和0.001 5。
2 实验结果与讨论
2.1 模型各模块及参数选择
2.1.1 TCLD模型各模块的选择
对于预测多功能活性肽,自注意力机制可以有效提取和优化序列中氨基酸之间的相关信息,而多尺度CNN和RNN可以分别提取不同距离序列中的局部特征和全局特征。本文基于Transformer编码器、CNN和RNN作为基础模块,提出了4种不同的多功能活性肽预测模型:1)多尺度CNN+Bi-GRU;2)多尺度CNN+Bi-LSTM;3)Transformer编码器+多尺度CNN+Bi-GRU;4)Transformer编码器+多尺度CNN+Bi-LSTM。这些模型在短肽训练集上进行五折交叉验证实验,其实验结果如图4所示。
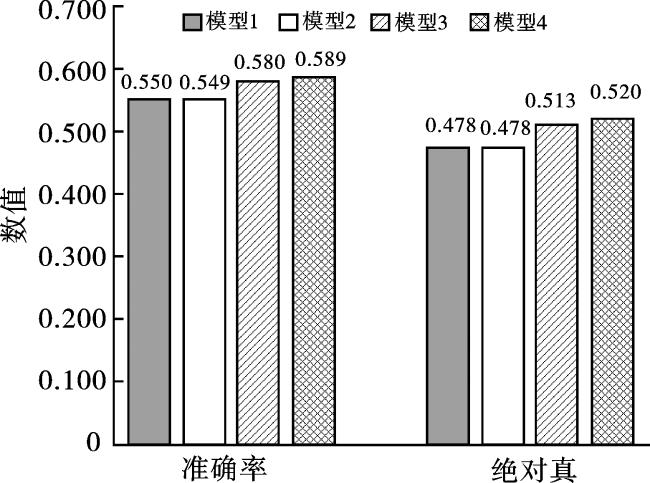
本文实验采用的指标中,Accuracy和Absolute true为最重要的参考指标,分别代表模型对活性肽标签识别的准确率和绝对真(多标签分类问题中,对样本具有的标签多预测或少预测都不算正确)。 从图4可以观察到Transformer 编码器+多尺度CNN+Bi-LSTM模型的Accuracy和Absolute true值分别为58.9%和52.0%,均优于其他模型。本文利用Transformer编码器强化活性肽序列特征编码,其核心是多头注意力机制,该机制允许模型在处理输入序列时,将注意力同时集中在多个不同的位置上,从而提取到氨基酸之间的相关信息。因此,可以从图4中发现,采用Transformer编码器的模型结果表现更好。此外,也可以观察到当使用Transformer编码器时,采用Bi-LSTM的模型比采用Bi-GRU的模型性能好。GRU和LSTM都是带有门控机制的RNN算法,LSTM具有3个门机制(输入门、遗忘门和输出门),而GRU只有2个门机制(更新门和重置门)。虽然Bi-GRU具有更快的收敛运行时间,但是Bi-LSTM机制更复杂,可以学习到更丰富的信息。综上所述,我们选择综合性能最好的Transformer + 多尺度CNN+ Bi-LSTM模型来构建多功能活性肽预测模型。
本文采用的Transformer编码器由位置编码、多头注意力机制和前馈网络组成,本文对前馈网络中全连接层的激活函数选择包括:ReLU和GELU。本文基于这两种激活函数构建了两种不同的多功能活性肽预测模型,其在短肽训练集上进行五折交叉验证的实验结果如表2所示。综上所述,本文选择结果表现更好的GELU作为前馈网络中全连接层的激活函数。
表2 不同激活函数对模型的性能影响Tab.2 The impact of different activation functions on the performance of the model |
| 激活函数 | 精度 | 覆盖率 | 准确率 | 绝对真 | 绝对假 |
|---|---|---|---|---|---|
| ReLU | 0.629 | 0.620 | 0.586 | 0.516 | 0.042 |
| GELU | 0.634 | 0.622 | 0.589 | 0.520 | 0.042 |
注:加粗表明最优。 |
2.1.2 基于不同池化方法的多尺度特征网络
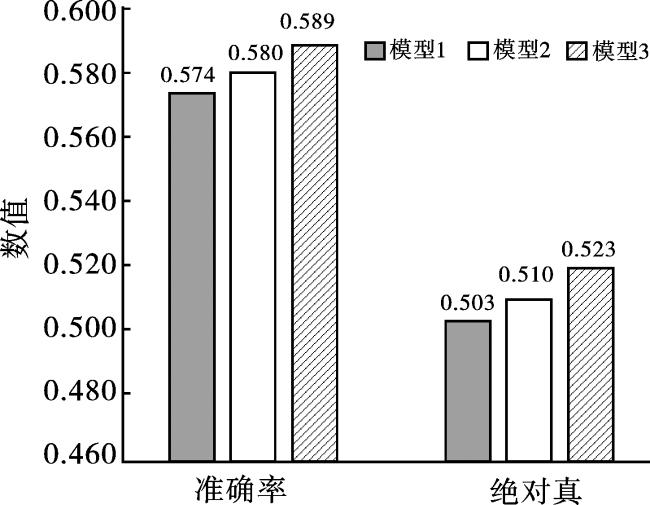
本文对于活性肽的序列编码层选择Transformer编码器,对于特征提取网络的构建选择多尺度CNN+池化+ Bi-LSTM。基于多尺度CNN、Bi-LSTM和不同的池化方式,本文提出了3种不同的特征提取网络:1)多尺度CNN+Average Pooling+ Bi-LSTM;2)多尺度CNN+ Max Pooling + Bi-LSTM;3)多尺度CNN+ Mix Pooling + Bi-LSTM。这些模型在短肽训练集上进行五折交叉验证实验,其实验结果如图5所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
从图5可以观察到,多尺度CNN+Mix Pooling+Bi-LSTM特征提取网络的准确率和绝对真分别为58.9%和52.0%,均优于其他模型。结果表明,通过Mix Pooling可以提高模型对活性肽序列特征的提取能力,提高了多功能活性肽预测模型的性能。因此,本文选择综合性能最好的多尺度CNN+ Mix Pooling+ Bi-LSTM模型来构建多尺度特征网络。
2.1.3 不同损失函数对模型性能的影响
本文引入ZLPR 损失函数,该损失函数可以捕获更好的标签依赖性和自适应地确定目标类别的数量,用于提高模型对多功能活性肽的预测精度。为了评估ZLPR 对多功能活性肽预测性能的影响,本文选择了在分类问题中广泛使用且性能较好的2种损失函数CEL和FL(focal loss,FL)代替ZLPR分别构建TCLD变体模型。CEL是衡量2个概率分布之间差异的常用方法,在分类问题中广泛使用,现有多功能活性肽预测模型大多利用CEL将多标签分类问题转换为多个二元分类问题;FL损失函数是CEL的改进版,通过引入2个可调节的参数(通常表示为α和γ),能够动态地调整每个样本在训练过程中的权重,使得模型对于难以分类的样本给予更多的关注。由于短肽数据集中活性肽种类更多,且类别不平衡更明显,我们选择在短肽数据集上进行五折交叉验证实验,实验结果如表3所示。
表3 不同损失函数的性能对比Tab.3 Comparison of the performance of different loss functions |
| 损失函数 | 精度 | 覆盖率 | 准确率 | 绝对真 | 绝对假 |
|---|---|---|---|---|---|
| CEL | 0.579 | 0.549 | 0.530 | 0.471 | 0.044 |
| FL | 0.620 | 0.590 | 0.574 | 0.520 | 0.039 |
| ZLPR | 0.634 | 0.622 | 0.589 | 0.520 | 0.042 |
注:加粗表明最优。 |
从表3中可以看出,采用CEL损失函数模型的各项指标最差,这是因为CEL损失函数将多标签分类问题转换为多个二分类问题,虽然简化了多标签分类问题的难度,但它不直接解决类别不平衡的问题,会导致模型对于多数类别产生偏向,从而忽视少数类别,导致模型性能受到限制。采用FL损失函数的模型精度、覆盖率、准确率和绝对真值相较于CEL损失函数分别提高了4.1%、4.1%、4.4%和4.9%,这是因为FL损失函数通过调节因子来重点关注难以分类的样本,有助于模型在处理复杂或边缘情况时的性能提升,但FL损失的调节因子需要先验知识或实验调整,会增加模型性能的不确定性,且FL损失不直接捕获标签依赖性。相比之下,ZLPR损失函数通过比较目标类别得分与非目标类别得分来自动平衡权重,无需任何先验知识,并且可以捕获活性肽多个功能之间的标签依赖性,有效提高了多功能活性肽预测模型的预测性能。
2.1.4 模型参数的选择
本文采用网格搜索程序通过五折交叉验证来选择多功能活性肽预测模型的超参数,这些参数包括:Transformer编码器嵌入维度、卷积核数量、池化大小、Bi-LSTM单元、学习率、批处理大小(batch size)和迭代次数(epochs),详细参数如表4所示。由于深度学习框架中的随机初始化,本文并行训练多个具有不同随机初始化的相同模型,通过对所有模型的分数进行平均来获得测试样本的最终预测分数。
表4 模型详细超参数Tab.4 Model detailed hyperparameters |
| 模块 | 参数 | 参数范围 | 最优 |
|---|---|---|---|
| Transformer | 嵌入维度 | [64,128,192] | 192 |
| CNN | 池化大小 | [4,5,6] | 5 |
| 卷积核大小 | [32,64,128] | 64 | |
| Bi-LSTM | Bi-LSTM单元大小 | [50,100] | 50 |
| Training module | 学习率 | (0.001,0.01) | 0.001 5 |
| 迭代次数 | [150,200,250] | 200 | |
| 批处理大小 | [64,128,192] | 192 |
2.2 消融实验
多功能活性肽预测模型的构建包括:Transformer编码器,负责提取活性肽序列中氨基酸之间的关联信息;多尺度特征网络MSFN,在Transformer编码器提取的初步特征基础上进一步提取高级特征;密集Dropout块,用于防止模型在训练数据上过拟合;ZLPR损失函数,用于捕获活性肽多个功能之间对应的标签依赖性。为了验证这些模块是否有助于多功能活性肽的预测,本文基于这些模块在短肽数据集上设计了消融实验,None Transformer表示移除Transformer编码器,以验证该模块对提取氨基酸之间关联信息的重要性;None MSFN表示移除多尺度特征网络,以评估该网络对提取高级特征和模型性能的影响;None Dropout表示移除密集Dropout块,以观察模型在没有该正则化技术时的表现;None ZLPR表示移除ZLPR损失函数,以探究其对模型预测多功能活性肽准确性的影响。消融实验结果如表5所示。
表5 消融实验结果对比Tab.5 Comparison of ablation experimental results |
| 模型 | 精度 | 覆盖率 | 准确率 | 绝对真 | 绝对假 |
|---|---|---|---|---|---|
| TCLD | 0.731 | 0.724 | 0.689 | 0.620 | 0.032 |
| None Transformer | 0.727 | 0.724 | 0.685 | 0.611 | 0.033 |
| None MSFN | 0.687 | 0.671 | 0.640 | 0.570 | 0.036 |
| None Dropout | 0.727 | 0.716 | 0.681 | 0.609 | 0.032 |
| None ZLPR | 0.712 | 0.699 | 0.666 | 0.596 | 0.032 |
注:加粗表明最优。 |
从表5可以看出,删除TCLD中的任何模块都会导致模型预测性能下降。None MCFN模型的性能下降最明显,准确率和绝对真分别下降4.9%和5.0%,这是由于MSFN作为TCLD的基础特征提取网络,对于活性肽序列特征的提取至关重要,缺少它会直接影响模型的特征提取能力,进而显著降低预测准确性。None ZLPR模型的准确率和绝对真分别下降2.3%和2.4%,这是由于ZLPR损失函数有助于捕获活性肽多个功能之间对应的标签依赖性,缺少它将会影响模型预测多功能活性肽的能力。None Dropout模型的准确率和绝对真分别下降0.8%和1.1%,表明缺失Dropout块会减弱模型对新数据的泛化能力。None Transformer模型的准确率和绝对真分别下降0.4%和0.9%,表明Transformer编码器能够强化活性肽序列的特征编码,移除它会导致模型在理解氨基酸序列关联信息方面的能力下降。综上所述,通过结合Transformer编码器、多尺度特征网络、密集Dropout块和ZLPR损失函数可以提高模型预测多功能活性肽的能力,否则将会导致TCLD模型预测性能下降。
2.3 与现有方法的性能比较
为了评估本文模型TCLD对多功能活性肽的预测性能,在短肽数据集上选取了4种具有代表性的方法进行比较:MLBP[10]、MPMABP[11]、PrMFTP[16]和ETFC[25]。MLBP和MPMABP是最早被提出用于预测多功能活性肽的方法,常作为基准对照方法来比较和评估新的模型。PrMFTP和ETFC是基于短肽研究构建的多功能活性肽预测方法,PrMFTP采用多尺度CNN、Bi-LSTM和注意力机制构建多功能活性肽预测模型,在Bi-LSTM输出特征之后引入注意力机制提取关键特征,用于提高预测准确性;ETFC则是采用多尺度CNN、注意力机制和焦点骰子损失函数构建多功能活性肽预测模型,利用焦点骰子损失函数解决类别不平衡问题,使得模型在训练过程中更加关注少数类别的样本,从而提高模型的预测性能。本文将短肽数据集中80%的活性肽样本用作训练数据集,其余20%样本作为独立测试集,并将本文模型和对比模型在同一训练集上进行训练,使用相同的测试集对模型进行评估,实验结果如表6所示。
表6 在短肽数据集上与其他方法对比结果Tab.6 Results were compared with other methods on short peptide datasets |
| 模型 | 精度 | 覆盖率 | 准确率 | 绝对真 | 绝对假 |
|---|---|---|---|---|---|
| MPMABP | 0.477 | 0.444 | 0.430 | 0.381 | 0.041 |
| MLBP | 0.549 | 0.498 | 0.493 | 0.446 | 0.037 |
| PrMFTP | 0.699 | 0.669 | 0.651 | 0.593 | 0.031 |
| ETFC | 0.724 | 0.717 | 0.684 | 0.617 | 0.036 |
| TCLD | 0.731 | 0.724 | 0.689 | 0.620 | 0.032 |
注:加粗表明最优。 |
从表6中可以看出,在短肽数据集上相较于其他预测方法,本文模型TCLD的精度、覆盖率、准确率和绝对真值分别为73.1%、72.4%、68.9%和52.0%,均优于其他方法。其中,MPMABP和MLBP采用将活性肽序列特征直接输入特征提取网络中,PrMFTP在特征提取网络后引入自注意力层来保留重要的特征信息,这些模型都忽略了活性肽序列中氨基酸之间的关联性,导致模型预测性能降低;ETFC引入焦点骰子损失函数平衡类别权重,但在分类预测时采用了二阶段法,导致需要人工设置阈值,增加了模型的复杂度。综上所述,在短肽数据集上的对比实验表明了本文模型TCLD对多功能活性肽的预测性能优于现有模型。
为进一步验证本方法的泛化性和健壮性,以及探讨机器学习方法在多功能活性肽预测问题上的表现,在长肽数据集选择了7种对比方法:MLBP[10]、MPMABP[11]、SCN-MLTPP[26]、CLR[27]、RAKEL[28]、RBRL[29]和MLDF[30],其中,CLR、RAKEL、RBRL和MLDF为传统机器学习方法。由于目前多功能活性肽预测研究均采用深度学习方法,本文选择了在多标签分类问题上性能表现良好的CLR、RAKEL、RBRL和MLDF作为对比方法,CLR和RAKEL采用将多标签分类问题转换为多个二分类问题的策略,RBRL采用标签排序的策略,MLDF利用深度深林进行多标签分类。SCN-MLTPP是最新针对长肽研究的多功能活性肽预测模型,其利用活性肽的理化性质作为特征输入,使用堆叠胶囊网络提取活性肽理化性质与其功能之间的关系,实现对多功能活性肽的准确预测。本文将上述模型在长肽训练集上进行训练,并使用长肽测试集对模型进行评估,实验结果如表7所示。
表7 在长肽数据集上与其他方法对比结果Tab.7 Results were compared with other methods on long peptide dataset |
| 模型 | 精度 | 覆盖率 | 准确率 | 绝对真 | 绝对假 |
|---|---|---|---|---|---|
| MLDF | 0.649 | 0.649 | 0.648 | 0.646 | 0.119 |
| RAKEL | 0.649 | 0.648 | 0.648 | 0.647 | 0.141 |
| RBRL | 0.650 | 0.651 | 0.649 | 0.646 | 0.140 |
| CLR | 0.667 | 0.677 | 0.666 | 0.655 | 0.133 |
| MLBP | 0.710 | 0.720 | 0.709 | 0.697 | 0.106 |
| MPMABP | 0.728 | 0.749 | 0.727 | 0.704 | 0.101 |
| SCN-MLTPP | 0.747 | 0.753 | 0.736 | 0.707 | 0.095 |
| TCLD | 0.749 | 0.745 | 0.739 | 0.727 | 0.095 |
注:加粗表明最优。 |
从表7中可以看出,集成深度学习模型预测效果显著优于MLDF、RAKEL、RBRL和CLR机器学习多标签分类模型,这是因为深度学习模型通常包含大量参数和非线性激活函数,使其能够建模高度非线性的数据关系,处理复杂的数据模式和结构时具有优势。本文模型TCLD的Precision、Accuracy和Absolute true值分别为74.9%、73.9%和72.7%,均优于其他模型,但Coverage低于SCN-MLTPP 和MPMABP,这是因为Precision和Coverage具有一定的负相关性[24]。SCN-MLTPP利用活性肽理化特征编码作为模型输入来提高模型的表征能力,然而在分类预测时同样采用了二阶段法,导致模型复杂度增加。综上所述,在短肽和长肽数据集上的对比实验都表明了本文模型TCLD在多功能活性肽预测问题上的性能优于现有模型。
3 结语
为了解决多功能活性肽预测问题,本文提出了基于深度学习的TCLD模型。这是一种基于标签依赖性的多功能活性肽预测模型,用于识别具有多种功能的活性肽。与最新的方法相比,本方法做出了三个改进:利用Transformer编码器提取活性肽序列中氨基酸之间的顺序等信息,提高了模型对于活性肽序列特征的表征能力;提出了一种基于多尺度CNN、Mix Pooling和Bi-LSTM构建的多尺度特征网络,用于提高模型的特征提取能力;引入ZLPR损失函数,用于捕获多功能活性肽具有的多个功能之间的潜在依赖性。此外,还构建了一种密集Dropout块,用于防止模型过拟合等问题。通过上述改进的结合,本文提高了多功能活性肽预测模型的性能。
尽管本文方法在多功能活性肽预测中获得了较好的性能,但仍有一些改进空间。在未来,可以引入一些预训练方法,例如:迁移学习、BERT等,同时构建更加丰富的多功能活性肽数据集,旨在为鉴定多功能活性肽问题提供有效的辅助手段。