

在图像处理过程中,图像本身的表示形式是影响处理结果的关键因素。稀疏表示已被证明是一种极有效的图像表示算法[1]。近年来,为了实现稀疏表示,研究人员已经开发出例如稀疏主成分分析(PCA)[2]、稀疏非负矩阵分解(NMF)[3]等多种算法。作为稀疏表示最典型的方法之一,稀疏编码(spares coding,SC)在机器学习、信号处理和神经科学[4⇓⇓-7]等领域中得到了广泛的关注。
SC是利用过完备字典来线性表示图像的编码过程,其中的非零元素只占所有元素的极小部分,体现了编码的稀疏性。SC具有众多优点,如:稀疏表示时其每个数据点都表示为少量基本矢量的线性组合,表示方式更简洁;编码状的稀疏表示可以允许数据快速检索等。SC算法目前已被应用于如图像恢复[8]、信号分类[9]、人脸识别[10]和图像分类[11-12]等多个领域中。
近年来,研究人员针对SC的部分缺点提出了改进算法。对于SC计算复杂度过高的问题,文献[10]提出了一种迭代的软阈值方法,该方法在负梯度方向上取Barzilai-Borwein步长,然后将软阈值算子应用于结果,提升了SC的计算速率。 Lee等[13]提出了一种特征符号搜索方法,将不可微L1范数问题简化为L1正则化最小二乘问题,从而加快了优化过程。在传统方法中,SC的字典选择也是影响算法效果的一个关键因素,然而其字典一般是从标准库中选择的[14],甚至是从随机矩阵[15]中生成的。因此,有些学者试图通过为稀疏编码设计一个更合适的字典来提升SC的性能。Aharon 等[16]提出的K-SVD方法不同于之前利用标准库获得数据稀疏表示的算法,该算法使用正交匹配追踪算法(orthogonal matching pursuit, OMP)或基追踪算法(basis pursuit, BP),作为其学习词典迭代过程的一部分。还有些学者致力于将稀疏编码与经典机器学习方法相结合以提出新的理论框架。文献[17]将线性判别分析(linear discriminant analysis, LDA)与稀疏表示相结合提出了稀疏主成分判别分析的方法(sparse linear discriminant analysis,SDA),该方法可以通过重建特性、辨别力和稀疏性来进行分类。文献[11]提出了一种新的判别方法,称为监督字典学习算法(supervised dictionary learning,SDL),有效地利用图像分类任务中相应的稀疏信号分解去学习共享字典和判别模型。
以上研究都在克服原始稀疏编码的不同缺点,但是都没有考虑到数据中潜在的几何结构。Kavukcuoglu等[18]提出了几种稀疏编码方法的变体,这些算法通过增加一些稀疏编码系数的附加约束来捕获数据中的结构,即它们可以通过添加额外的空间一致约束来学习,以获得局部不变的稀疏表示。Gao等[19]首次提出了使用流形学习算法学习数据几何结构的方法,但未明确提出详细的优化方案,所提方法的性能仅在图像分类任务上进行了评估。Zheng等[20]在文献[19]的基础上提出了一种新的算法,称为图正则化稀疏编码(graph regularization sparse coding,GraphSC),该算法明确考虑了数据的局部几何结构。 GraphSC通过构建一个近邻图来编码数据中的几何信息,并使用谱图理论中的图拉普拉斯算子作为光滑算子来保留局部流形结构。与传统的SC算法相比,GraphSC具有更强大的分类能力。基于文献[20]的研究,Gao等[21]基于直方图交点的度构建相似度图,利用超图捕获样本之间的高阶关系,进一步提升了GraphSC的性能。此后,Sha等[22]提出将低秩表示[23](low-rank representation, LRR)引入图正则化的处理过程,并就此提出了低秩正则化稀疏编码算法(low-rank regularized spares coding,LogSC)。由于添加了低秩约束,LogSC在部分任务中获得了较GraphSC更优秀的性能。
然而,GraphSC及其改进方法中的拉普拉斯图都是预先定义且固定不变的,并不会参与之后对于字典与稀疏编码的学习过程,而预先定义的拉普拉斯图往往不是最合适的。针对这个问题,我们对GraphSC算法进行了改进,提出了自适应正则化稀疏编码(graph regularization sparse coding with adaptive neighbour,GraphSCAN)算法。我们假设数据指向较小的距离代表更可能成为邻居,因此 GraphSCAN可以从自适应性分解的结果中学习局部流形结构,并重新构造以保留精炼的局部结构,根据每个数据点的本地连通性选择自适应近邻(adaptive neighbor, AN)以获得相似度图,然后将ANs正则化约束合并到GraphSC中。GraphSCAN将图的构建和稀疏编码纳入到统一框架中,使得内部局部结构学习的过程和图稀疏编码的过程同时进行,并最终提高了GraphSC的性能。
1 相关工作
1.1 稀疏编码(SC)
SC的目的是对于给定的一个数据矩阵,找到一组捕获高级语义的基础向量(即字典),并输出数据的稀疏表示。
给定一个数据矩阵X∈[x1,x2,…,xn]∈Rn×m,X的每一列都是样本矢量。令A=[a1,a2,…,ak]∈Rn×k为字典矩阵,其中ai表示字典中的基础向量。令E=[e1,e2,…,em]∈Rk×m为系数矩阵,其中每一列都是数据点的稀疏表示。每个数据点都可以表示为字典中基向量的稀疏线性组合。
稀疏编码的目标函数定义如下:
‖X-AE +β f(ei)。
因此,由文献[13,26-27],可令f为f(ei)=‖ei‖1,此时目标函数化为
‖X-AE +β ‖ei‖1。
由于(2)式中的目标函数可能仅A或E是凸的,2个变量不能同时为凸。因此,可以通过固定一个变量、最小化另一个变量来迭代优化目标函数(2)。
1.2 图正则化稀疏编码(GraphSC)
GraphSC将拉普拉斯图引入SC算法,并使用图拉普拉斯正则项来保留数据局部流形结构。
对于给定一组n维数据点x1,x2,…,xm,构造一个有m个顶点的最近邻图G,其中每个顶点代表一个数据点。 令W为图的权重矩阵,若xi是xj的最近邻或者xj是xi的最近邻,那么Wij=1,否则Wij=0。定义xi的度为di= Wij,且D=diag(d1,d2,…,dm)。
图正则化目标函数 [20]可表示为
(ei-ej)2Wij=tr(ETLE),
式中L是图拉普拉斯矩阵,L=D-S。由(2)、(3)式可得GraphSC的目标函数为
$\begin{aligned}\min_{\begin{array}{c}\mathrm{s.t.~}\lambda\geqslant0\parallel a_i\parallel^2\leqslant c,i=1,2,\cdots,k\\\end{array}}\parallel X-AE\parallel_{\mathcal{F}}^2+\\\beta\sum_{i\operatorname{=}1}^m\parallel\boldsymbol{e}_i\parallel_1+\lambda\operatorname{tr}(\boldsymbol{E}^\mathrm{T}\boldsymbol{L}\boldsymbol{E})_0\end{aligned}$
2 自适应图正则化稀疏编码算法及其求解
利用数据的局部几何结构,GraphSC算法提升了SC算法的计算能力。但GraphSC使用的拉普拉斯图会在全局计算前预先定义且固定不变,并不参与之后对于字典与稀疏编码的学习过程。我们提出自适应方图正则化稀疏编码的算法(graph regularization sparse coding with adaptive neighbour,GraphSCAN)对GraphSC所存在的这个问题进行了改进。
2.1 GraphSCAN的算法模型
设输入的原始数据集为X,X中的任意一数据点xi都有所有数据点{x1,x2,…,xn}可以作为近邻与之连接,连接的概率为sij。基于数据点间的欧几里得距离构造邻域矩阵,距离越小则成为最近邻的可能性越大。本文算法的求解形式如下:
$\begin{array}{l}\min _{\text {s.t. } \lambda \geqslant 0\left\|\boldsymbol{a}_{i}\right\|^{2} \leqslant c, \boldsymbol{s}_{i}^{\mathrm{T}} 1=1,0 \leqslant s_{i} \leqslant 1}\|\boldsymbol{X}-\boldsymbol{A} \boldsymbol{E}\|_{\mathrm{F}}^{2}+ \\\alpha \sum_{j=1}^{n}\left(\left\|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right\|_{2}^{2} s_{i j}+\gamma s_{i j}^{2}\right)+ \\\beta \sum_{i=1}^{n}\left\|\boldsymbol{e}_{i}\right\|_{1}+\lambda \operatorname{tr}\left(\boldsymbol{E}^{\mathrm{T}} \boldsymbol{L}_{S} \boldsymbol{E}\right) 。 \\\end{array}$。
(5)式第1项对原始数据集X求其字典及其稀疏编码,其中矩阵X为原始数据集,A代表字典阵,E代表其稀疏阵。
(5)式第2项是自适应正则化函数,使用其完成自适应相似矩阵的构造[28]。其中α和γ均为正则化参数,si∈Rn×1表示向量,其第j个元素为sij。在所有xi有相同的概率即 时,第二项可写作
(‖xi-xj sij+γ ),
式中γ是正则化参数。因此,可以将(6)式重新表示为
。
通过求解(7)式获得的矩阵S∈Rn×n,可被视为相似度矩阵[29-30]。 可通过以下步骤来表示数据平滑度:
\begin{array}{c}\frac{1}{2} \sum_{i, j=1}^{n}\left\|\boldsymbol{e}_{i}-\boldsymbol{e}_{j}\right\|{ }_{2}^{2} s_{i j}=\sum_{i, j=1}^{n} \boldsymbol{e}_{i} s_{i j} \boldsymbol{e}_{i}^{\mathrm{T}}-\sum_{i, j=1}^{n} \boldsymbol{e}_{i} s_{i j} \boldsymbol{e}_{j}^{\mathrm{T}}= \\\sum_{i, j=1}^{n} \boldsymbol{e}_{i}\left(\boldsymbol{D}_{s}\right)_{i i} \boldsymbol{e}_{i}^{\mathrm{T}}-\sum_{i, j=1}^{n} \boldsymbol{e}_{i} s_{i j} \boldsymbol{e}_{j}^{\mathrm{T}}= \\\operatorname{tr}\left(\boldsymbol{E}^{\mathrm{T}} \boldsymbol{D}_{S} \boldsymbol{E}\right)-\operatorname{tr}\left(\boldsymbol{E}^{\mathrm{T}} \boldsymbol{W}_{S} \boldsymbol{E}\right)= \\\operatorname{tr}\left(\boldsymbol{E}^{\mathrm{T}} \boldsymbol{L}_{S} \boldsymbol{E}\right) 。\end{array}
(5)式第3项是度量第一项中稀疏矩阵E稀疏度的函数,设f(ei)=‖ei‖1作为度量函数。
(5)式第4项是局部图拉普拉斯约束函数,使用其增强传统低秩表示模型的局部性和稀疏性。其中LS是Si的拉普拉斯矩阵,LS=DS-WS,tr( )表示矩阵的迹。
2.2 GraphSCAN的算法求解
本节提出求解GraphSCAN的更新算法,该算法通过固定其他变量更新一个变量的值来优化目标,此过程重复直到收敛。
2.2.1 固定A、E更新S
观察(5)式不难发现,在固定A、E时更新S,最小化(5)式可等价于解决下式:
(‖xi-xj sij+γ )+βtr(ETLSE),s.t. 1=1,0≤si≤1,
式中ε= 。由(5)式结合(9)式有
(‖xi-xj sij+γ + ε‖ei-ej sij),s.t. 1=1,0≤si≤1。
可通过逐个求解的方式求解(10)式,此时(10)式等价于
$\begin{array}{l} \min _{s_{i}} \sum_{i, j=1}^{n}\left(\left(\left\|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right\|_{2}^{2}+\right.\right. \\\left.\left.\frac{1}{2} \varepsilon\left\|\boldsymbol{e}_{i}-\boldsymbol{e}_{j}\right\| \frac{2}{2}\right) s_{i j}+\gamma s_{i j}^{2}\right), \\\text { s. t. } \boldsymbol{s}_{i}^{\mathrm{T}} 1=1,0 \leqslant \boldsymbol{s}_{i} \leqslant 1 。\end{array}$
令 =‖xi-xj , = ‖ei-ej ,且di∈Rn×1,第j个元素为dij= +ε ,将其代入(11)式可得
。
设ζ和η≥0为拉格朗日乘子,则(12)式的拉格朗日函数为
R(si,η,ζi)= -η(1-1)- si。
根据KKT条件[31],满足sij≥0,最优解可以定义为
sij= ,
{ , ,…, }由小到大表示。如果最优si只有k个非零元素,则根据(14)式可知sik>0且si,k+1=0。因此,有
由(15)式和 1=1的约束,有
=1⇒η= + 。
结合(15)和(16)式,可得
- <γi≤ - 。
为了获得具有k个非零值的最优si,可以将γi设置为
γi= - 。
为了便于计算,可以将整体γ设置为γ1,γ2,…,γn的均值,即
γ= 。
通过取γi的平均值,所有si的平均非零元素应为k。我们不直接搜索正则化参数γ,而是搜索近邻数k。因为k是一个整数,并且其值是有限的(即0≤k≤n),所以参数搜索会更加容易。
2.2.2 固定S、A更新E
在固定S、A时更新E,求解(5)式即等同于求解下式:
$\begin{array}{l}\min \|\boldsymbol{X}-\boldsymbol{A} \boldsymbol{E}\|_{\mathrm{F}}^{2}+\beta \sum_{i=1}^{n}\left\|\boldsymbol{e}_{i}\right\|_{1}+ \\\lambda \operatorname{tr}\left(\boldsymbol{E}^{\mathrm{T}} \boldsymbol{L}_{S} \boldsymbol{E}\right) 。\end{array}$
由于当si包含0时,(20)式中的L1正则化问题是不可微的,因此本文选择采用基于坐标下降的优化方法来求解。以向量形式重写后,‖X-AE 可写为
‖xi-Aei‖2。
拉普拉斯正则项tr(ETLSE)可写为
tr(ETLSE)=tr = Lij ei= Lij ej。
结合(21)、(22)式可重写如下:
min‖xi-Aei +β ‖ei‖1+λ Lij ej。
在更新ei时,其他向量{ej}j=1是固定的,因此可得
f(ei)=‖xi-Aei +β | |+λLij ej+ hi,
定义h(si)=‖xi-Aei +λLij ej+ hi, |ei|作为ei的第j个系数的可微分值。因此,实现f(si)最优值的最优条件可改写为
当其不符合最佳条件时,最佳子梯度 f(ei)为
通过替换| |为 ( >0),- ( <0)或0( =0)去掉L1范数的约束。 此时,原问题可以简化为标准的无约束二次优化问题(QP)并通过线性方法求解。由此,可得算法1以描述求解(20)式的详细算法过程。
| 算法1 图正则化稀疏码算法 |
|---|
| 输入:m数据点的数据集X,字典A,图拉普拉斯矩阵L,参数λ、β。 |
| 输出:最优系数矩阵E*=[ , ,…, ]。 |
| 步骤1 对所有满足1≤i≤m的i do; |
| 步骤2 初始化:ei= ,θ= ,Π=∅,其中θj∈{1,0,-1}表示sign( ); |
| 步骤3 从ei中选择零系数、j=argmaxj h|ei|的项。仅在提高(25)式局部结果的情况下改变ei; |
| 步骤4 |
| 1)定义 是A的子矩阵,它仅包含与活动集相对应的列。令 和 为ei、hi的子向量, 为与活动集相对应的θ。 |
| 2)计算得出结果。 |
| 无约束QP: |
| g( )=‖xi- +β + |
| λLii ei+ hi。 |
| 令 =0,可以在当前活动集下获得ei的最优值 |
| =( +γLiiI)-1 , |
| 式中I是单位矩阵。 |
| 3)在从 到 的闭合线段上执行离散线搜索。 |
| 4)从活动集合中去除 的零系数并更新θ=sign(ei)。 |
| 步骤5 检查最优性条件步骤 |
| 1)非零系数的最优性条件: h(ei)+βsign( )=0,∀ ≠0,如果不满足条件1),转到Step4(不进行任何操作);否则判断条件2)。 |
| 2)零系数的最优条件:| h(ei)|≤β,∀ =0,如果不满足条件(2),转到Step3;否则返回ei作为解决方案,以 表示。 |
| 步骤6 结束 |
2.2.3 固定S、E更新A
在固定S、E时更新A,最小化(4)等同于求解下式:
‖X-AE ,s.t.‖ai‖2≤c,i=1,2,…k。
使用拉格朗日对偶法对(29)式进行求解。令ε=[ε1,ε2,…,εk]为与不等式约束相关联的拉格朗日乘数,则拉格朗日对偶函数为
g(ε)=infBL(A,ε)=infB(‖X-AE + εi(‖ei‖2-c))。
令Λ为k×k的对角矩阵,其对角线数Λii=λi。那么L(A,ε)可写作
$\begin{array}{l}L(\boldsymbol{A}, \boldsymbol{\varepsilon})=\|\boldsymbol{X}-\boldsymbol{A} \boldsymbol{E}\|{ }_{\mathrm{F}}^{2}+ \\\quad \operatorname{tr}\left(\boldsymbol{A}^{\mathrm{T}} \boldsymbol{A} \boldsymbol{\Lambda}\right)-c \operatorname{tr}(\boldsymbol{\Lambda})= \\\operatorname{tr}\left(\boldsymbol{X}^{\mathrm{T}} \boldsymbol{X}\right)-2 \operatorname{tr}\left(\boldsymbol{A}^{\mathrm{T}} \boldsymbol{A} \boldsymbol{\Lambda}\right)+\operatorname{tr}\left(\boldsymbol{E}^{\mathrm{T}} \boldsymbol{A}^{\mathrm{T}} \boldsymbol{A} \boldsymbol{E}\right)+ \\\operatorname{tr}\left(\boldsymbol{A}^{\mathrm{T}} \boldsymbol{A} \boldsymbol{\Lambda}\right)-c \operatorname{tr}(\boldsymbol{\Lambda}) 。\end{array}$
令(31)式的一阶导数等于零即可获得最佳解A*,即
A*EET-XET+A*Λ=0。
这时,有
A*=XET(EET+Λ)-1。
将(33)式代入(31)式可得
$\begin{aligned}g(\boldsymbol{\varepsilon}) & =\operatorname{tr}\left(\boldsymbol{X}^{\mathrm{T}} \boldsymbol{X}\right)-2 \operatorname{tr}\left(\boldsymbol{X} \boldsymbol{E}^{\mathrm{T}}\left(\boldsymbol{E} \boldsymbol{E}^{\mathrm{T}}+\boldsymbol{\Lambda}\right)^{-1} \boldsymbol{E} \boldsymbol{X}^{\mathrm{T}}\right)- \\& \operatorname{ctr}(\boldsymbol{\Lambda})+\operatorname{tr}\left(\left(\boldsymbol{E} \boldsymbol{E}^{\mathrm{T}}+\boldsymbol{\Lambda}\right)^{-1} \boldsymbol{E} \boldsymbol{X}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{E}^{\mathrm{T}}\right)= \\& \operatorname{tr}\left(\boldsymbol{X}^{\mathrm{T}} \boldsymbol{X}\right)-\operatorname{tr}\left(\boldsymbol{X \boldsymbol { E } ^ { \mathrm { T } }}\left(\boldsymbol{E} \boldsymbol{E}^{\mathrm{T}}+\boldsymbol{\Lambda}\right)^{-1} \boldsymbol{E} \boldsymbol{X}^{\mathrm{T}}\right)- \\& \operatorname{ctr}(\boldsymbol{\Lambda}) 。\end{aligned}$
由此可得拉格朗日对偶函数
tr(XET(EET+Λ)-1EXT)+ctr(Λ),s.t.εi≥0,i=1,2,…,k。
(35)式可以通过牛顿法或共轭梯度来求解。令Λ*为最优解,那么最优A*=XET(EET+Λ)-1。由于不能保证EET+Λ可逆,因此本文算法使用伪逆代替直接求逆。
至此,GraphSCAN的算法步骤可总结如下。
| 算法2 自适应图稀疏编码算法 |
|---|
| 输入:数据矩阵X∈ 的初始值,簇号c,参数k、λ、α、β; |
| 输出:字典矩阵A、稀疏编码E。 |
| 步骤1 初始化字典矩阵A、稀疏编码E; |
| 步骤2 重复 |
| 1)通过算法1更新字典矩阵A; |
| 2)通过(35)式更新稀疏编码E; |
| 3)对于每个i,通过求解(13)式更新S的第i行。其中di∈Rn×1,第j个元素为dij=‖xi-xj +β‖ei-ej ; |
| 直到收敛; |
| 步骤3 求得结果。 |
3 实验
我们在2个图像数据集(CMU-PIE数据库和COIL20图像数据库)上进行聚类实验。实验中以聚类准确率(accuracy, ACC)、标准互信息率(normalized mutual info, NMI)2个指标作为评价标准,实验环境为Intel(R) Core(TM) i7-1065G7 1.50 GHz CPU,16 GiB DDR3内存,MATLAB 2019b。
3.1 实验步骤
为了进一步评估所提出方法的性能,我们对GraphSCAN与一些经典算法和最新算法进行了对比实验。
1)k-means:最常用的基于欧式距离的聚类算法[32] 。
2)主成分分析(principal component analysis,PCA):经典的降维方法[33]。
3)SC:经典SC算法 。
4)GraphSC:图正则化的SC[20]。
5)LogSC:最新的基于拉普拉斯图正则化的SC[22]。
实验中所用对比算法的参数已结合原论文进行了调节,使得其性能达到最优。
3.2 图像聚类实验
3.2.1 CMU-PIE数据集上的测试
我们首先在CMU-PIE数据集上进行实验, CMU-PIE人脸数据库包含68个人总共41 368张人脸图像。每个图像的大小为32×32,每个像素256个灰度级,每个图像都由1 024维矢量表示。
我们进行的聚类实验的簇数C范围为4~68。对于除68以外的每个簇,对不同随机选择的簇进行20次测试运行,并通过对20个测试取平均值来获得最终的性能得分。对于每个测试,首先应用比较算法中的每个算法,学习数据的新表示形式,然后在新的表示空间中应用k-means。我们用不同的初始化将k-means在原数据集上重复50次,并记录关于k-means目标函数的最佳结果。PCA投影降维后,维数为64。对于SC、GraphSC、LogSC、GraphSCAN算法,基向量维度设为128。
实验结果如表1所示,本文GraphSCAN算法基本优于其他算法(表中加粗数据)。GraphSCAN的ACC和NMI均值分别为86.28%和94. 41%,明显高于现有优秀算法LogSC在PIE数据集上的表现。同时,基于图的SC算法结果均优于标准SC算法。这说明结合图的SC可以获得更好的性能,且通过自适应邻居获得相似度图的方法比仅使用k -NN进行构造的图算法获得的结果精度更高。由于局部流形结构的学习和稀疏编码是同时进行的,即从编码的结果中自适应地学习内在局部结构,并且重新构造因子以保留数据的精炼局部结构。因此,可以更好探索数据内在局部结构。通过为每个数据点选择自适应和最佳邻居,该方法可以提高一般情况下的聚类性能。
表1 CMU-PIE数据集的聚类结果Tab.1 Clustering results of CMU-PIE data set 单位:% |
| C | ACC | NMI | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k-means | PCA | SC | GraphSC | LogSC | GraphSCAN | k-means | PCA | SC | GraphSC | LogSC | GraphSCAN | ||||||||||
| 4 | 38.64 | 47.23 | 90.21 | 93.56 | 85.08 | 94.32 | 53.46 | 65.83 | 95.85 | 95.45 | 91.49 | 95.31 | |||||||||
| 12 | 32.75 | 32.90 | 90.56 | 91.34 | 84.66 | 92.64 | 50.53 | 65.38 | 94.45 | 94.60 | 93.56 | 94.63 | |||||||||
| 20 | 30.17 | 30.45 | 82.43 | 88.54 | 84.29 | 90.87 | 49.88 | 64.71 | 90.80 | 94.50 | 91.36 | 95.24 | |||||||||
| 28 | 28.43 | 28.78 | 78.00 | 86.79 | 83.94 | 86.82 | 47.84 | 64.26 | 89.50 | 94.28 | 87.47 | 95.43 | |||||||||
| 36 | 28.94 | 28.83 | 71.85 | 82.73 | 83.40 | 83.27 | 46.90 | 63.67 | 86.42 | 94.28 | 87.01 | 94.79 | |||||||||
| 44 | 25.64 | 27.95 | 66.73 | 80.61 | 83.48 | 82.73 | 46.76 | 62.35 | 82.33 | 93.12 | 85.13 | 93.86 | |||||||||
| 52 | 27.62 | 27.65 | 63.89 | 78.17 | 83.27 | 80.97 | 46.23 | 60.09 | 80.00 | 92.33 | 85.07 | 93.12 | |||||||||
| 60 | 25.14 | 27.71 | 61.35 | 78.51 | 82.98 | 78.63 | 43.40 | 48.57 | 76.5 | 92.89 | 83.76 | 92.92 | |||||||||
| 平均值 | 29.67 | 31.44 | 75.63 | 85.03 | 83.89 | 86.28 | 48.13 | 61.86 | 86.98 | 93.93 | 88.11 | 94.41 | |||||||||
注:加粗表明本文算法优于其他算法的数据。 |
3.2.2 COIL20数据集上的测试
我们在COIL20数据集上也进行了实验, COIL20图像库包含20个对象1 440张32×32的灰度图像(每个对象72个图像),每个图像由1 024维向量表示。实验设置与CMU-PIE数据集上的实验基本相同,但限制于数据集大小,此处以2~20的簇数进行20次实验,通过对20个测试取平均值来获得最终的性能得分。对于此数据集,PCA降维后的维数为175;对于SC、GraphSC、GraphSCAN算法,基向量维度设为256。
实验结果如表2所示,GraphSCAN的ACC和NMI均值分别为88.07%和87.63%。与LogSC相比,GraphSCAN的性能略有提升,且二者都优于同样基于图的GraphSC算法。这说明将图优化的概念引入使用图方法的GraphSC中,可以提高原有算法的性能。
表2 COIL20数据集的聚类结果Tab.2 Clustering results of COIL20 data set |
| C | ACC | NMI | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k-means | PCA | SC | GraphSC | LogSC | GraphSCAN | k-means | PCA | SC | GraphSC | LogSC | GraphSCAN | ||||||||||
| 2 | 63.75 | 63.33 | 76.81 | 94.31 | 95.78 | 96.39 | 64.86 | 65.42 | 78.02 | 90.56 | 89.72 | 91.53 | |||||||||
| 4 | 60.97 | 62.22 | 74.79 | 92.86 | 92.62 | 92.64 | 62.78 | 64.03 | 77.71 | 88.06 | 90.81 | 91.18 | |||||||||
| 6 | 60.50 | 60.97 | 72.81 | 90.67 | 90.76 | 90.28 | 60.11 | 61.67 | 77.21 | 88.56 | 84.16 | 90.81 | |||||||||
| 8 | 58.75 | 58.67 | 72.64 | 87.92 | 87.70 | 88.62 | 59.38 | 60.42 | 76.69 | 85.48 | 86.92 | 88.78 | |||||||||
| 10 | 56.88 | 56.67 | 70.39 | 86.17 | 86.68 | 87.66 | 59.03 | 59.31 | 76.01 | 83.06 | 85.13 | 87.28 | |||||||||
| 12 | 56.88 | 56.46 | 69.55 | 85.39 | 86.37 | 86.91 | 58.61 | 59.10 | 76.01 | 83.06 | 83.76 | 86.43 | |||||||||
| 14 | 56.22 | 56.46 | 67.92 | 84.74 | 86.75 | 86.10 | 56.89 | 57.78 | 72.83 | 82.11 | 84.45 | 86.71 | |||||||||
| 16 | 56.22 | 56.46 | 64.86 | 84.27 | 84.00 | 85.35 | 56.89 | 54.03 | 72.08 | 80.81 | 83.40 | 85.28 | |||||||||
| 18 | 55.46 | 56.46 | 64.86 | 83.39 | 83.58 | 84.11 | 54.53 | 54.28 | 71.35 | 78.75 | 86.45 | 85.00 | |||||||||
| 20 | 53.40 | 56.46 | 64.11 | 82.29 | 82.50 | 82.61 | 53.29 | 54.03 | 72.01 | 77.85 | 82.67 | 83.33 | |||||||||
| 平均值 | 57.90 | 58.42 | 69.87 | 87.20 | 87.67 | 88.07 | 58.64 | 59.01 | 74.99 | 83.83 | 85.75 | 87.63 | |||||||||
注:加粗表明最优。 |
结合对PIE数据集进行的聚类实验结果可以看出,通过将自适应拉普拉斯图构建的概念引入带有几何信息编码的稀疏表示中,可以有效提高学习性能。
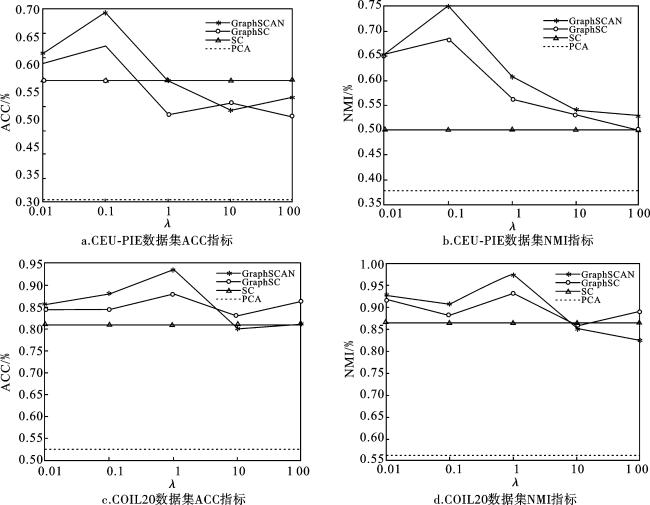
3.3 参数选择实验
考虑到实验数据集包含的数据量,这里选择COIL20以及CEU-PIE 2个数据集及PCA、SC、GraphSC、GraphSCAN 4种算法进行了实验。所有实验均使用ACC、NMI指标作为算法评价标准。为了公平地比较所有方法,所有算法都在不同的参数设置下进行,且在每个参数设置下,均会独立重复实验20次。所有方法的迭代次数都根据经验设置为50,GraphSCAN中α、β两个参数粗略取值为α=λ、β=0.3进行实验(更好的参数调整可以给本文算法带来更优秀的性能)。聚类的数量设置为真实类的数量。
试验结果如图1所示。可以看出,在CEU-PIE数据集上当λ取到0.1时以及在COIL20数据集上当λ取到1时可获得较好的结果,其结果显示GraphSCAN与GraphSC算法取到λ最优值过程中指标变化趋势相差较小。以上结果表明,实际对算法影响较大的部分为SC之前进行的图构造过程。
{kind=link}
{kind=link}
4 结语
为优化GraphSC算法,本文将自适应拉普拉斯图构建的方法引入GraphSC中,提出了自适应图正则化稀疏编码算法GraphSCAN。该算法通过使用自适应方法定义构建合适的局部拉普拉斯图,再使用构建好的图参与SC的运算,图的构建与稀疏编码的运算同时迭代进行。本文在2个图像数据集上进行了实验,并与相关算法进行了比较分析,验证了GraphSCAN的有效性。