

任务型对话系统是指以人机对话的形式提供信息或服务的系统。当前,任务型对话系统得到了广泛应用,业务助理系统微软小娜、百度度秘、阿里小蜜等是典型的任务型对话系统。
自然语言理解(natural language understanding,NLU)是任务型对话系统的核心模块,主要作用是对用户输入的句子或者语音识别的结果进行语义解析。在自然语言理解中,一般包含意图识别(intent detection,ID)和槽位填充(slot filling,SF)两个子任务。
本文主要关注基于知识蒸馏的意图识别和槽位填充的研究。目前,意图识别和槽位填充的研究主要基于预训练模型[1⇓-3]。然而,预训练模型由于运算量大且参数较多,在算力较弱的移动设备上难以支持实时性要求较高的智能对话系统。现有研究[4-5]尝试通过知识蒸馏来解决该问题,目前该领域的工作主要针对单一意图识别任务,对意图识别与槽位填充联合模型进行知识蒸馏的相关研究较为缺乏。基于上述背景,本文开展基于多任务蒸馏的意图识别与槽位填充研究,利用联合模型实现意图识别与槽位填充任务间的特征共享,提高模型准确率,并希望通过多任务知识蒸馏解决预训练模型因性能要求难以在常规配置的智能对话系统进行部署的问题。
本文的主要工作如下:1)提出了基于ALBERT 的汉语意图识别和槽位填充联合模型,并探究不同权重值对联合模型的影响。本文利用 ALBERT 获取文本特征表示,通过Softmax 函数进行意图分类。同时将 ALBERT 的输出作为 BiLSTM 的输入,并使用 CRF 解码进行槽位填充。2)创新性地尝试在联合模型的基础上进行蒸馏。利用知识蒸馏,将学习能力强、结构复杂的 ALBERT 模型知识迁移到学习能力弱、结构简单的 BiLSTM 模型中。具体做法是通过 ALBERT 联合模型的输出信息对 BiLSTM 模型进行监督学习,提高其预测精度的同时获得较高的推理效率。
1 相关工作
1.1 意图识别与槽位填充
早期,自然语言理解中的意图识别与槽位填充任务采取独立建模的思路。意图识别本质上是文本分类。最早的意图识别是基于规则模版的方法,通过人工分析每个意图下有代表性的例句总结出规则模板,该方法需要耗费大量人力物力。紧接其后的是基于统计机器学习的方法,其效果比基于规则的方法好,但需要大量人工操作设计领域相关的特征,且无法提取到深层特征,效果仍然不理想。
1.2 联合模型
在实践中发现,意图识别和槽位填充任务很多时候具有较强的相关性。已有研究将两个任务进行联合建模,充分利用意图和槽位中的语义关联。 Xu等[11]利用 CNN 获取底层特征表示,并用 triangular CRF 对意图和槽位的联合条件概率分布进行建模。Goo 等[12]提出了一种通过槽位门控 (slot gate) 机制来学习意图和槽位向量之间关系的方法,利用意图识别的结果对槽位填充过程进行限制。 E等[13]在此基础上提出了 SF-ID 模型,该方法通过双向交互机制来增强两个任务之间的联系。以往的模型大多依赖于自回归方法,但 Wu等[14]发现使用自回归方法对整个序列的依赖关系进行建模会导致冗余计算和高延迟,他们提出采用非自回归的方法对意图识别与槽位填充进行联合建模。 Chen等[15]在2019年提出基于Bert[16] 的意图识别与槽位填充联合模型,以解决传统 NLU 模型泛化能力差的问题。2020年,周奇安等[17]在此基础上进行改良,将 BERT 用作编码器,而解码器基于LSTM 与注意力机制构建。 Dao 等[18]进行了越南语的意图识别与槽位填充相关研究,提出了 JointIDSF 模型,该模型是对 Joint BERT+CRF 模型进行改良,通过注意力机制将意图信息融入到槽位填充过程中。2023年,孟佳娜等[19]利用BERT和RoBERTa对意图识别和语义槽填充进行联合建模,同时使用长短期记忆网络对历史信息进行语义建模,以解决人机对话系统研究中多轮对话历史信息的意图识别问题。
1.3 知识蒸馏
预训练模型如 BERT 虽然能获得较好的效果,但也存在参数太多(BERT-base约110 M参数)以及预测效率太低的问题。因此,许多学者开始研究模型压缩,知识蒸馏是其中一个研究方向。知识蒸馏是一种基于“教师-学生”的网络训练方法,旨在将结构复杂的教师模型的特征表示传递给参数小、结构简单的学生模型。Urban 等[20]提出在 logit 上监督训练浅层模型去逼近深层模型的效果。 Hinton等[21]采用了 softmax 层内特征匹配的策略,提出蒸馏温度T,使蒸馏的性能获得提升。Romero等[22]尝试将教师模型蒸馏到一个更深但比较小的网络中,证明了复杂的深度模型中间层能有效地对学生模型进行监督学习。 Liu等[23]将经过不同初始化训练的多个模型提取为一个模型。 Subramanian 等[4]将蒸馏应用到语音增强中,通过模仿多通道输入的软掩码来获得单通道输入的学生模型。Tang等[24]提出将 BERT模型知识蒸馏到 BiLSTM 模型。Sun 等[1]采用 PKD-Last 和 PKD-Skip两种策略有效地利用教师模型隐含层的信息,对BERT进行蒸馏。廖胜兰等[2]将知识蒸馏应用到意图分类任务中,尝试将教师模型 BERT 中的知识迁移到学生模型 Text-CNN 和 Text-RCNN; Denisov 等[5]将蒸馏应用到语音和文本两种模态中,构建一种端到端的口语理解模型。郭师光等[3]于2021年利用预训练模型 ERNIE 模型[25]知识蒸馏到 FastText 模型。Fukuda 等[26]提出了多教师蒸馏方案,将多个模型的优势整合到单个学生模型中。石佳来等[27]对基于BERT的多教师蒸馏方法进行改进,加入了对中间Transformer层的知识的提取。
2 研究工作
2.1 基于ALBERT的意图识别与槽位填充联合模型构建
2.1.1 预训练模型ALBERT
BERT 是一种基于微调的多层双向变压器编码器。 BERT 利用 Masked LM (MLM) 进行预训练,同时引入Next Sentence Prediction(NSP) 来捕捉句子级的模式,使模型能够理解句子间的关系,最终生成能融合上下文信息的深层双向语言表征。
ALBERT(a lite BERT)对 BERT进行了3点改良:1)将 embedding 的参数进行因式分解。ALBERT 通过将 one-hot 向量映射到大小为E的低维词嵌入空间而不是直接映射到大小为H的隐藏空间,然后从低维词嵌入空间映射到隐藏空间,实现将embedding的参数进行因式分解,使得词嵌入参数从 O(V × H)降低到 O(V × E + E × H),减少模型参数量,其中V为词表大小,E为词向量维度,H为隐层维度。2)跨层的参数共享。通过共享所有层的参数使模型参数较 BERT 大大减少。3)使用 SOP (sentence order prediction)任务取代 NSP (next sentence prediction)任务进行句间连贯性预测。将难度更小的主题预测和连贯性预测结合的 NSP 任务替换成难度更大的句子连贯性预测的 SOP 任务,让模型学习到更多的信息,提升模型的性能。
2.1.2 基于ALBERT的联合模型
ALBERT较 BERT参数更少,并且 SOP 任务能让模型学习到更多信息。因此本文使用 ALBERT 替代 BERT 进行意图识别和槽位填充联合建模。模型整体框架如图1所示。
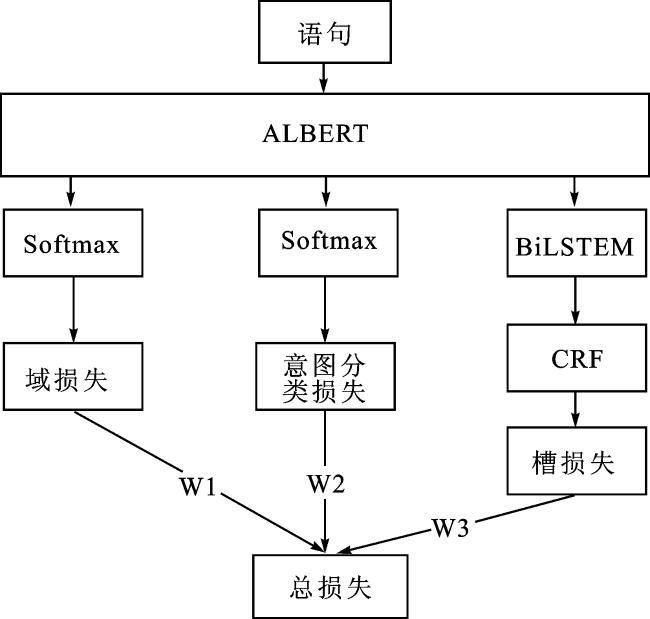
进行联合训练时,长度为Ω的句子的标记嵌入、段嵌入和位置嵌入拼接起来作为 ALBERT 模型的输入, ALBERT 输出融合了全文语义信息后的各个字符X={x1,x2,…,xn+2},其中x1是[CLS]标记的编码表示,代表整句话的句向量,xn+2是[SEP]标记的编码表示,在单句分类中只作为最后一个标记。
x1作为整个文本的语义表示分别输入到领域分类和意图识别任务的输出层中进行分类,得到领域分类任务的预测标签 和意图识别任务的预测标签 。
=softmax(Wdx1+bd),
=softmax(Wix1+bi)。
式(1)中的Wd和bd为领域分类任务输出层可训练的权重和偏置,式(2)中的 Wi和bi为意图识别任务输出层的权重和偏置。
本文使用交叉熵作为领域分类和意图识别的损失函数,如式(3)所示,式中m为样本总数。
LCE=- y(j)log 。
由于存在各个领域、不同意图间数据不平衡的问题。在计算损失时添加一个类别权重w,类别样本数越少,权重越大,那么在进行反向传播时,求导获得的梯度越大,模型参数变化也越大,进而对模型的影响增大。
类别权重的计算方法如式(4)所示,总样本数为m,领域类别数为N,属于某领域的样本数为 ,其中∑j =m,则某一领域j的类别权重为
= ,j∈[1,N]。
意图的类别数为M,属于某意图的样本数为 ,其中∑g =m,则某一意图 g 的类别权重为
= ,g∈[1,M]。
最终,领域分类和意图识别的损失函数如下:式(6)为领域分类的损失,式(7)为意图识别的损失。
=- log ,
=- log 。
式中:y为真实标签; 为预测标签;wi为领域的类别权重;wd为意图的类别权重。
在槽位填充过程中,{x1,x2,x3,…,xn+2}作为文本中每个字的向量表示输入到双向LSTM网络,将每个时间序列的正向输出 和反向输出 进行拼接得到每个时间步的输出ht=[ , ]。将BiLSTM的输出序列h=(h1,h2,…,hn+2)输入到概率模型CRF中,进一步增强前后标注的约束,最终获得最优的标签序列 =(y1,y2,…,yn+2)。
槽位填充任务训练过程将最大化正确标签序列分数在总体分数的比重,其优化目标如下:
p(y|h;W,b)= 。
式中:m为样本总数;ys为正确的标签序列; 为所有可能的标签序列; 为标签序列为正确序列的分数; 为每种可能序列的分数。
分数包括发射分数和转移分数。发射分数由BiLSTM生成,表示一个词选择不同标签的分数,用 表示。将发射分数输入到CRF中,由CRF学习到转移矩阵(转移分数),转移分数表示前一个标签转移到此时标签的分数,用 表示。其中,k是单词的位置索引,yk是类别的索引。整体的分数为
score(X,y)= + 。
式(8)取似然对数作为最终槽位填充任务的损失函数
Ls=- 。
最终,基于ALBERT的意图识别和槽位填充的联合损失函数为
Ltotal=WdLd+WiLi+WsLs。
ALBERT虽然减少了参数的数量,但并不会提高预测效率,因为虽然每层参数共享,但前向传播时还是要对每一层每一个参数进行计算。所以在ALBERT模型训练好后,直接获取模型的预测概率,用于知识蒸馏。
2.2 联合模型知识蒸馏策略
2.2.1 基于BiLSTM的学生模型
本文采用BiLSTM作为学生模型。相比 ALBERT, BiLSTM 是一种浅层神经网络,将 ALBERT 知识蒸馏 BiLSTM,使模型参数进一步减少,并且以更低的复杂度来获得类似的预测效果。LSTM 虽能很好地捕获较长距离的依赖关系,但无法编码从后向前的信息,而 BiLSTM 能从正向和反向两个方向同时对序列进行建模,更好地捕获双向语义信息。
因此,本文使用BiLSTM 作为学生模型,更好地捕获双向语义的同时学习到 ALBERT 知识,从而在提高BiLSTM模型预测精度的同时,保持较高的推理效率。
2.2.2 基于ALBERT的知识蒸馏
本文采用联合蒸馏方式,同时进行意图识别与槽位填充任务的知识蒸馏。知识蒸馏的总体流程如图2所示。先将数据集输入到 ALBERT 中进行意图识别与槽位填充联合模型的训练,获取到教师模型(teacher model)。之后将数据集输入 BiLSTM 中进行训练,将 BiLSTM 输出的概率向量与 hard target、教师模型输出的 soft target 相结合计算知识蒸馏损失,使BiLSTM 的输出分布在保持精确的同时能够尽可能地逼近教师模型,从而学到 ALBERT 的知识。
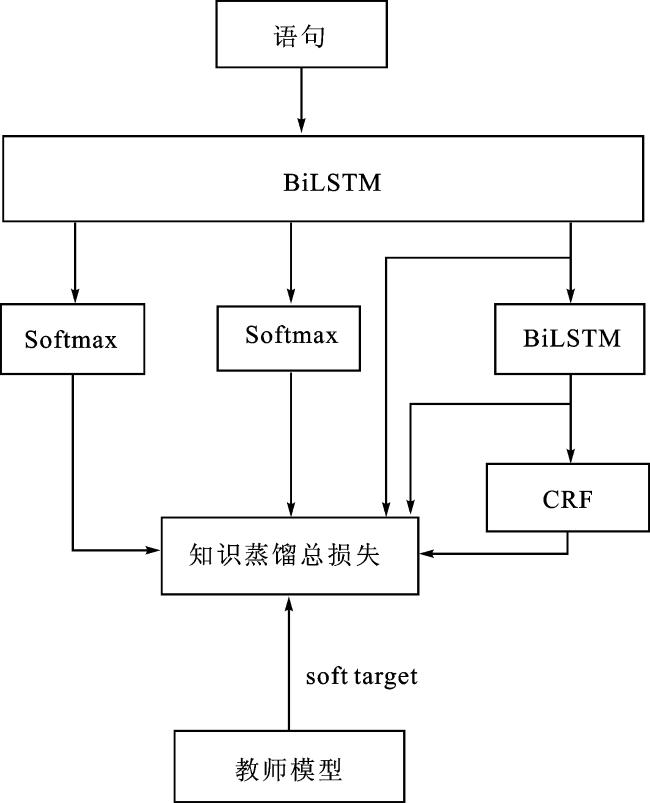
知识蒸馏的损失函数包含两个部分。其一是hard target,该部分与教师模型 ALBERT 的损失函数相同。领域分类和意图识别任务使用交叉熵损失函数,同样为了解决类不平衡的问题,在计算损失时添加一个类别权重w。槽位填充任务使用 CRF 层的损失函数。公式如下:
LCE=- y(j)log w(j),
$L_{\mathrm{CE}}^{s}=-\sum_{j=1}^{m}\left[s\left(X, y_{(j)}^{s}\right)-\log \left(\sum_{\bar{y}_{(j)}^{s} \in Y_{X}} e^{s\left(X, \bar{y}_{(j)}^{s}\right)}\right)\right] 。$
式中:y为对应任务的真实标签; 为对应任务的预测标签。
其二是soft target,使用教师模型输出的概率向量与BiLSTM输出的概率向量计算均方误差,可以使 BiLSTM 学习到ALBERT中更加软化的知识。soft target 包含类别间的信息,这是传统 one-hot label 中没有的。通过最小化损失函数,使学生模型 BiLSTM 的输出分布尽可能地逼近教师模型,从而实现知识蒸馏的目的。公式如下:
$ L_{\text {distil }}=\left\|\boldsymbol{z}^{(t)}-\boldsymbol{z}^{(s)}\right\|_{2}^{2} \text { 。 } $
式中:z(t)是教师模型对应任务的输出;z(s)是学生模型对应任务的输出。
最终,每个任务的相应损失函数如下:
L=α·LCE+(1-α)·Ldistil。
由于Softmax 输出分布在正确位置的值会非常大,其他位置很小,对损失函数的影响会比较小,因此直接用教师网络的概率分布对学生网络进行监督学习往往效果有限。相关研究[30]对Softmax 函数进行改进,增加参数T来调整Softmax的输出分布,改进的Softmax函数如下:
yi= ,
其中T数值越大,分布越缓和。当 T 等于1时,式(16)相当于原始Softmax函数。
具体训练步骤如下:选定合适的T值,先在教师模型中训练并预测,然后在相同的T值下训练学生模型。当学生模型进行预测时,将值T设置为1,经原始Softmax函数获取输出概率。
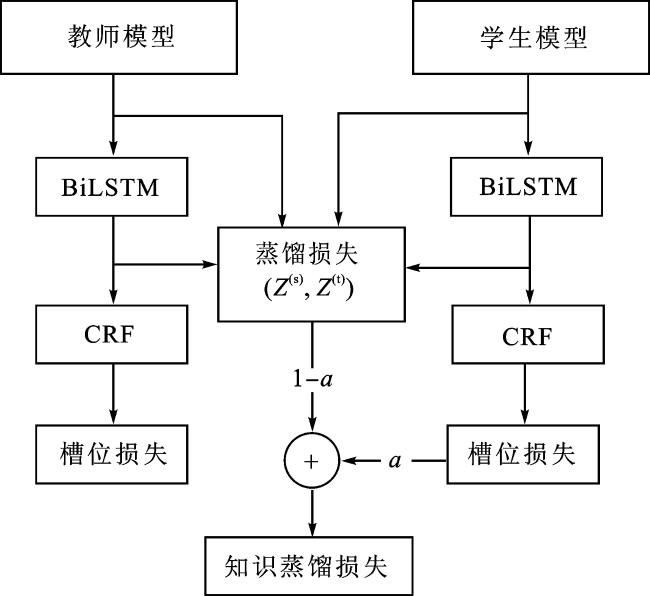
任务型对话系统中的槽位填充本质上是序列标注,利用 CRF 解码可以获得更好的模型效果。但 CRF 利用相邻标签之间的相关性对标签序列进行全局建模,经CRF层解码所得结果丢失了类别间的信息,这增加了从教师模型中提取知识的难度[31]。因此,本文在进行槽位填充任务时,提出使用 BiLSTM 输出的 logits,即 CRF 层的输入对学生模型进行监督学习,其比 hard label 包含更丰富的信息。在此基础上,为增强学生模型的拟合能力,本文还将 ALBERT 的输出作为学生模型输出的拟合目标。由于 ALBERT 的输出层维度和学生模型输出维度不一样,因此增加了一个额外的线性矩阵进行维度转换。槽位填充的知识蒸馏流程如图3所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
除了槽位填充的知识蒸馏损失,领域分类和意图识别都使用教师模型经改进的Softmax 函数输出的概率向量作为 soft target。最终,对3个任务的损失函数加权求和得出总损失函数
=W1Ld+W2Li+W3Ls。
3 实验与分析
3.1 数据集
本文使用 SMP 2019会议的任务型对话系统评测语料作为数据集。其主要包括下面3个子任务:领域分类、意图识别和槽位填充。一共涵盖29种领域、24种意图和60种语义槽。其中,训练集、验证集和测试集的样本大小分别为1 694、180、180,部分训练语料如表1所示。
表1 部分训练语料Tab.1 Part of the training corpus |
| 编号 | 文本 | 领域 | 意图 | 槽位 |
|---|---|---|---|---|
| 1 | 请帮我打开uc。 | app | LAUNCH | {name:uc} |
| 2 | 去深圳怎么坐车? | map | ROUTE | {endLoc_city:深圳} |
| 3 | 北京到成都的汽车时刻表。 | bus | QUERY | {Dest:成都,Src:北京} |
| 4 | 给我放一部最新的电影。 | cinemas | QUERY | {} |
3.2 评价指标
本文实验中领域分类和意图识别任务评测指标为准确率,槽位填充任务的评测指标为F1度量值。
本文使用句准确率(sentence accuracy)来衡量模型在解决领域分类、意图识别和槽位填充3个问题上的综合能力,即以上3项结果全部正确时才算正确。计算公式如下:
句准确率=3项任务都取得正确结果的句子数/总句子数。
3.3 实验分析
表2 ALBERT模型训练参数Tab.2 Training parameter of ALBERT model |
| 实验参数 | 参数值 | 参数说明 |
|---|---|---|
| Learning rate | 5×10-5 | Adam优化器学习率 |
| Batch_size | 12 | 每次模型更新的训练样本数 |
| epoch | 15 | 训练迭代轮数 |
| temperature | 3.5 | 蒸馏温度T |
| Max_seq_length | 32 | 句子最大长度 |
表3 测试集实验结果Tab.3 The experimental results of the test set |
| 模型 | 领域分类精度/% | 意图识别精度/% | 槽位填充F1值/% | 句准确率/% | 时间/s |
|---|---|---|---|---|---|
| BERT-base | 96.11 | 95.55 | 81.97 | 78.33 | 7.86 |
| ALBERT-base | 94.44 | 96.11 | 83.04 | 77.74 | 7.37 |
| BiLSTM | 86.66 | 91.66 | 68.12 | 58.33 | 0.38 |
| KD BiLSTM(蒸馏模型) | 90.56 | 92.77 | 73.57 | 67.22 | 0.39 |
表4 验证集实验结果Tab.4 The experimental results of validation set |
| 模型 | 领域分类精度/% | 意图识别精度/% | 槽位填充F1值/% | 句准确率/% | 时间/s |
|---|---|---|---|---|---|
| BERT-base | 95.55 | 93.88 | 84.49 | 76.66 | 7.61 |
| ALBERT-base | 93.33 | 93.89 | 82.35 | 77.22 | 7.35 |
| BiLSTM | 85.00 | 88.88 | 67.92 | 57.77 | 0.37 |
| KD BiLSTM(蒸馏模型) | 88.89 | 89.44 | 73.89 | 63.33 | 0.42 |
另一点值得注意的是,蒸馏模型相比教师模型在槽位填充任务上的效果相差较大,可能的原因是序列标注任务的复杂度导致其学习效果不佳,但由表3可以看出,蒸馏模型在测试集槽位填充上的表现还是比单独训练的学生模型高出5.45%,这表明知识蒸馏对模型的训练很有帮助。
综上所述,本文提出的 ALBERT 模型取得了不错的效果并证明了其优越性。而将其知识蒸馏到 BiLSTM 模型中,可获得较快的推断速度。此外,虽然蒸馏模型在句准确率上会有所降低,但模型复杂度和参数数量相对于ALBERT 模型具有优势,对硬件资源要求不高,能部署在小型的配置环境中。
3.4 不同权重对ALBERT模型的影响分析
本文探索不同的权重值对教师模型 ALBERT 的影响,联合模型能实现多个任务之间的信息共享,但其损失函数需要考虑到各任务的优化目标,一般做法是对各任务的优化目标进行加权求和,根据子任务的训练情况分配不同的权重值。实验表明,寻找到合适的权重参数能有效提高模型性能,实验结果如表5所示。
表5 不同权重值对ALBERT模型的影响 单位:%Tab.5 Influence of different weight values on ALBERT model |
| 模型 | 领域分类精度 | 意图识别精度 | 槽位填充F1值 | 句准确率 |
|---|---|---|---|---|
| Wi=1,Wd=1,Ws=1 | 93.88 | 95.00 | 80.61 | 77.22 |
| Wi=1,Wd=1,Ws=2 | 94.44 | 96.11 | 83.04 | 77.74 |
| Wi=1,Wd=1,Ws=3 | 95.56 | 95.56 | 82.17 | 76.67 |
| Wi=1,Wd=1,Ws=4 | 93.89 | 95.00 | 80.61 | 72.22 |
| Wi=2,Wd=1,Ws=1 | 95.00 | 95.00 | 81.66 | 76.67 |
| Wi=1,Wd=2,Ws=1 | 93.89 | 97.22 | 76.25 | 72.22 |
| Wi=2,Wd=2,Ws=1 | 94.44 | 96.67 | 81.20 | 75.56 |
从表5可以看出在Wi=1,Wd=1,Ws=2的情况下,模型能获得最好的效果。之后,随着槽位填充任务权重的增加,领域分类与意图识别的效果受到影响,句准确率下降。另外,在Wi、Wd大于Ws的时候,模型效果下降,这说明序列标注任务更复杂,模型容易受分类任务影响,需要增加槽位填充任务权重值,使模型在训练过程中能更好地学习到各任务之间的关系。
3.5 探究类别权重对模型的影响
在任务型对话系统数据集中,领域和意图的类别比较多,对于样本比较少的数据集,其往往存在各个领域、不同意图间的数据不平衡的问题。对于样本比例失衡问题,本文通过类别权重对模型进行优化。实验结果如表6所示。
表6 探究类别权重对模型的影响单位:%Tab.6 The influence of class weight on the model |
| 模型 | 领域分类精度 | 意图识别精度 | 槽位填充F1值 | 句准确率 |
|---|---|---|---|---|
| ALBERT | 94.44 | 96.11 | 83.04 | 77.74 |
| KD BiLSTM | 90.56 | 92.77 | 73.57 | 67.22 |
| BERT(no_adjust) | 93.33 | 92.77 | 82.09 | 74.44 |
| ALBERT(no_adjust) | 93.33 | 94.44 | 81.65 | 75.00 |
| KD BiLSTM(no_adjust) | 83.89 | 91.67 | 70.64 | 60.00 |
通过实验可以看出,与没有添加类别权重的 ALBERT 和BERT 模型相比,添加了类别权重的 ALBERT 模型在领域分类、意图识别和槽位填充3个任务上的效果均获得提升,这表明类别权重的引入能有效解决各类别之间的数据不平衡问题。另外,通过表6可以发现,进行类别平衡调整的蒸馏模型比没有经过调整的效果要好,其分别在领域分类、意图识别和槽位填充上获得了6.67%、1.10%、2.93%的提升,表明了类别不平衡问题的解决对知识蒸馏的结果有较大影响。
4 结语
本文对任务型对话系统进行了研究。目前,虽然预训练模型如 BERT 能在该领域中取得良好效果,但由于其模型复杂、参数量大、推断速度慢等问题,往往难以支持运行环境要求较高的实际业务场景应用。因此,本文提出基于ALBERT 的意图识别和槽位填充联合模型,大幅度减少预训练模型参数,并且在联合模型的基础上,利用知识蒸馏,将 ALBERT 知识迁移到BiLSTM 模型,提高了 BiLSTM 模型的泛化能力,并获得较高的推断速度。同时本文还尝试对数据中意图类别不平衡问题进行研究,使用类别权重对模型进行调整。该模型在SMP 2019 会议评测数据集上进行实验,结果表明,基于ALBERT的意图识别与槽位填充联合模型能获得77.74%的准确率,而蒸馏模型在句准确率为67.22%的情况下,推断速度约为 ALBERT的18.9倍。此外,未来我们将致力于进一步提升模型的推断速度、减少模型参数数量,同时使其在句准确率上取得更好的性能水平。